Beyond Pixels to Prose: SceneXplain's New Algorithm Breathes Audible Life into Images
Discover the power of SceneXplain's Hearth Algorithm: turning images into captivating narratives. Dive deep into the tech behind it, explore real-world examples, and grasp its potential. Journey beyond pixels to stories at SceneXplain!

Imagine walking through a dimly lit gallery, where walls are adorned with timeless black-and-white photographs. One image, in particular, catches your eye. A soldier hugging his daughter tightly, possibly seeing her for the last time before heading to war. Tears glisten on the child's cheeks, and even though the image stands still, you can almost hear the whispered promises, the choked-back tears, the soft lullaby sung to offer solace.

Now, what if you really could hear that story?

In today's digital age, while short video content has surged, powerful still images often remain trapped in silence. SceneXplain's Hearth algorithm breaks these barriers, giving a voice to the voiceless. It's not merely about observing a moment but immersing oneself in its rich auditory tapestry. With Hearth, every picture has a story to tell and a song to sing, encapsulating the essence of short videos from a static frame.
Why Did SceneXplain Create the Hearth Algorithm?
As our digital ecosystem swiftly gravitates towards compact and impactful narratives, the potency of short, immersive content cannot be overlooked. These snippets of visual and auditory tales have become the preferred consumption mode for global audiences. But amidst this video-driven narrative, there remains a vast reservoir of untapped potential: the silent world of static images. These encompass art, history, personal memories, and countless unspoken tales. Recognizing this gap, SceneXplain birthed the Hearth algorithm. It's more than just an enhancement; it's a revolution—bestowing a voice upon the silent and ensuring every image shares its intrinsic story.
Which Industries Can Benefit from SceneXplain's Hearth?
The impact and versatility of SceneXplain's Hearth ripple across numerous sectors:
- Film & Entertainment: Envision a world where directors and scriptwriters utilize Hearth to add depth to their storyboarded visuals, melding sight and sound to create a richer pre-production canvas.
- Marketing & Advertising: In today's bustling market, capturing attention within moments is paramount. SceneXplain's Hearth equips brands with the tools to morph static campaign images into gripping auditory narratives, fostering deeper connections with audiences.
- Education: The future of teaching is dynamic. With SceneXplain's Hearth, educators can transition from traditional visuals to interactive auditory experiences, be it through historical recounts or intricate scientific processes.
- Content Creation: Digital storytellers of the modern age have a new ally. With Hearth, they can augment their visual tales with resonant audio narratives, enhancing engagement and solidifying their space in the vast digital landscape.
Decoding the Hearth Algorithm: The Nexus of Visual Understanding and Auditory Storytelling
The Hearth Algorithm's design embodies a meticulous blend of parallelized tasks and sequential steps, ensuring optimal performance while achieving nuanced narrative generation. Our architecture diagram above provides a holistic view of the entire process. Here’s a breakdown of how the magic happens:

1. Scene Understanding: Building on a Legacy of Excellence
Our journey to advanced scene understanding isn't new. In a previous blog post, we discussed the advent of AI-powered multimodal understanding, where we highlighted the role of image captioning algorithms in decoding complex visual information. These tools had matured beyond crafting basic captions; they could analyze scenes and provide enriched descriptions. One standout contender in this domain was SceneXplain.

SceneXplain, our state-of-the-art image captioning solution, was already heralded for its exceptional abilities to leverage large language models (LLMs), producing sophisticated, contextual, and intricately detailed textual descriptions for diverse visual content. As we introduce the Hearth Algorithm, it is essential to recognize that this isn't a mere continuation of SceneXplain's legacy, but a significant step forward.
In the current algorithm, upon receiving an image, SceneXplain simultaneously discerns the primary subjects and contexts, as well as extracting underlying emotions and intricate details from the visuals. These parallel processes use evolved computer vision techniques combined with our legacy understanding methods to grasp the image's essence and nuances.
def scene_understanding(image_input):
subjects_and_contexts = get_subject_and_object(image_input)
emotions_and_details = detect_emotions_and_details(image_input)
return subjects_and_contexts, emotions_and_details
2. Leveraging Large Language Models (LLMs)
Once the scene is well-understood, Hearth taps into the prowess of advanced LLMs. Using clues from the image, the LLM simultaneously conceptualizes the characters and the setting while deriving the mood and dynamics of the scene.
def llm_processing(subjects_and_contexts, emotions_and_details):
characters_and_setting = derive_characters_and_setting(subjects_and_contexts)
mood_and_dynamics = define_mood_and_dynamics(emotions_and_details)
return characters_and_setting, mood_and_dynamics
3. Narrative Construction: Storyline and Dialogues
With the foundation set, the algorithm crafts a riveting storyline and corresponding dialogues. This phase synthesizes the mood, characters, and settings to spin a tale fitting the selected genre.
def narrative_construction(characters_and_setting, mood_and_dynamics, genre):
storyline = generate_storyline(characters_and_setting, mood_and_dynamics, genre)
dialogues = create_dialogues(characters_and_setting, mood_and_dynamics, genre)
return storyline, dialogues
4. Voiceover Emotion Embedding (SSML)
Narratives gain a deeper dimension with emotional voiceovers. The Hearth algorithm assigns appropriate emotions to the voiceovers, ensuring the tale is not just told, but felt.
def ssml_voiceover_embedding(storyline, dialogues):
ssml_output = generate_emotional_ssml(storyline, dialogues)
return ssml_output
5. Narrative Review and Audio Generation
The story undergoes a review to ensure logical coherence and relevance to the original scene. Once approved, the narrative is sent to Azure's Text-to-Speech service, transforming the text into an immersive audio experience.
def audio_generation(ssml_output):
reviewed_story = review_narrative(ssml_output)
audio_output = azure_tts(reviewed_story)
return audio_output
With the above steps, SceneXplain's Hearth Algorithm demonstrates its ability to convert a mere image into an emotionally charged, audibly narrated story, all while preserving the integrity and essence of the original visual.
Examples: Seeing the Hearth Algorithm in Action
While an intricate algorithm and tech-talk can illustrate the prowess of Hearth, the true test lies in real-world application. Let's dive into four handpicked examples to truly appreciate the intricacy and brilliance of the stories our algorithm crafts:
The stories above encapsulate the heart of Hearth Algorithm. Not only do they spin a rich tale with unexpected twists and turns, but they also bring the scene to life through vivid character dialogues. Each character, endowed with distinct characteristics and tones, reflects the depth of understanding derived from the image description.
Known Limitations
In our pursuit of elevating the capabilities of SceneXplain through the Hearth Algorithm, it's vital to be transparent about its current challenges, all while focusing on the nuances of our unique tech stack. Here's an introspective look:
- Hallucination Issues: The concept of models "hallucinating" isn't unfamiliar in deep learning. Specifically, when using algorithms that deeply integrate with LLMs, such as our SceneXplain model, there's a possibility of generating details not present in the source image. This emanates from LLMs being optimized for vast and diverse datasets, sometimes leading them to infer beyond the provided data. However, the field is continuously evolving. By refining SceneXplain's training mechanisms and incorporating more targeted fine-tuning, we aspire to curb such over-generalizations.
- Speed Constraints: Precision comes at a price: time. The Hearth Algorithm, in its essence, utilizes LLMs, image captioning frameworks like BLIP2 and multimodal embeddings like CLIP. The richness of the narratives it produces is tied to the computational depth it delves into. But as with any AI challenge, it paves the way for innovation. Techniques such as model pruning, tailored for SceneXplain, could optimize its execution speed, enabling faster story derivations without sacrificing their nuance.
 jina-ai
jina-ai- Over-Ethical Content Production: It's been observed that the Hearth Algorithm, possibly influenced by the ethically-filtered data it was trained on, leans heavily towards generating highly politically correct content. This has inadvertently made it challenging for the model to craft genres like horror, even when explicitly prompted. This isn't a drawback of the ethical stance but more of a fine-tuning nuance. As we progress, integrating more diverse fine-tuning processes, centered around specific genres while maintaining ethical bounds, can help SceneXplain strike a more balanced narrative approach.
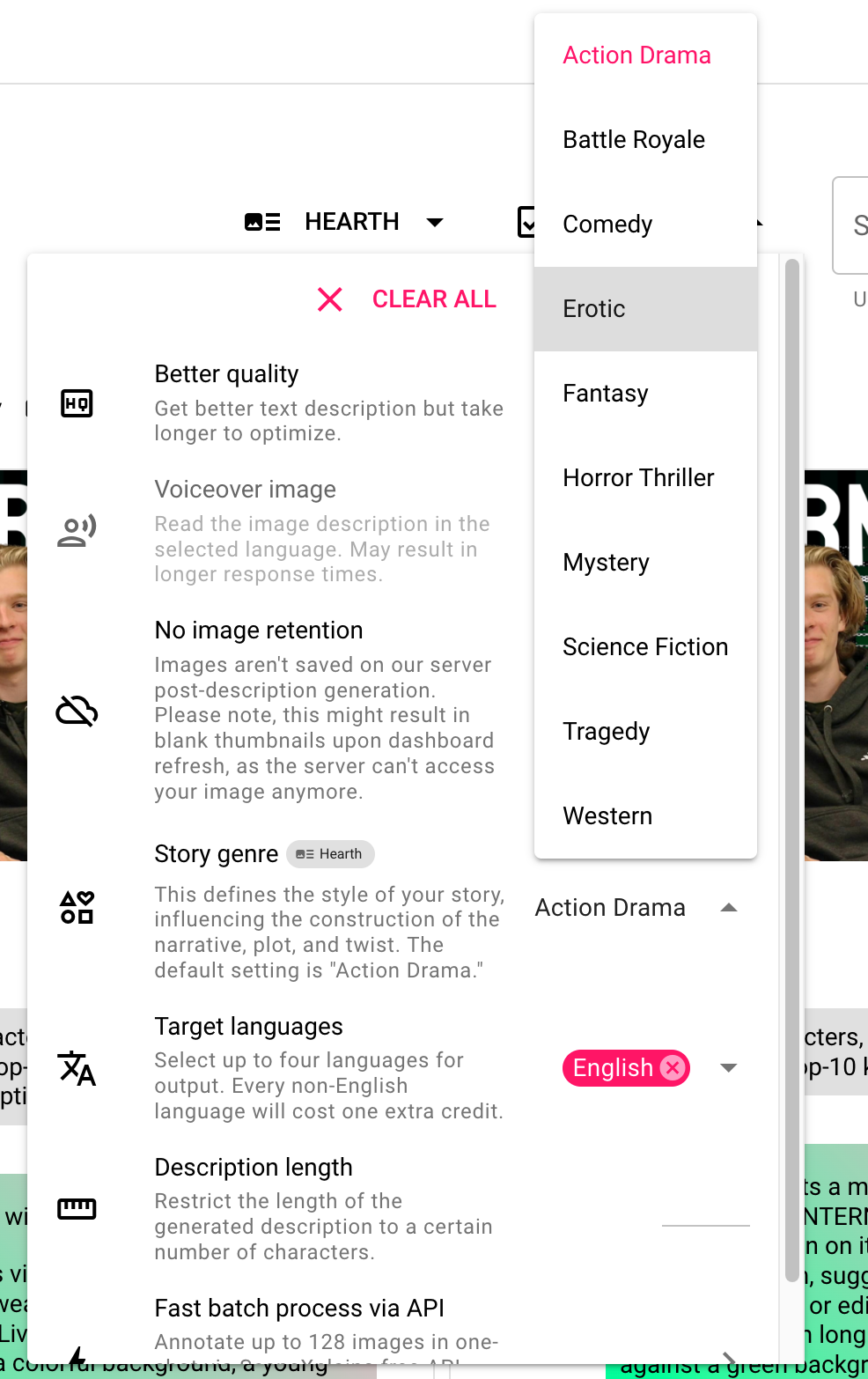
At SceneXplain, our commitment is steadfast: refine, innovate, and evolve. With the brilliant minds in the community and our dedicated team, these challenges merely represent the next set of puzzles to solve in our AI journey.
Conclusion
The intersection of large language models and image captioning technologies represents an exciting frontier in AI. With SceneXplain's Hearth Algorithm, we've embarked on a journey to bridge the gap between visual information and its narrative counterpart. While our current achievements set benchmarks in image storytelling, our journey is ongoing, underscored by continuous learning, adaptation, and innovation.
The possibilities of this technology extend far beyond mere image captioning. Imagine content creators gaining inspiration from a single image, educators drawing stories to elucidate complex concepts, or businesses creating engaging multimedia content seamlessly. The horizon is vast, and with every challenge we overcome, we move a step closer to making these visions a reality.
We invite you to experience the future of image storytelling firsthand. Dive into the rich narratives, witness the intricate character developments, and immerse yourself in the plots crafted meticulously by the Hearth Algorithm. Visit https://scenex.jina.ai to explore, and together, let's shape the future narrative of visual content. Your feedback and experiences are invaluable in guiding our next strides. Join us on this captivating journey.