Discover the Latest in Embeddings at EMNLP 2023 In-Person BoF Session
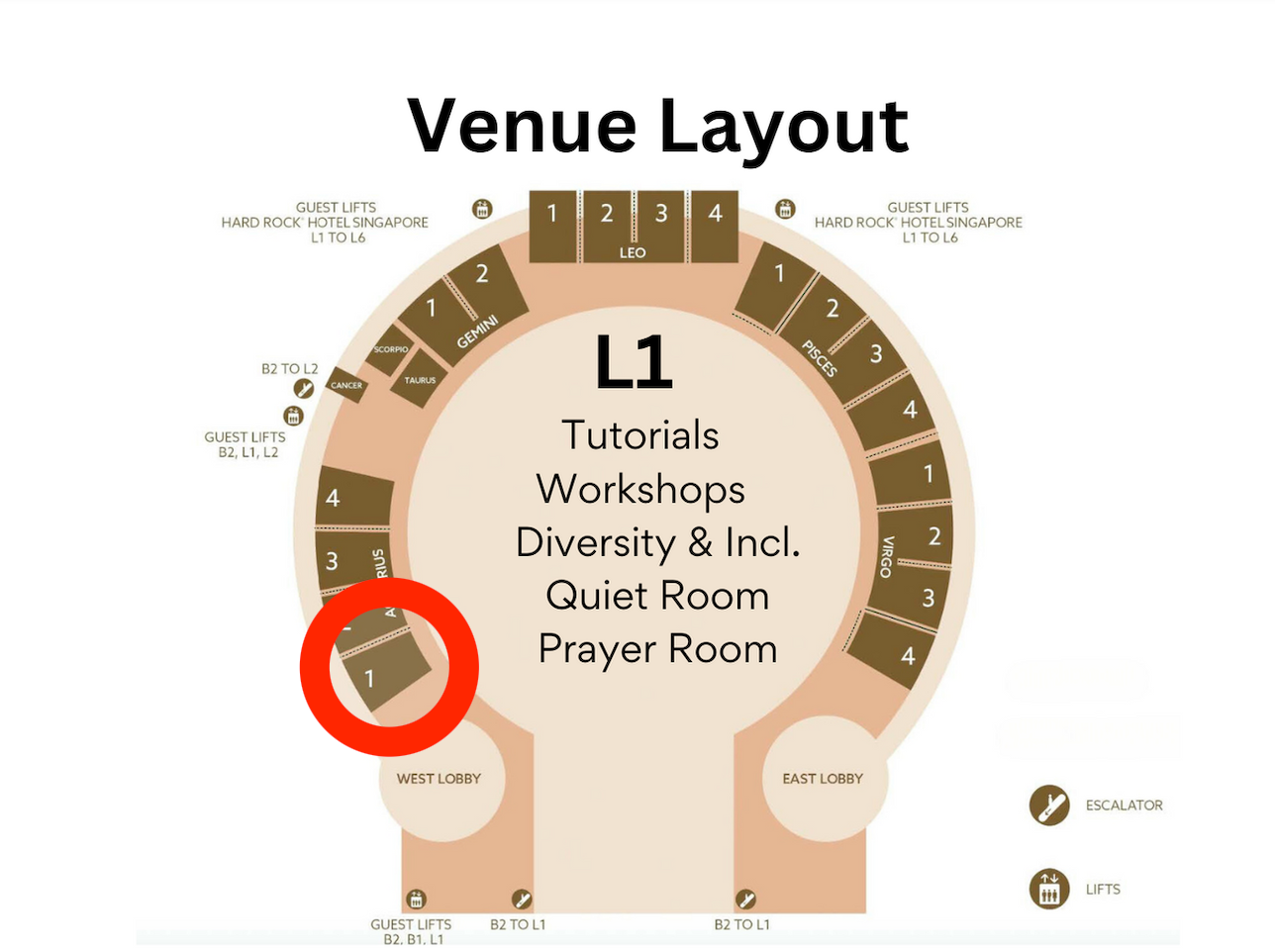
Mark your calendars for an immersive BoF session on Embeddings at EMNLP 2023. Join us on December 9th from 11:00 AM to 12:30 PM, Singapore time, in the 'Aquarius 1' room for a deep dive into the latest embeddings.

At the EMNLP2023 BoF (birds of a feather) session, we're set to explore the frontiers of embeddings. While recent developments like jina-embeddings-v2 have made significant strides, they also open the door to new questions and challenges in the field. This 1.5-hour session is a platform to tackle these emerging issues in embeddings. You can register via the Google Form below:


Event Details
Date & Time: December 9th, 11:00 AM - 12:30 PM Singapore time, at 'Aquarius 1' room.
Format: In-person, with an interactive and collaborative approach.
Registration: Google Form
Themes and Highlights
This BoF session features a set of thought-provoking presentations, panel discussions, and lightning talks, reflecting the ongoing evolution in the field:
Multimodal Embeddings:
- "How can multimodal embeddings be advanced to handle the context and nuance in diverse data types?"
- "What are the challenges in scaling multimodal embeddings for complex applications like personalized AI assistants?"
- "In what ways can vector databases be integrated with multimodal embeddings to enhance their contextual understanding?"
Long Context Embeddings:
- "How can long context embeddings be optimized to reduce hallucination in LLMs?"
- "What are the computational and practical challenges in scaling embeddings to handle longer contexts efficiently?"
- "Beyond the 8K limit, what novel approaches can push the boundaries of context length in embeddings?"
Multi- and Bilingual Embeddings:
- "What are the key hurdles in achieving high accuracy and cultural sensitivity in multi- and bilingual embeddings?"
- "How can embeddings tackle the challenge of representing less popular factual knowledge accurately?"
- "In the development of bilingual embeddings, how can we address the lack of in-house NLP expertise and high development costs?"
Embeddings for Low-Resource Languages:
- "What innovative strategies can be adopted to significantly boost support for low-resource languages in embeddings?"
- "How can we incentivize the development of embeddings for less popular languages amidst high costs and complexity?"
- "What role can transfer learning and fine-tuning play in enhancing embeddings for low-resource languages?"
RAG (Retrieval Augmented Generation) Applications:
- "How can RAG applications overcome the limitations of vector databases in understanding complex, nuanced meanings?"
- "What are the potentials and challenges of using RAG in AI assistants for deep personalization and context understanding?"
- "Considering the current state of RAG, what are the ethical considerations and potential risks in its widespread adoption?"
For more information, visit EMNLP2023 Program.
We are looking forward to seeing you in person in Singapore next week!