A Tale of Two Worlds: EMNLP 2023 at Sentosa
Just back from EMNLP2023 and my mind's still reeling! Witnessed NLP's seismic shift firsthand through daring papers and provocative posters that are challenging everything we thought we knew. Check out my take on the conference's boldest ideas.


The sun blazed down on the glistening sidewalks of Sentosa, a symphony of laughter and chatter filling the air. Tourists, decked in their holiday best, meandered through the vibrantmaze of Universal Studios, their faces alight with the joy of a day out in this fantasy land. The click of cameras capturing moments against the backdrop of thrilling rides and colorful parades was omnipresent. Nearby, the enticing aromas of international cuisines wafted through the air, luring guests to indulge in a culinary adventure.

In stark contrast, just a stone's throw away, nestled in the heart of this revelry, was the Resorts World Convention Centre. Here, the atmosphere was charged with a different kind of excitement. The halls buzzed not with the sound of holiday-making, but with the fervor of intellectual discourse. Young researchers and seasoned academics, their conference badges swaying gently with each step, engaged in animated discussions about the latest in NLP.

As I walked into this place, the difference was clear. On one side, there was the loud and happy noise of a holiday resort, full of life and excitement. On the other side, there was a serious and busy atmosphere where people talked about NLP , LLMs, ChatGPT, prompting, and Google's new Gemini model. It was like a movie scene – where learning and fun came together in a surprising way.
In this blog, I'll share some observations of EMNLP 2023 and some of the most interesting papers and posters we discovered at the conference.
EMNLP: 2022 to 2023 Shifts
Attending EMNLP 2022 in Abu Dhabi and now looking back at EMNLP 2023, I've observed significant shifts in research focus and conference dynamics. These changes, driven by the swift advancements in AI, paint a vivid picture of our adaptive and forward-looking community. Below, I share a comparison of the two conferences, highlighting how our priorities and discussions have transformed in just a year.
| EMNLP | 2022 | 2023 |
|---|---|---|
| Main Research Focus | Diverse range of NLP methods, with emphasis on traditional approaches. | Strong focus on Large Language Models (LLMs) and prompting techniques. |
| Research Trends | Interest in a wide array of topics, but no standout groundbreaking papers. | Shift towards LLM interpretability, ethics, agents, and multimodal reasoning. |
| Conference Atmosphere | A bit peculiar and pessimistic due to the release of ChatGPT and its implications on traditional NLP methods. | More confidence and adaptability among researchers in embracing new trends. |
| Research Diversity | Still exploring traditional methods like topic modeling, n-grams smoothing, and Bayesian methods (as seen in COLING 2022). | Rapid adaptation to newer approaches, moving away from older methods. |
| Relevance of Presented Work | Consistent with contemporary research trends at the time. | Fast-paced AI development made some empirical methods and results feel outdated by the time of the conference. |
| Conference Engagement | Enjoyment derived more from personal conversations and interactions than from paper presentations. | Increased focus on personal communication, with more time spent at poster sessions than listening to oral presentations. |
Paper Highlights from EMNLP 2023
At EMNLP 2023, several intriguing papers caught my attention, each addressing different aspects of NLP and pushing the boundaries of what's possible in this field. Let me share some of the highlights from these papers and my thoughts on them.
Hybrid Inverted Index Is a Robust Accelerator for Dense Retrieval
Text embeddings have become very popular for information retrieval tasks. However, performing an exact embedding vector search requires one to calculate similarities between the embedding representation of the query and the embedding of each document. This becomes very slow for large datasets and leads to latencies that are not acceptable for real-world search applications. Therefore, many applications use approximated nearest neighbor search techniques to speed up the search system, whereby many of these techniques rely on vector quantization algorithms that learn an index of clusters based on the data distribution.
In addition, hybrid search has become popular which combines embedding-based search with traditional BM25-based search techniques. Usually, BM25 and embedding search are performed completely independently in hybrid search settings and only the result sets are combined.

This paper proposed a method to train a joined index of two parts: a cluster selector and a term selector. The cluster selector performs a vector quantization to assign texts into buckets of nearby clusters and the term selector determines the most representative terms of a document BM25 can be used to assign it into buckets associated with those terms, however, this is not trainable and can therefore not adjust to the training data. Alternatively, one can determine the most representative terms in a document with a BERT model with an MLP hat which is applied on each token to determine a score. In this way the term selector becomes trainable. Then the cluster centroids and the BERT model are trained together by using the KL divergence loss with the embedding model as a teacher to obtain a distribution of similarity values. The results in the paper show that this method can retrieve more relevant documents in the same amount of time as standard ANN techniques like HNSW and IVF-PQ implementations.
Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
This paper investigates techniques to utilize LLMs for re-ranking documents. Re-ranking is usually performed in a search system after a first retrieval step to re-order the retrieved documents, e.g., to select the most relevant ones among them. Commonly used models are finetuned transformer models which are called cross encoders. Those receive as input a pair composed of a query and a document candidate and return a relevance score. Besides, more traditional learning-to-rank models like LambdaMart are also popular, especially in cases where the ranking is not only done based on semantic relevance itself.
Observing the strong NLP capabilities of LLMs, the authors of this paper wanted to investigate whether Models like GPT4 can be used to rank documents better. However, the limitation of those closed API-based models is usually that probability outputs are not accessible. Accordingly, the paper investigates techniques that rely only on prompting and the generated output text for re-ranking. The technique they propose inserts the documents together with an ID in the prompt and instructs the LLM to output a sequence of IDs with respect to the relevancy of the documents. In cases where the whole set of documents is too long to fit into the prompt, they apply a sliding window approach, where re-ranking is first performed on the documents with the lowest retrieval score obtained from the first-stage retriever. Then the most relevant documents according to the output are presented together with the documents in the next window of retrieval candidates and so on.
Since GPT-4 is too expensive and too slow for using it in a real-world setting, the authors propose distilling its ranking capabilities into a transformer-based cross-encoder model. The results show that even a comparably small model (440M parameters) distilled with this technique can outperform much larger state-of-the-art re-ranking models.
Large Language Models Can Self-Improve
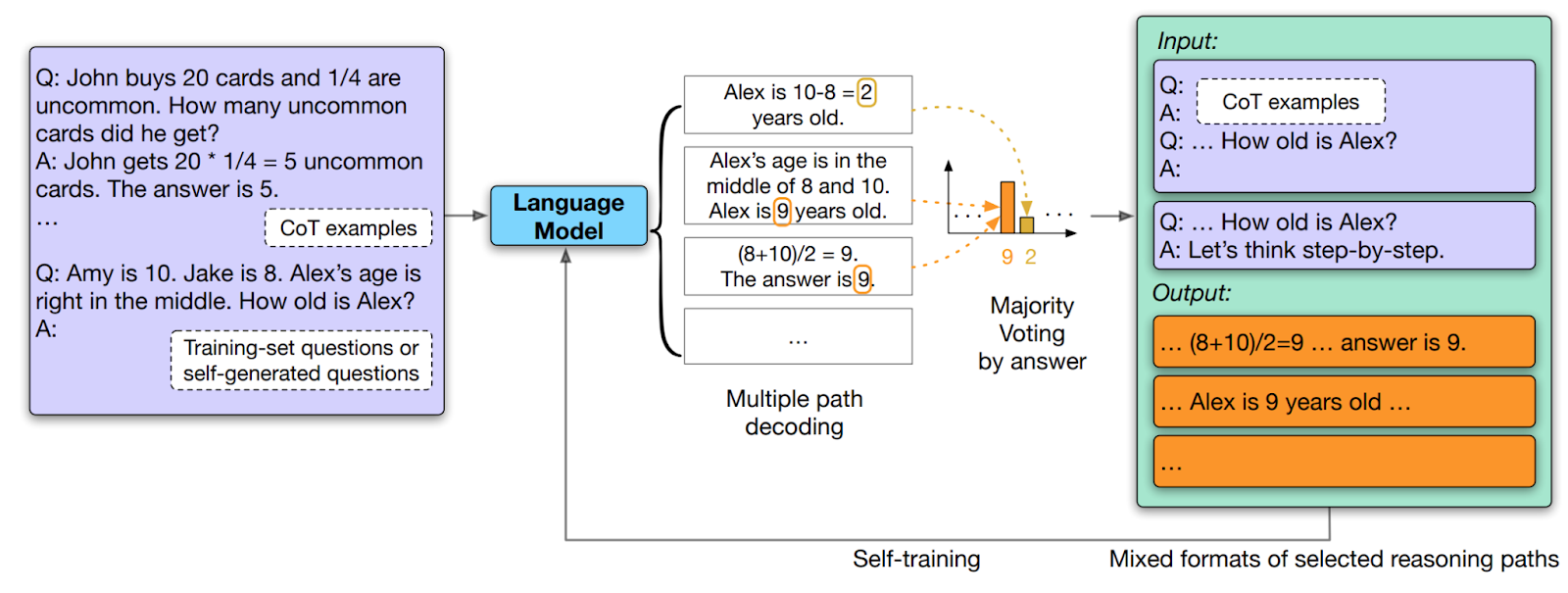
For many tasks, LLMs achieve already good results in zero-shot settings. However, to improve their performance on specific tasks (beyond zero-shot) common techniques still utilize a lot of training data to fine-tune them. To reduce the amount of training data needed, this paper presents a technique that uses the LLM to “self-improve”. The main idea behind this approach is to augment existing training datasets by using data generated with the LLM itself.
This is achieved by using a dataset with only questions and without answers. First, a chain of thoughts (CoT) method is used to generate for each question a couple of different reasoning paths and answers by using a temperature greater than zero to make the generative text non-deterministic. By determining the answer with the highest frequency the probability of the answer being correct can be increased. The paper also shows that LLMs can be used to effectively estimate the confidence of an answer by investigating the consistency of the answer. If a high percentage of the answers is equal, this answer also has a high probability being correct. These most frequent answers and the corresponding reasoning paths can then be used to construct additional prompts for constructing additional training data. However, the authors propose not only to use those reasoning paths and answers but also to add examples in different formats, e.g., presenting the question without any reasoning path and using the question together with some generic instruction like “Let’s think step by step”. Finally, this enhanced training dataset can be used to fine-tune the LLM on the specific task. In their evaluation the authors show this technique is effective to fine-tune LLMs with minimal training data but also that it generalizes well, as it improves the result on out-of-domain datasets.
Adapting Language Models to Compress Contexts
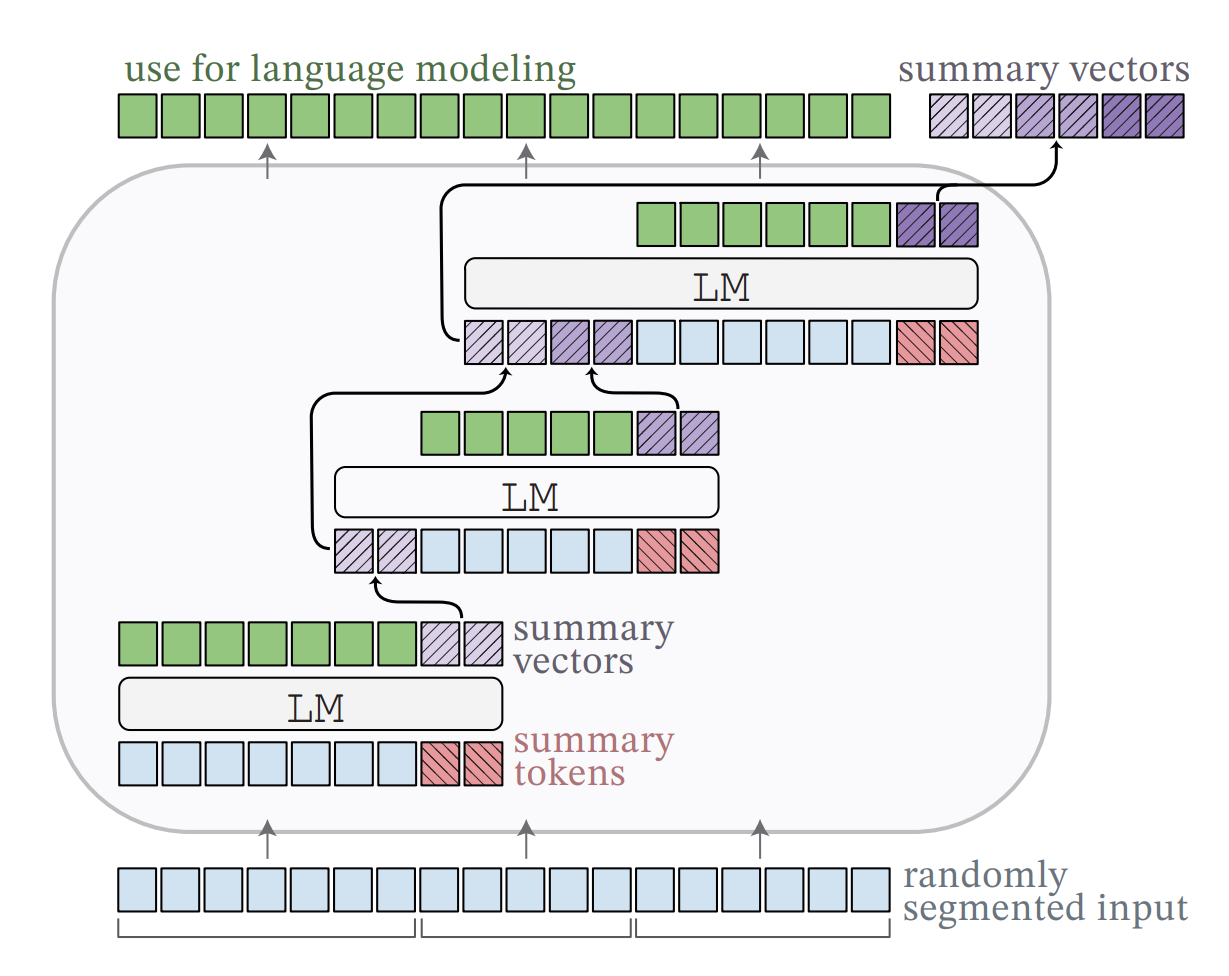
Language models are usually constrained by limited context length. While there are various techniques like AliBi to construct language models that can handle larger context lengths, those techniques do not help in cases where you want to use an existing model that has only a very limited context length.
Instead, this paper addresses this problem by introducing a new method that allows one to fine-tune an exciting language model to apply it to longer context lengths. To achieve this, the model's vocabulary is extended by a fixed number of summary tokens, which are supposed to tell the model to summarize the content of the other tokens in the respective embeddings. During inference, the text input is segmented into shorter text sequences which are extended with the summary tokens and prepended with the output summary vectors of the previously processed segments. To fine-tune the model to handle long sequences, the model is trained on a next-token prediction task. Thereby, the model should make use of the information encoded in the summary embeddings of the previous segments. Notably, the segment length is varied during the training and the backpropagation is done for one document as a whole. In other words, the model is first applied to all sequences in the afore-described scheme before starting the backpropagation. The technique is evaluated by the authors on OPT models of various sizes and the 7-B-Llama-2 model. Besides standard language modeling tasks, the authors also show that the models can be effectively used to solve in-context-learning classification tasks with longer prompts or used for re-ranking. Here the re-ranking follows a language modeling approach in which the passages are re-ranked based on the language model’s likelihood to generate the question from the given passage.

Poster Highlights from EMNLP 2023
At EMNLP 2023, alongside the compelling paper presentations, the poster sessions were a hub of vibrant discussion and exchange. Here's a rundown of some standout posters I came across, each offering a unique glimpse into the ongoing research and development within the field of NLP.
Can Retriever-Augmented Language Models Reason?
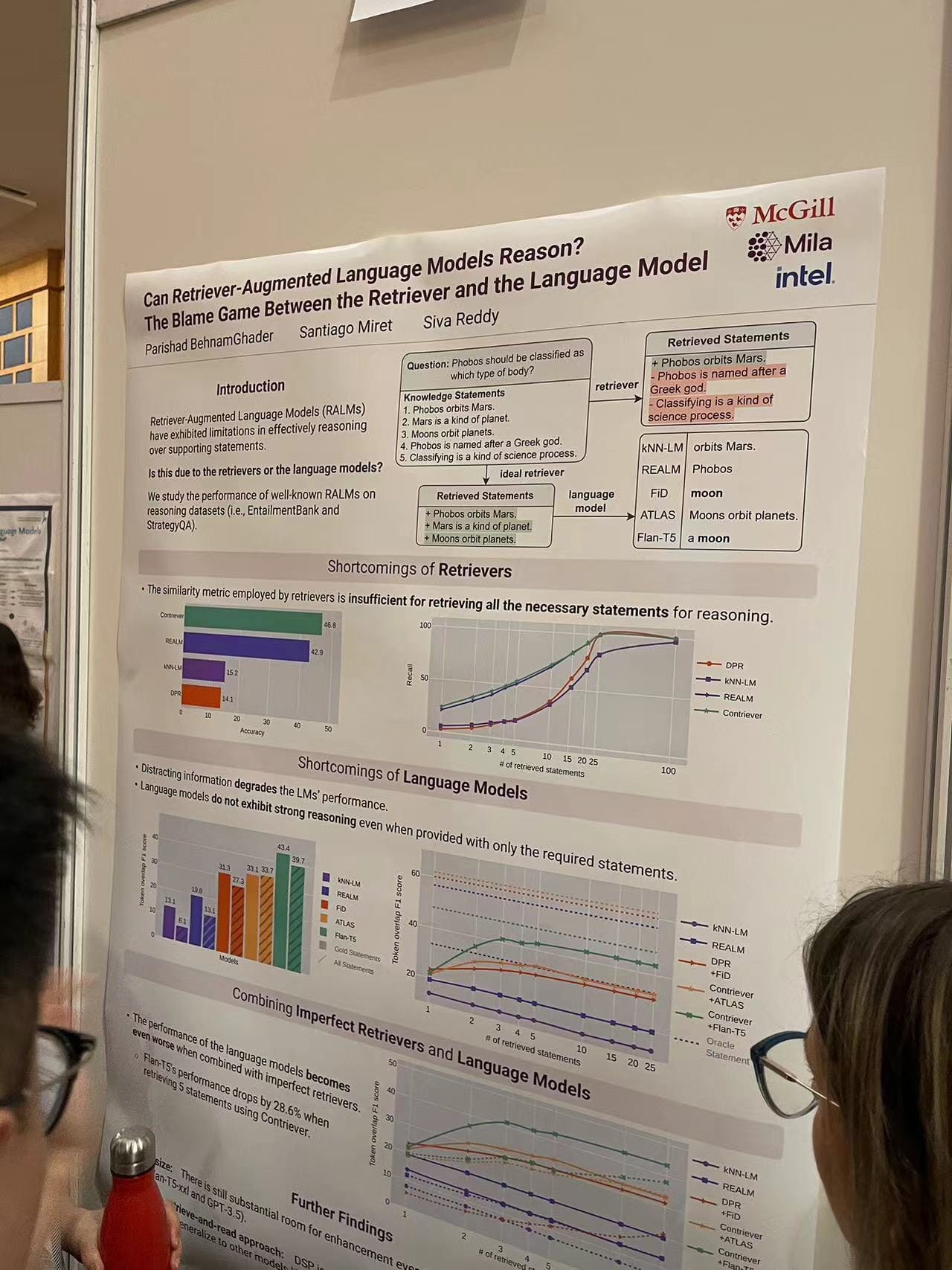
A poster from McGill University examined whether Retriever-Augmented Language Models (RALMs) can effectively reason by balancing the capabilities of both the retriever and the language model. The research highlighted the potential shortcomings of retrievers in sourcing all necessary statements for reasoning, and how language models might falter in reasoning even when provided with the required statements. It was a deep dive into improving the interactive components of language models.
Contrastive Learning-based Sentence Encoders
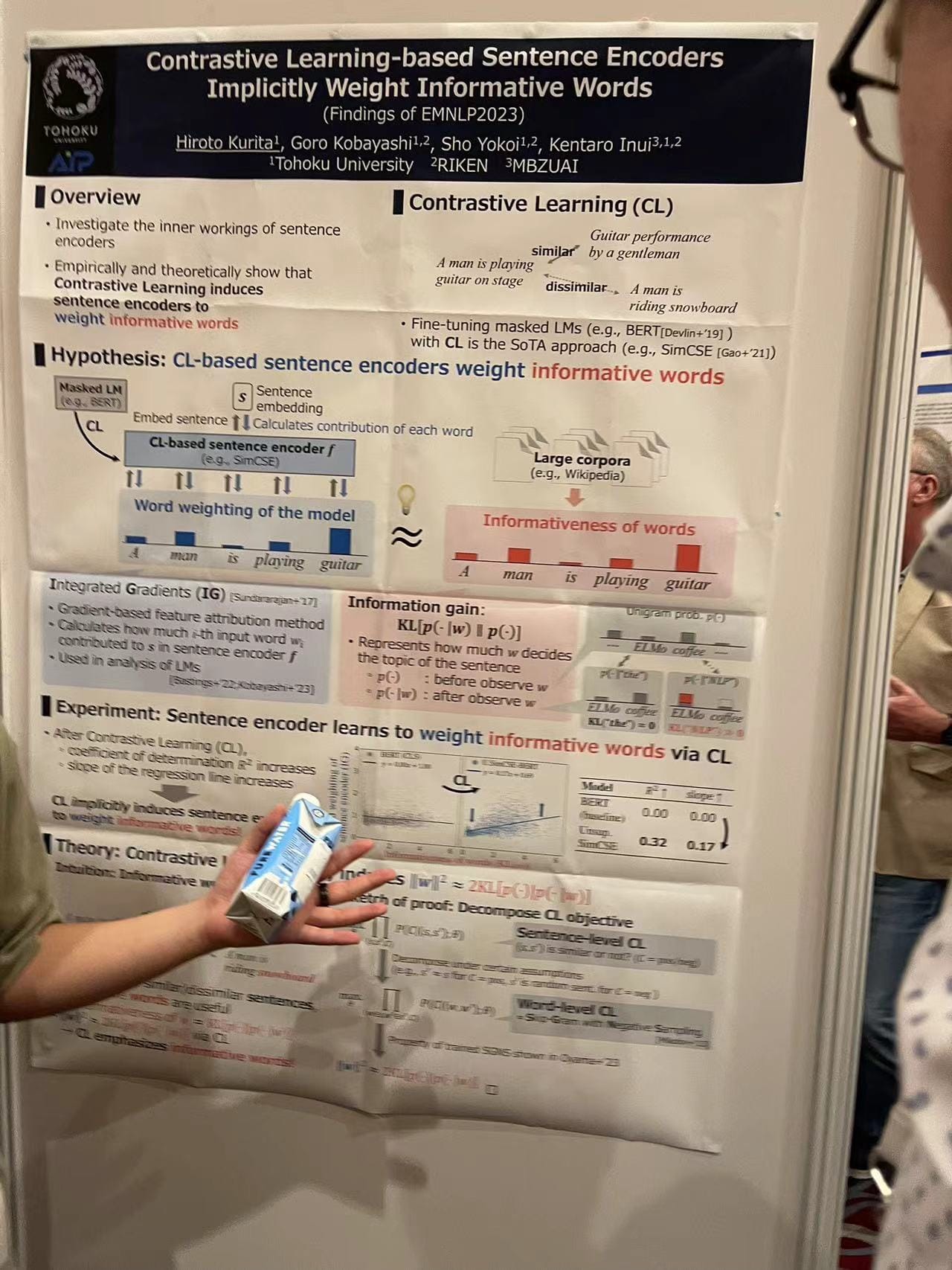
Researchers from Tohoku University presented findings on how Contrastive Learning (CL) can induce sentence encoders to implicitly weight informative words, enhancing the model's understanding and processing of language. This approach could refine the way sentence encoders prioritize and process key elements in text, making them more efficient and effective.
Investigating Semantic Subspaces of Transformer Sentence Embeddings
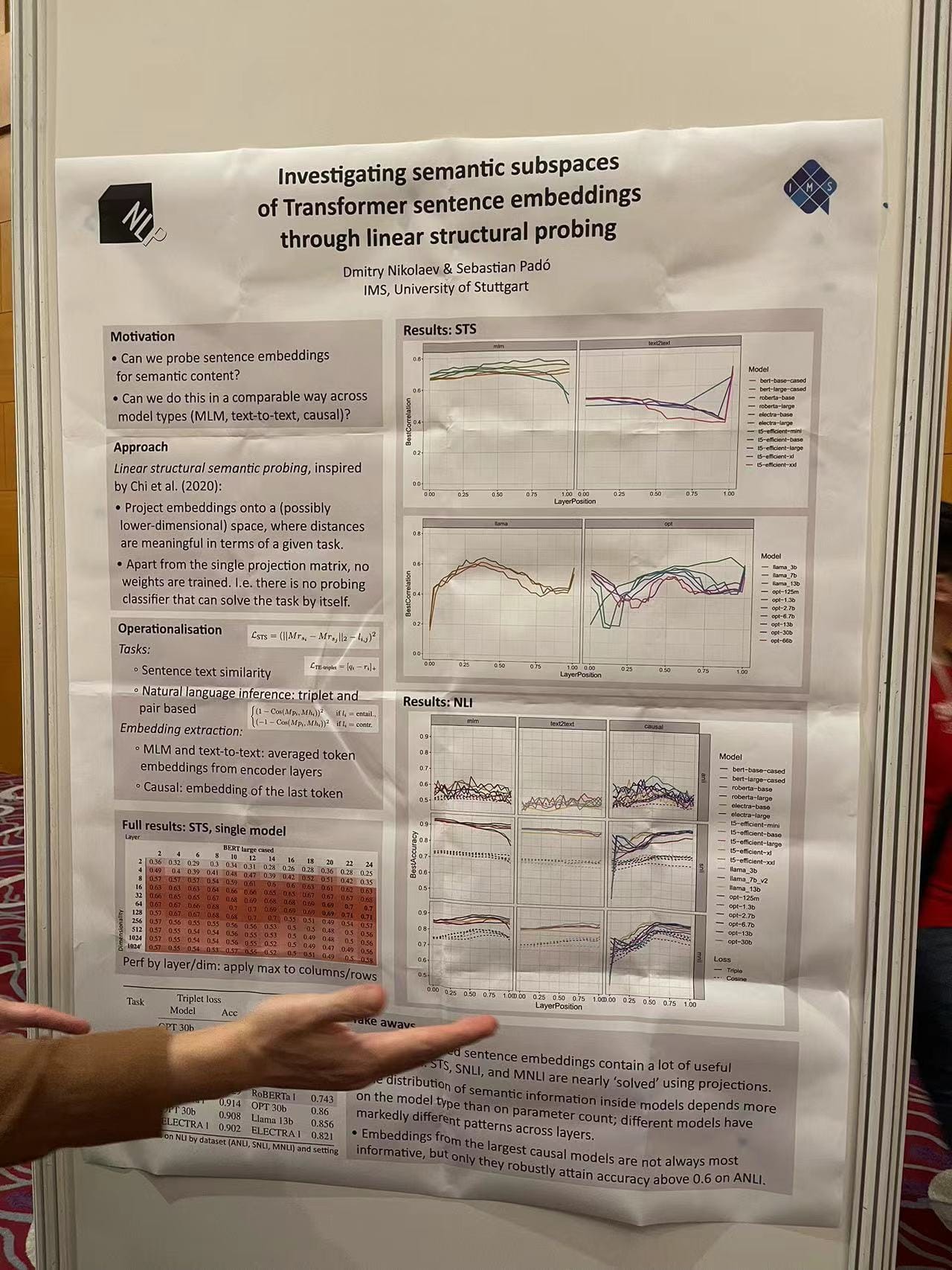
A team from the University of Stuttgart showcased their work on probing the semantic subspaces of transformer sentence embeddings. By employing linear structural probing, they aimed to understand how different layers of a transformer contribute to semantic content processing, offering insights into the inner workings of sentence embeddings.
Can Pre-trained Vision and Language Model Answer Visual Information-Seeking Questions?
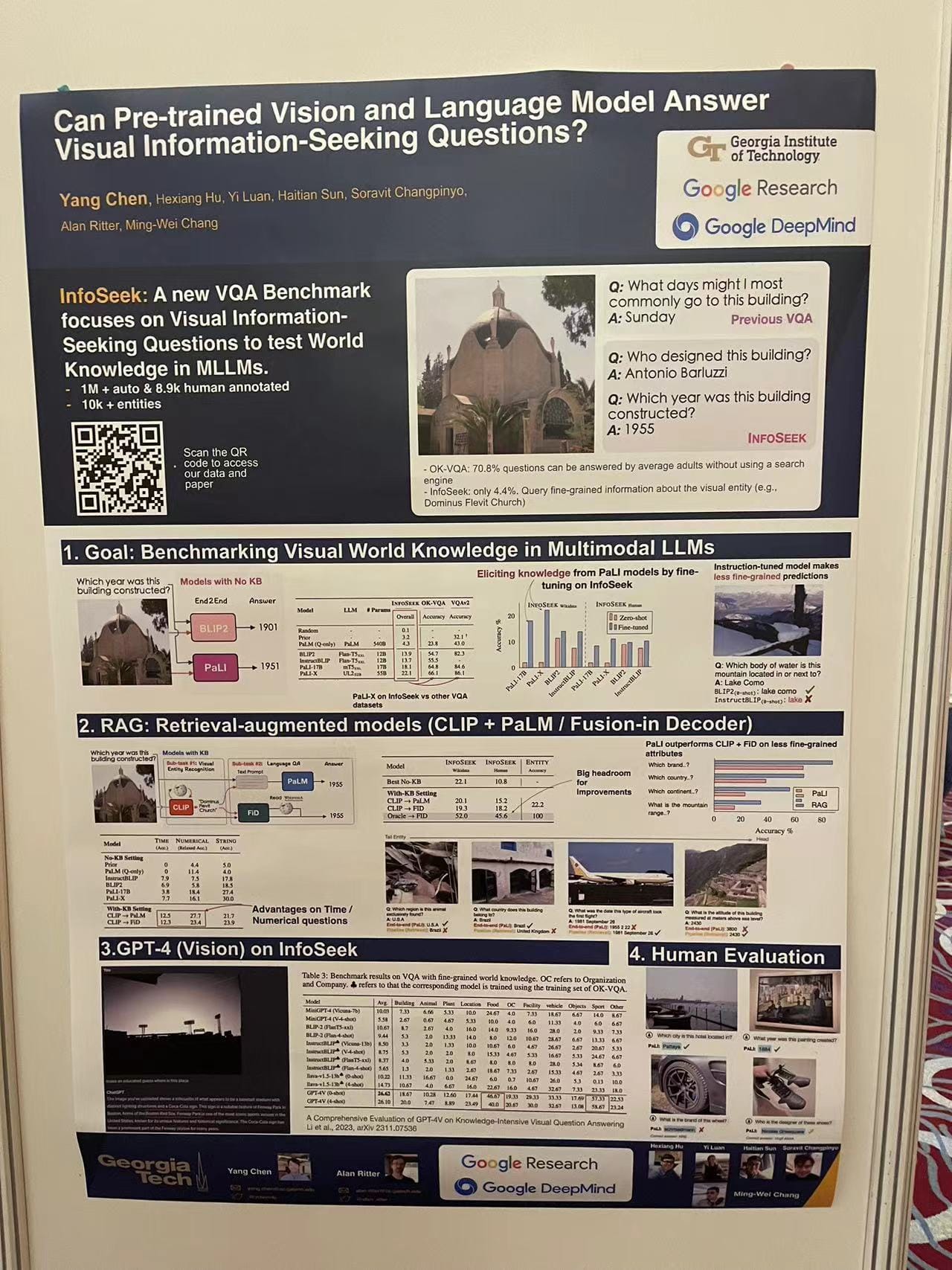
An intriguing poster by researchers from the Georgia Institute of Technology, Google Research, and Google DeepMind introduced a benchmark for testing the world knowledge in multimodal Large Language Models (LLMs) through Visual Information-Seeking Questions. The research focused on the capabilities of retrieval-augmented models and GPT-4 in answering questions that require visual understanding, pushing the envelope on multimodal AI.
To Split or Not to Split: Composing Compounds in Contextual Vector Spaces
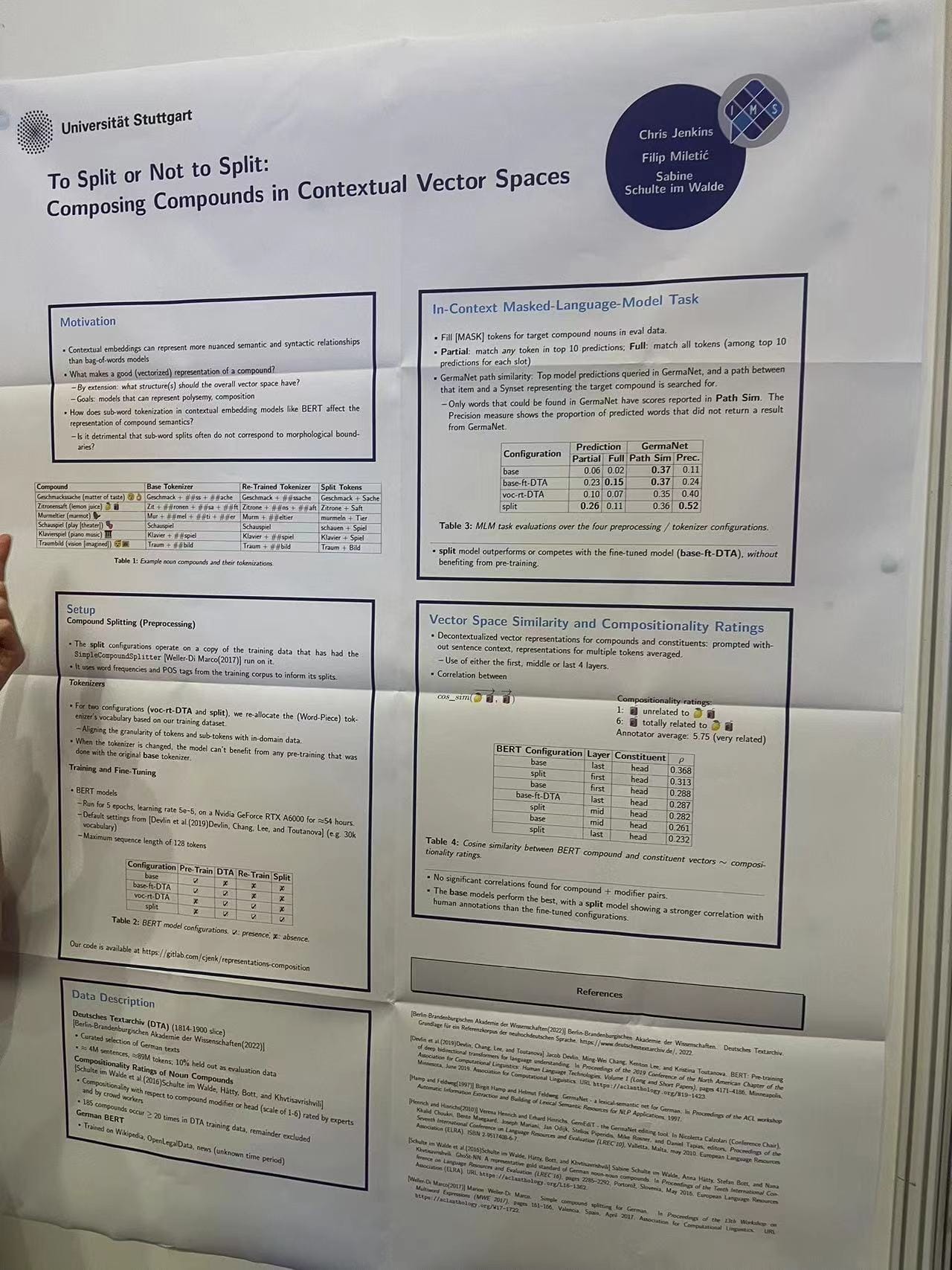
From the University of Stuttgart, a study delved into whether splitting compounds in contextual vector spaces is beneficial for the model's performance. The research explored the impact of compounds on semantic representation and processing, contributing to our understanding of compositional semantics in language models.
Subspace Chronicles: How Linguistic Information Emerges, Shifts, and Interacts during Language Model Training
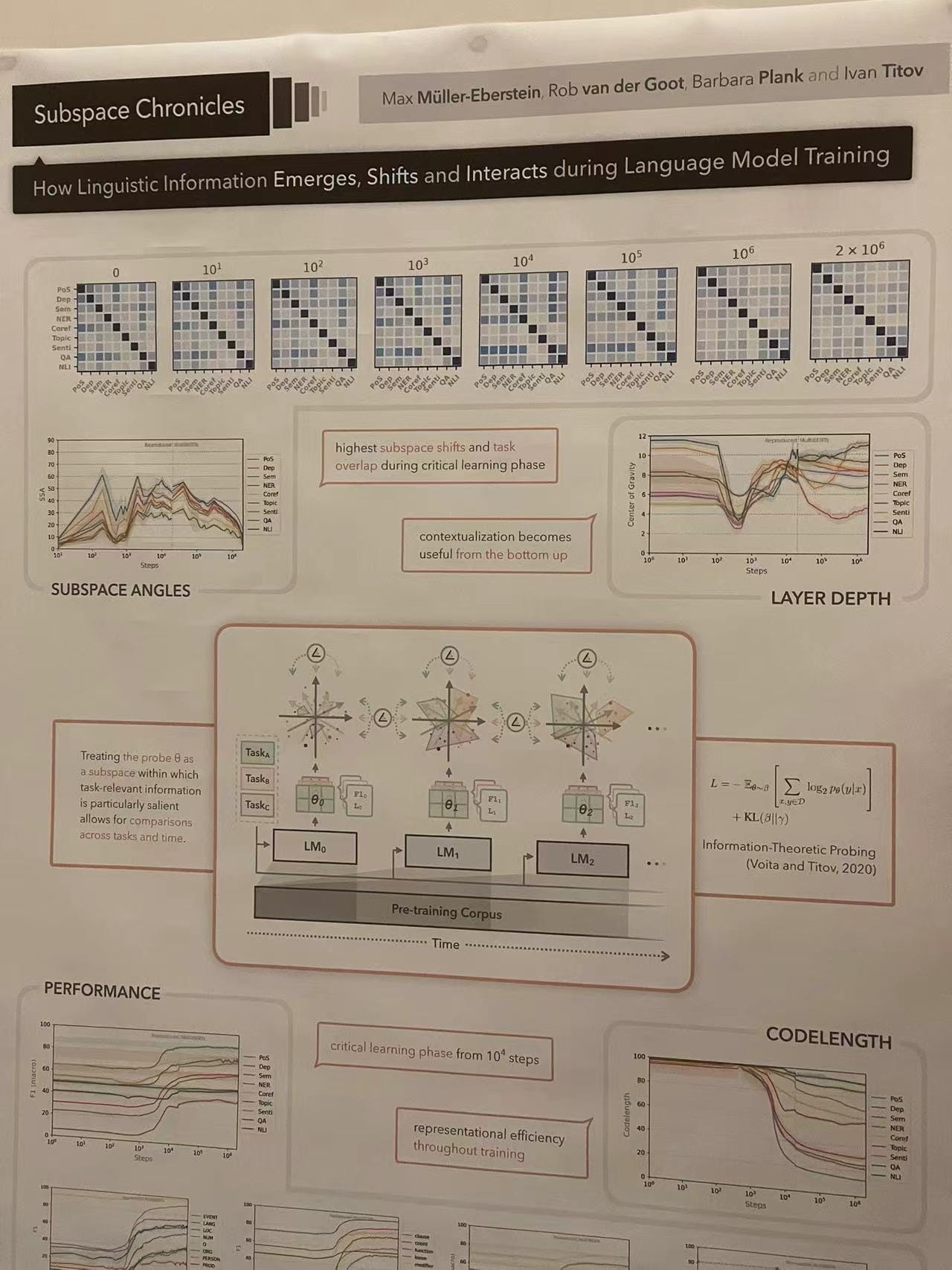
This poster detailed an exploration into the dynamics of linguistic information as it emerges and evolves during the training of language models. It's a fascinating look at the underpinnings of language model training and the critical learning phases that define their capabilities.
Theory of Mind for Multi-Agent Collaboration via Large Language Models
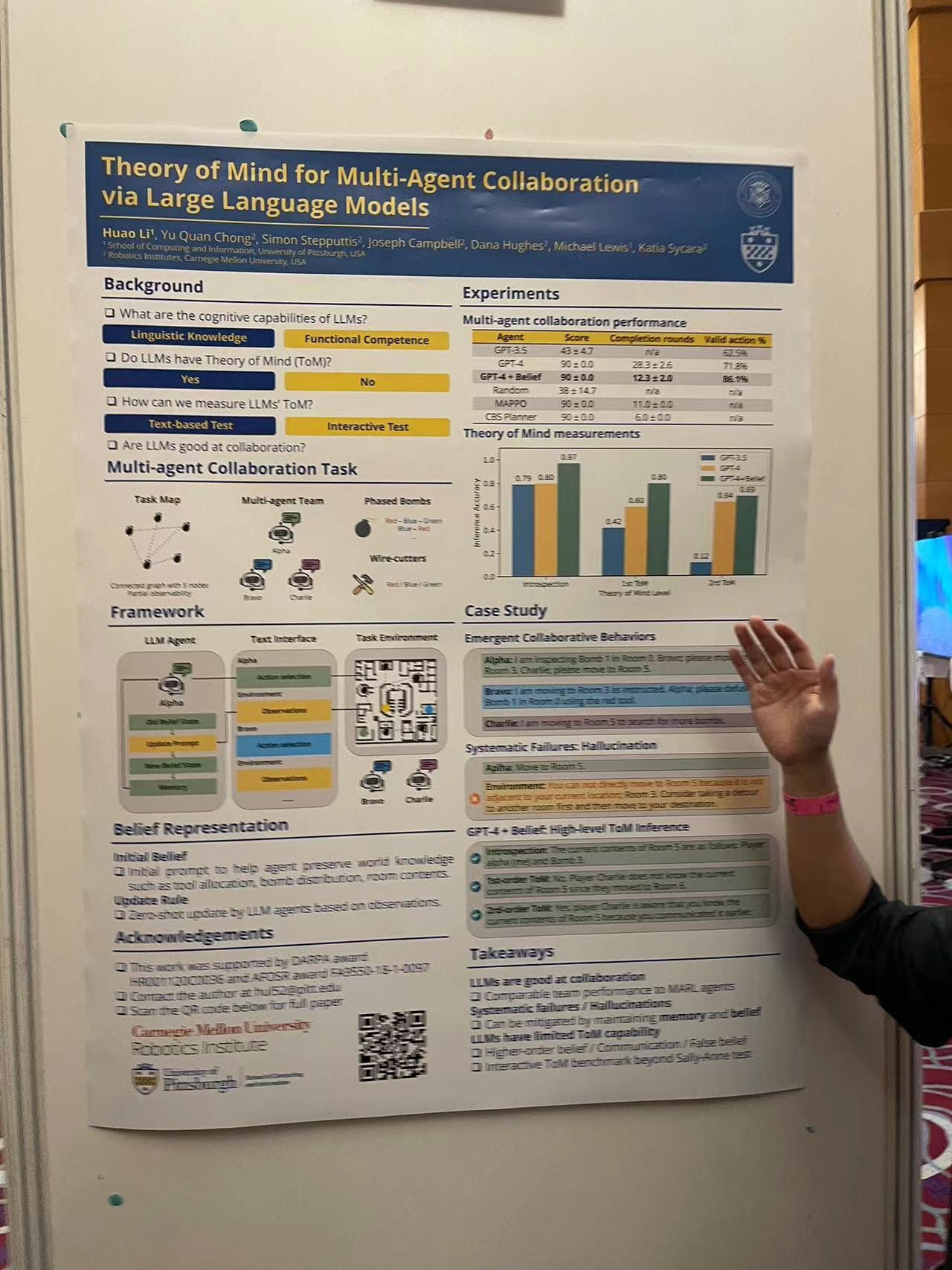
Lastly, a poster outlined research on the Theory of Mind in Large Language Models and their application in multi-agent collaboration tasks. It's an exciting foray into the cognitive capabilities of LMs and their potential in collaborative environments.
Embeddings Roundtable: A Birds of a Feather at EMNLP 2023
During EMNLP 2023, we hosted a Birds of a Feather (BoF) session on embeddings that turned into a rich tapestry of insights and discussions. With a crowd of over 80 attendees, the session was an electrifying blend of sharp minds and cutting-edge topics.
Lightning Talks and Panel Discussion
The BoF session featured lightning talks by renowned researchers like Huiqiang, Hassan, Hwiyeol, Mattia, and Yang Chen. Each speaker brought a unique perspective to the table, sharing their latest findings in embedding research within NLP. The talks sparked an energizing dialogue that transitioned into a thought-provoking panel discussion.




The panel, graced by Sebastian Ruder, Nicola Cancedda, Chia Ying Lee, Michael Günther, and Han Xiao, delved deep into the intricacies of embedding technologies. They covered a breadth of topics, from the evolution of embeddings to their future in a world increasingly dominated by Generative AI and Large Language Models (LLMs).

Key Takeaways from the Panel
- Diverse Perspectives on Embeddings:
The panelists introduced themselves and their work with various embeddings, discussing the common threads and divergences they've observed. They emphasized the nuanced differences in how embeddings behave depending on their design and application contexts. - The Relevance of Embeddings Amidst Generative AI:
With 2023's spotlight on LLMs, the panelists reflected on the enduring importance of embeddings. They highlighted that despite the LLM trend, embeddings retain a crucial role in understanding and processing language at a more granular level. - Context Length in Embeddings vs. LLMs:
A curious observation was the disparity in context length expansion between LLMs and embedding models. The panelists shed light on the technical and practical constraints that currently limit the context window in embedding models. - Search and Generation:
Addressing the assertion that 'search is an overfitted generation, and generation is an underfitted search,' the panelists shared mixed views, sparking a lively debate on the interplay between search functions and generative capabilities. - Future of RAG and Agent Models:
Looking towards EMNLP 2024, the conversation turned to the prospective challenges and developments in Retrieval Augmented Generation (RAG) and agent models. The panelists hinted at their vision for the future integration of embeddings within these applications, recognizing the pivotal role they will continue to play.


Summary
Wrapping up EMNLP 2023, I'm buzzing with ideas and energized by the community's shared passion for pushing the boundaries of NLP. Our Embeddings BoF session was a hit – the engagement and insights made it a highlight for me.
Looking to get hands-on with the future of embeddings? We are hiring! We're all about diving deep into long-context, multilingual, and multimodal embeddings. So, if you're up for the challenge, check out the open roles here and maybe I'll see you at our Berlin, Shenzhen, or Beijing office.

Can't wait to see what we'll cook up by EMNLP 2024 in Miami. Until then, keep innovating, keep questioning, and let's keep the conversations going!