AIR-Bench: Better Metrics for Better Search Foundation
AIR-Bench is a new approach to AI metrics that uses generative AI to make more realistic and flexible benchmarks. With AIR-Bench, you can create your own benchmarks for your own domain, and know that benchmarks data hasn't leaked into model training data.


Late at night, a police officer finds a drunk man crawling around on his hands and knees under a streetlight. The drunk man tells the officer he’s looking for his wallet. When the officer asks if he’s sure this is where he dropped the wallet, the man replies that he thinks he more likely dropped it across the street. Then why are you looking over here? the befuddled officer asks. Because the light’s better here, explains the drunk man.
David H. Friedman, Why Scientific Studies Are So Often Wrong: The Streetlight Effect, Discover magazine, Dec. 2010
Benchmarks are a core component of modern machine learning practices and have been for some time, but they have a very serious problem: We can’t tell if our benchmarks measure anything useful.
This is a big problem, and this article will introduce part of a solution: The AIR-Bench. This joint project with the Beijing Academy of Artificial Intelligence is a novel approach to AI metrics designed to improve the quality and usefulness of our benchmarks.


The Streetlight Effect
Scientific and operational research places a lot of emphasis on measurements, but measurements aren’t a simple thing. In a health study, you might want to know if some drug or treatment made recipients healthier, longer lived, or improved their condition in some way. But health and improved life quality are difficult things to measure directly, and it can take decades to find out if a treatment extended someone’s life.
So researchers use proxies. In a health study, that might be something like physical strength, reduced pain, lowered blood pressure, or some other variable that you can easily measure. One of the problems with health research is that the proxy may not really be indicative of the better health outcome you want a drug or treatment to have.
A measurement is a proxy for something useful that matters to you. You may not be able to measure that thing, so you measure something else, something you can measure, that you have reasons to believe correlates with the useful thing you really care about.
Focusing on measurement was a major development of 20th century operational research and it’s had some profound and positive effects. Total Quality Management, a set of doctrines credited with Japan’s rise to economic dominance in the 1980s, is almost completely about constant measurement of proxy variables and optimizing practices on that basis.
But a focus on measurement poses some known, big problems:
- A measurement may stop being a good proxy when you make decisions based on it.
- There are often ways to inflate a measure that don’t improve anything, leading to the possibility of cheating or believing you are making progress by doing things that aren’t helping.
Some people believe most medical research may be just wrong in part because of this problem. The disconnect between things you can measure and actual goals is one of the reasons cited for the calamity of America’s war in Vietnam.
This is sometimes called the “Streetlight Effect”, from the stories, like the one at the top of this page, of the drunk looking for something not where he lost it, but where the light is better. A proxy measure is like looking where there’s light because there's no light on the thing we want to see.
In more technical literature, the “Streetlight Effect” is typically tied to Goodhart’s Law, attributed to British economist Charles Goodhart’s criticisms of the Thatcher government, which had placed a lot of emphasis on proxy measures of prosperity. Goodhart’s Law has several formulations, but the one below is the most widely cited:
[E]very measure which becomes a target becomes a bad measure[…]
Keith Hoskins, 1996 The 'awful idea of accountability': inscribing people into the measurement of objects.00s
In AI, a famous example of this is the BLEU metric used in machine translation research. Developed in 2001 at IBM, BLEU is a way to automate the evaluation of machine translation systems, and it was a pivotal factor in the machine translation boom of the 00s. Once it was easy to give your system a score, you could work at improving it. And BLEU scores improved consistently. By 2010, it was nearly impossible to get a research paper on machine translation into a journal or conference if it didn’t beat the state-of-the-art BLEU score, no matter how innovative the paper was nor how well it might handle some specific problem that other systems were handling poorly.
The easiest way to get into a conference was to find some minor way to fiddle with the parameters of your model, get a BLEU score fractionally higher than Google Translate’s, and then submit. These results were essentially useless. Just getting some fresh texts for it to translate would show that they were rarely better and frequently worse than the state-of-the-art.
Instead of using BLEU to evaluate progress in machine translation, getting a better BLEU score became the goal. As soon as that happened, it stopped being a useful way to evaluate progress.
Are Our AI Benchmarks Good Proxies?
The most widely used benchmark for embedding models is the MTEB test set, which consists of 56 specific tests. These are averaged by category and all together to produce a collection of class-specific scores. At the time of writing, the top of the MTEB leaderboard looks like this:
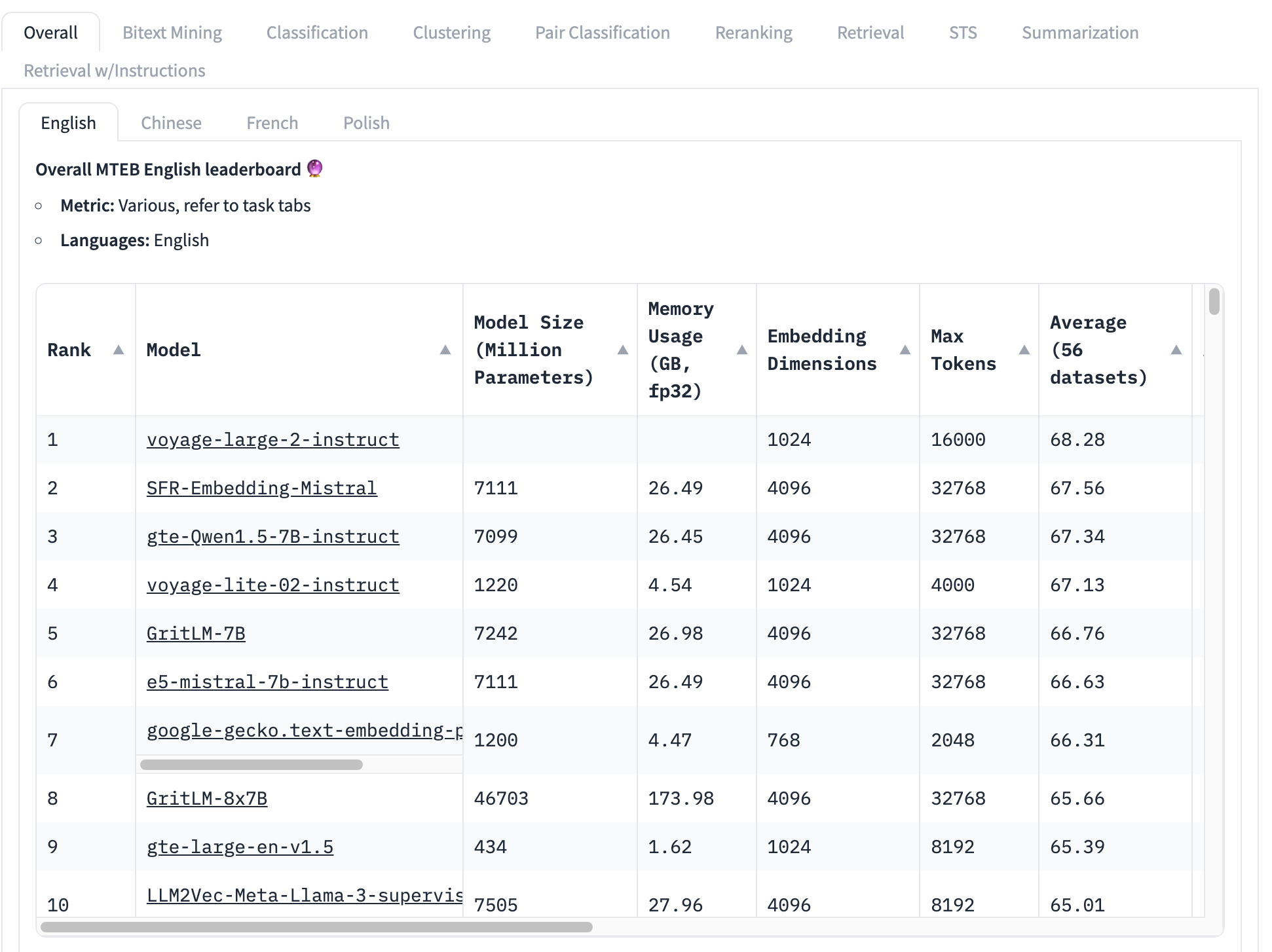
The top-ranked embedding model has an overall average score of 68.28, the next highest is 67.56. It’s very difficult, looking at this table, to know if that's a big difference or not. If it’s a small difference, then other factors may be more important than which model has the highest score:
- Model size: Models have different sizes, reflecting different computing resource demands. Small models run faster, in less memory, and require less expensive hardware. We see, on this top 10 list, models ranging in size from 434 million parameters to over 46 billion — a 100-fold difference!
- Embedding size: Embedding dimensions vary. Smaller dimensionality makes embedding vectors use less memory and storage and makes vector comparisons (the core use of embeddings) much faster. In this list, we see embedding dimensions from 768 to 4096 — only a five-fold difference but still significant when building commercial applications.
- Context input window size: Context windows vary in both size and quality, from 2048 tokens to 32768. Furthermore, different models use different approaches to positional encoding and input management, which can create biases in favor of specific parts of the input.
In short, the overall average is a very incomplete way to determine which embedding model is best.
Even if we look at task-specific scores, like those below for retrieval, we face the same problems all over again. No matter what a model’s score is on this set of tests, there is no way to know what models will perform best for your particular unique use case.
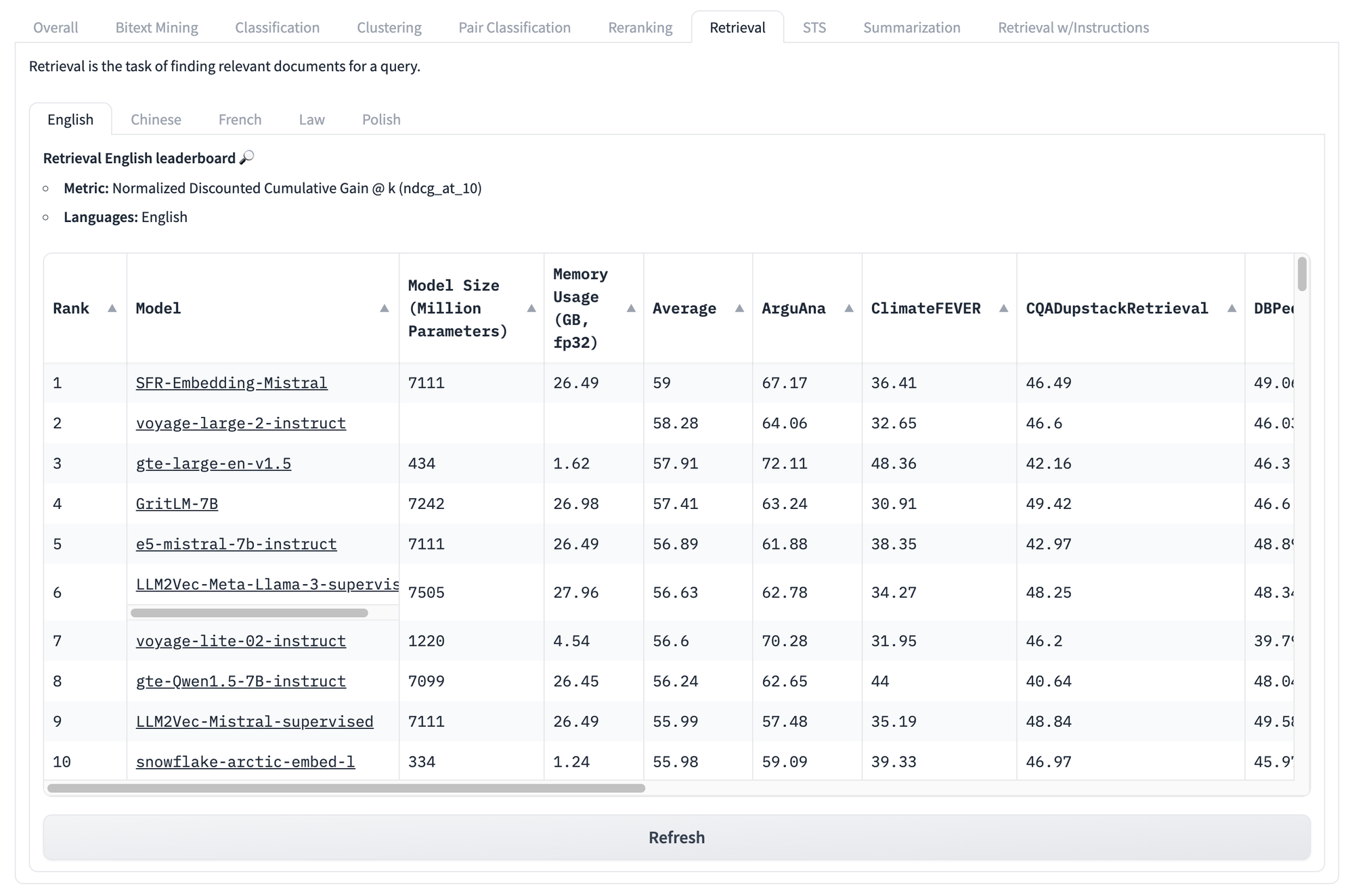
But that’s not the end of the problems with these kinds of benchmarks.
The main insight of Goodhart’s Law is that a metric can always be gamed, often without intending to. For example, MTEB benchmarks consist of data from public sources that are likely to be in your training data. Unless you specifically work to try to remove benchmarking data from your training, your benchmark scores will be statistically unsound.
There is no simple, comprehensive solution. A benchmark is a proxy and we can never be certain it reflects what we want to know but can’t directly measure.
But we do see three core problems with AI benchmarks that we can mitigate:
- Benchmarks are fixed in nature: The same tasks, using the same texts.
- Benchmarks are generic: They are not very informative about real scenarios.
- Benchmarks are inflexible: They cannot respond to diverse use cases.
AI creates problems like this, but it sometimes also creates solutions. We believe we can use AI models to address these issues, at least as they affect AI benchmarks.
Using AI to Benchmark AI: AIR-Bench
AIR-Bench is open source and available under the MIT License. You can view or download the code from its repository on GitHub.
 AIR-Bench
AIR-BenchWhat does it do?
AIR-Bench brings some important features to AI benchmarking:
- Specialization for Retrieval and RAG Applications
This benchmark is oriented towards realistic information retrieval applications and retrieval-augmented generation pipelines. - Domain and Language Flexibility
AIR makes it much easier to create benchmarks from domain-specific data or for another language, or even from task-specific data of your own. - Automated Data Generation
AIR-Bench generates test data and the dataset receives regular updates, reducing the risk of data leakage.
AIR-Bench Leaderboard on HuggingFace
We are operating a leaderboard, similar to the MTEB one, for the current release of AIR-Bench-generated tasks. We will regularly regenerate the benchmarks, add new ones, and expand coverage to more AI models.

How does it work?
The core insight of the AIR approach is that we can use large language models (LLMs) to generate new texts and new tasks that can’t be in any training set.
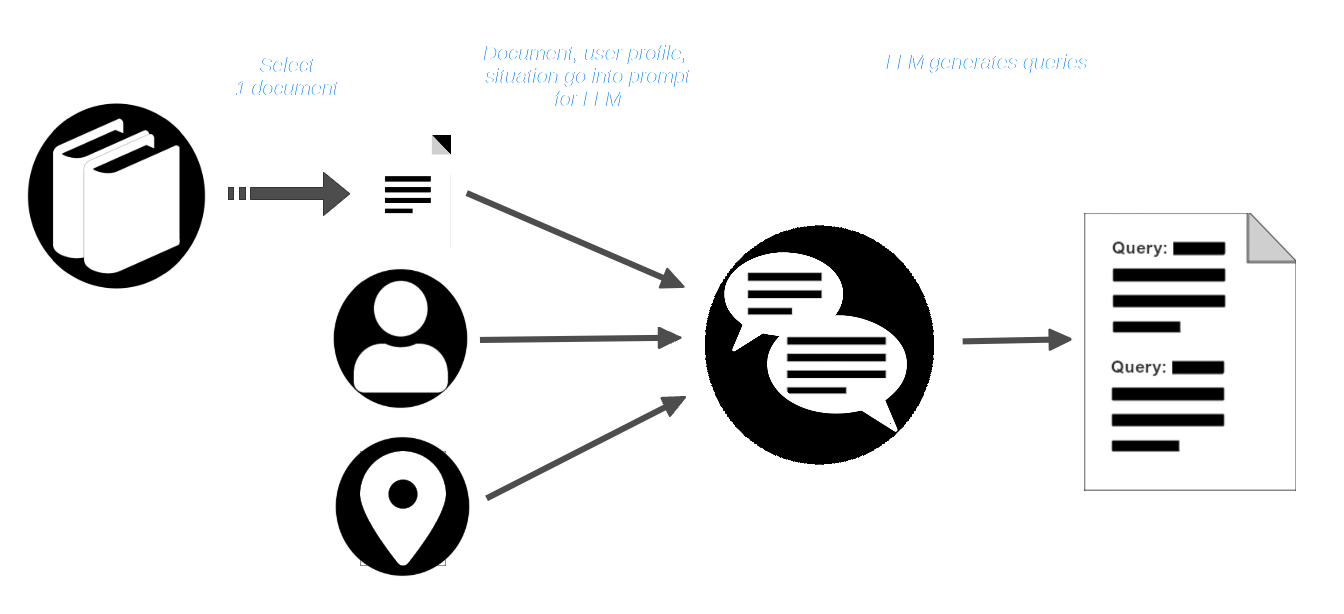
AIR-Bench takes advantage of the creative abilities of LLMs by asking them to play out a scenario. The user chooses a collection of documents — a real one that may be a part of some models’ training data — and then imagines a user with a defined role, and a situation in which they would need to use that corpus of documents.

Then, the user selects a document from the corpus and passes it, with the user profile and situation description, to the LLM. The LLM is prompted to create queries that are appropriate to that user and situation and which should find that document.
The AIR-Bench pipeline then prompts the LLM with the document and the query and makes synthetic documents that are similar to the one provided but which should not match the query.
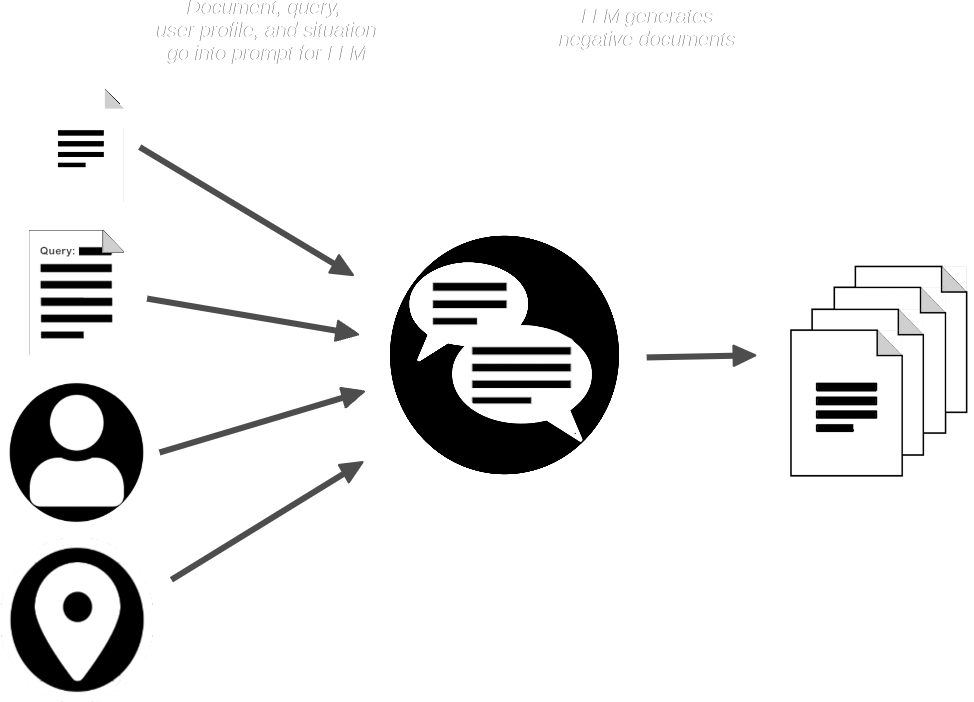
We now have:
- A collection of queries
- A matching real document for each query
- A small collection of expected non-matching synthetic documents
AIR-Bench merges the synthetic documents with the collection of real documents and then uses one or more embedding and reranker models to verify that the queries ought to be able to retrieve the matching documents. It also uses the LLM to verify that each query is relevant to the documents it ought to retrieve.
For more details on this AI-centric generation and quality control process, read the Data Generation documentation in the AIR-Bench repository on GitHub.
AIR-BenchThe result is a set of high-quality query-match pairs and a semi-synthetic dataset to run them against. Even if the original real document collection does form a part of its training, the added synthetic documents and the queries themselves are new, never-before-seen data that it could not have previously learned from.
Domain-Specific Benchmarks and Reality-Based Testing
Synthesizing queries and documents prevents benchmark data from leaking into training, but it also goes a long way to address the problem of generic benchmarks.
By providing LLMs with chosen data, a user profile, and a scenario, AIR-Bench makes it very easy to construct benchmarks for particular use cases. Furthermore, by constructing queries for a specific type of user and usage scenario, AIR-Bench can produce test queries that are truer to real-world usage than traditional benchmarks. An LLM’s limited creativity and imagination may not entirely match a real-world scenario, but it’s a better match than a static test dataset made out of data available to researchers.
As a by-product of this flexibility, AIR-Bench supports all the languages that GPT-4 supports.
Furthermore, AIR-Bench focuses specifically on realistic AI-based information retrieval, by far the most widespread application of embedding models. It does not provide scores for other kinds of tasks like clustering or classification.
The AIR-Bench Distribution
AIR-Bench is available to download, use, and modify via its GitHub repository.
AIR-BenchAIR-Bench supports two kinds of benchmarks:
- An information retrieval task based on evaluating the correct retrieval of documents relevant to specific queries.
- A “long document” task that mimics the information retrieval portion of a retrieval-augmented generation pipeline.
We have also pre-generated a set of benchmarks, in English and Chinese, along with the scripts to generate them as live examples of how to use AIR-Bench. These use sets of readily available data.
For example, for a selection of 6,738,498 English Wikipedia pages, we have generated 1,727 queries matching 4,260 documents and an additional 7,882 synthetic non-matching but similar documents. We offer conventional information retrieval benchmarks for eight English-language datasets and six in Chinese. For the “long document” tasks, we provide fifteen benchmarks, all in English.
To see the complete list and more details, visit the Available Tasks page in the AIR-Bench repo on GitHub.
AIR-BenchGet Involved
The AIR-Benchmark has been designed to be a tool for the Search Foundations community so that engaged users can create benchmarks better suited to their needs. When your tests are informative about your use cases, they inform us too, so we can build products that better meet your needs.