8K Token-Length Bilingual Embeddings Break Language Barriers in Chinese and English
The first bilingual Chinese-English embedding model with 8192 token-length.



jina-embeddings-v3 has been released on Sept. 18, 2024. The best <1B multilingual embedding model.
Following the remarkable success of the previous Embeddings V2, we are thrilled to announce the launch of our latest Chinese/English bilingual text embedding model: jina-embeddings-v2-base-zh. This new model inherits the exceptional 8K token length of Jina Embeddings V2, now with robust support for both Chinese and English languages.
jina-embeddings-v2-base-zh stands out for its exceptional quality and performance, achieved through rigorous and balanced pre-training with high-quality bilingual data. This approach ensures a significant reduction in bias, often seen in models trained with unbalanced multilingual data.
Highlights
- Bilingual Model: This model encodes texts in both English and Chinese, allowing the use of either language as the query or target document. Texts with equivalent meanings in these languages are mapped to the same embedding space, forming the basis for numerous multilingual applications.
- Extended 8K Token-Length: Our model is capable of processing significantly large text passages, a feature that exceeds the capabilities of most other open-source models.
- Compact and Efficient: With a size of 322MB (161 million parameters) and output dimensions of 768, our model is designed for high performance on standard computer hardware without GPU, enhancing its accessibility.
Leading Performance on C-MTEB
In the Chinese MTEB leaderboard, our Jina Embeddings v2, supporting both Chinese and English, stands out as one of the top models under 0.5GB. What sets it apart is its impressive 8K token-length capability, a unique feature in its category.
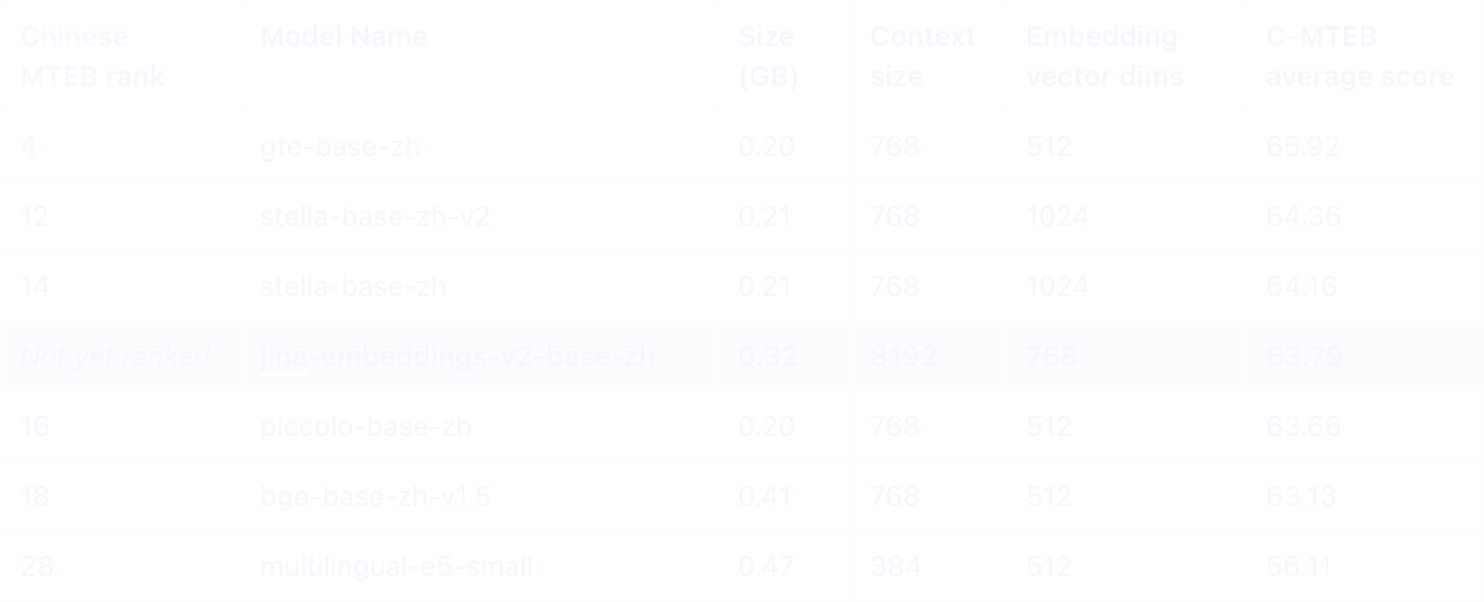
Among Chinese models of similar size, only the E5 Multilingual model and our jina-embeddings-v2-base-zh offer support for English, enabling effective cross-language applications. Notably, Jina demonstrates significantly superior performance in all categories involving the Chinese language.

While both models have an 8K token context size, jina-embeddings-v2-base-zh significantly outperforms OpenAI's text-embedding-ada-002, especially in tasks involving the Chinese language.

Empowering Chinese Enterprises for Global Expansion
Our Chinese-English embedding model is a powerful tool for Chinese companies looking to 'go global' (出海). It seamlessly processes Chinese texts, providing high-quality embeddings that effortlessly integrate with leading vector databases, search systems, RAG applications.
jina-embeddings-v2-base-zh is especially beneficial for developing AI applications tailored to Chinese-English contexts, crucial for businesses expanding internationally. Here are some specific use cases:
- Document Analysis and Management: It can analyze and manage a vast array of documents, aiding in international legal and business transactions.
- AI-Powered Search Applications: Enhances search functions in multilingual environments, making it easier for global users to find relevant information in Chinese and English.
- Retrieval-Augmented Chatbots and Question-Answering: Builds efficient, bilingual customer service bots, improving interactions with customers worldwide.
- Natural Language Processing Applications: This includes sentiment analysis for understanding global market trends, topic modeling for international marketing strategies, and text classification for managing global communication.
- Recommender Systems: Tailors product and content recommendations for diverse global audiences, using insights drawn from Chinese and English data.
By leveraging this model, Chinese enterprises can effectively bridge the language gap in their AI applications, enhancing their global competitiveness and market reach.
Get Started with jina-embeddings-v2-base-zh via API
Begin integrating our model into your workflow immediately through the Embeddings API. Simply visit the our Embeddings portal, get your free access key or top up an existing key, and then choose jina-embeddings-v2-base-zh from the dropdown menu. It's that easy to get started!

What's Next: Expanding Language Support and AWS Sagemaker Integration
jina-embeddings-v2-base-zh will soon be available via AWS Sagemaker and Hugging Face.



At Jina AI, our commitment to being a leader in affordable and accessible embedding technology for a global audience is unwavering. We're actively developing additional multilingual offerings, focusing on major European and other international languages, to broaden our reach. Stay tuned for these exciting updates, including integration with AWS SageMaker, as we continue to expand our capabilities.
A Special Thanks to Our Early Testers
We're immensely grateful to the select members of our Chinese user community who tested the preview version (jina-embeddings-v2-base-zh-preview). Their insightful feedback was crucial in enhancing the official release's performance for this release. If you have any observations or suggestions regarding the quality of our models, we warmly invite you to join our Discord server and share your thoughts with us. Your input is invaluable in our continuous improvement journey.


Improved Score Distribution vs. jina-embeddings-v2-base-zh-preview
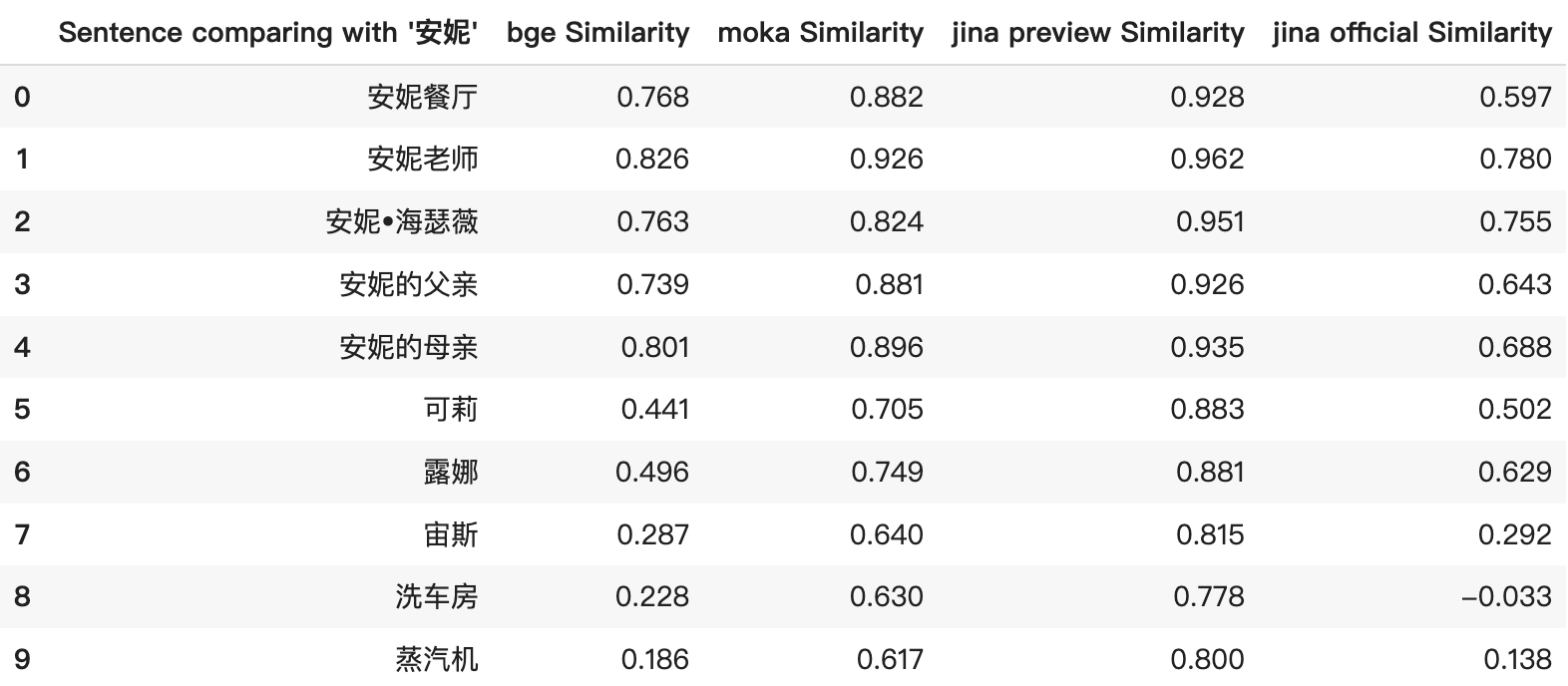
jina-embeddings-v2-base-zh-preview suffered from inflated similarity scores, leading to high cosine scores even for unrelated items. This was particularly evident in the top-5 results from the screenshot below. The similarity scores were consistently high and did not accurately reflect the true relationship between items. For example, the comparison between “安妮” and “蒸汽机” received misleadingly high similarity scores.
In the official release, we have fine-tuned the model to produce more distinct and logical similarity scores, ensuring a more accurate representation of the relationships between items. For example, the revised scoring now presents a broader range, offering a clearer insight into the relative similarity among items.
Additionally, Jina Embeddings now uniquely stands as the only open-source embedding model supporting 8192 tokens. This feature highlights its capability in processing a wide variety of data types, from extensive documents to brief phrases, or even individual words/names such as “安妮” vs “露娜”.
中英双语8K向量大模型新鲜出炉,企业出海必备!
自从我们的 Embeddings V2 获得各界好评后,今日,我们推出了全新的中英双语文本向量大模型:jina-embeddings-v2-base-zh。此模型不仅继承了 V2 的全部优势,能够处理长达八千词元的文本,更能流畅应对中英文双语内容,为跨语种的应用插上了翅膀。
jina-embeddings-v2-base-zh 之所以表现卓越,全赖优质的双语数据集,经过我们严格且平衡的 预训练、一阶微调和二阶微调。这种三步走的训练范式不仅泛化了模型的双语能力,更有效的降低了模型偏见,解决了多语言模型时常遭遇到的“不患寡而患不均”的问题。
模型特色一览
特色 1:双语无缝对接
jina-embeddings-v2-base-zh 模型能够流畅处理中英文本,无论是作为搜索查询还是目标文档。中英文本中意义相近的内容都会被映射到相同的向量空间,为多语言应用奠定了坚实基础。
特色 2:8k Token 超长文本支持
我们的模型支持长达 8K Token 的文本处理,这在开源向量模型中独树一帜,在处理更长的文本段落上提供了显著优势。
特色 3:高效紧凑的模型结构
jina-embeddings-v2-base-zh 模型以 322MB 的轻巧体积(包含 1.61 亿参数),输出维度为 768,能够在普通计算机硬件上高效运行,无需依赖 GPU,极大地提升了其实用性和便捷性。
模型性能卓越
在 CMTEB 排行榜的激烈竞争中,我们的 Jina Embeddings v2 模型在 0.5GB 以下模型类别中脱颖而出,它不仅支持中英文本,而且能够处理高达 8K Token 的文本,这一能力在同类模型中实属罕见。
在同等体积的支持中文的模型中,Multilingual E5 和我们的 jina-embeddings-v2-base-zh 是唯二能够处理英文的模型,这使得跨语言应用成为可能。
目前,全球范围内,仅有 OpenAI 的闭源模型 text-embedding-ada-002 和 Jina Embeddings 能够支持 8k Token 的长文本输入。而在处理中文任务方面,Jina Embeddings 显示出了显著的性能优势。
助力中国企业拓展全球业务
我们的中英双语向量模型 jina-embeddings-v2-base-zh 是中国企业进军国际市场的强大伙伴。它能够无缝处理中英双语文本,并提供高质量的文本向量表示,还能轻松集成到先进的向量数据库、搜索系统以及 RAG 应用里。
这款模型特别适合打造适应中英双语场景的 AI 应用,对于追求全球化发展的企业来说,其价值不可估量。以下是几个实际应用案例:
- 文档分析与管理:分析和管理海量文档,助力国际法律和商务交易的顺利进行。
- AI 驱动搜索应用:在多语言环境中提升搜索性能,帮助全球用户轻松找到中英文相关信息。
- 增强检索的聊天机器人和问答系统:打造高效的双语客服机器人,优化与全球客户的沟通体验。
- 自然语言处理应用:涵盖全球市场趋势分析、国际市场策略的主题建模,以及全球通讯管理的文本分类。
- 推荐系统:利用中英数据洞察,为全球多元化受众提供个性化的产品和内容推荐。
借助这款模型,中国企业能够在 AI 应用领域跨越语言的鸿沟,在全球市场的角逐中占据先机。
轻松上手 jina-embeddings-v2-base-zh
想要快速将我们的双语向量模型融入您的工作流程?只需几个简单步骤:访问 https://jina.ai/embeddings,领取您的免费 API 密钥或更新现有密钥,然后在下拉菜单中选择 jina-embeddings-v2-base-zh,您的模型即刻准备就绪,等待您的探索和使用!
展望未来:多语言支持与 AWS SageMaker 深度融合
jina-embeddings-v2-base-zh 即将上线 AWS SageMaker 和 HuggingFace,为用户提供更加便捷的服务。
我们正积极推进多语言向量模型,特别是欧洲及其他国际语言的支持,来满足全球用户的多样化需求。敬请期待我们即将推出的激动人心的更新,包括与 AWS SageMaker 的深度集成,我们将持续深化和拓宽服务范围。
致谢:感谢早期测试者的宝贵贡献
我们衷心感谢参与 jina-embeddings-v2-base-zh-preview 测试的中国社区朋友们。你们的宝贵意见对优化我们的模型起到了重要作用。如果您在使用过程中有任何建议或想法,欢迎随时向我们提出。您的每一条反馈都是我们持续进步的动力。
正式版解决了预览版的分数膨胀问题
与之前的预览版模型相比,正式版模型提供了更加分散且合理的相似度评分。在预览版的测试中,我们的模型曾显示出相似度评分的通货膨胀现象,即便是完全不相关的词汇,比如‘安妮’和‘蒸汽机’,也会获得很高的余弦相似度。而在正式版中,我们优化了模型,以确保相似度评分更为合理,从而更准确地反映内容之间的关系。
此外,Jina Embeddings 现在支持高达 8192 Token 的文本处理,无论是长篇大论还是简短语句,甚至是单个词汇或名字(如“安妮”与“露娜”的比较),都能展现出其处理各种类型数据的强大能力。这一改进不仅提升了模型的准确性,也增强了其在处理多样化数据时的灵活性和实用性。