How Much Do We Get by Finetuning CLIP?
Jina AI Finetuner can bring performance improvements of up to 63% to pre-trained CLIP models. Here is how we did that.



Large neural network models trained on enormous datasets have proven capable of amazing things that only a few years ago were considered very hard problems in artificial intelligence. For example, correctly labeling pictures of cats and kangaroos was considered a very hard problem until recently, but now we have good solutions using large neural networks.
However, these models are pre-trained with broad categories of data. Given some specific task, their performance is often disappointing.
Jina AI Finetuner improves the performance of pre-trained models by adding new training data that better represents your specific use-cases. Finetuner simplifies fine-tuning and makes it faster and more effective by streamlining the workflow and handling all the operational complexity and physical infrastructure in the Jina AI Cloud.
 jina-ai
jina-aiWe will apply Finetuner to OpenAI's CLIP model and use the recently released CLIP Benchmark suite from LAION AI to evaluate performance. We will show that Finetuner robustly improves performance for text-to-image search over the pre-trained models by up to 63%, when Finetuner is given data specific to some use-case.
LAION-AICLIP for Image Search
CLIP was introduced by OpenAI in 2021 as a neural network architecture for jointly training representations of images with representations of descriptive texts. It consists of two networks — an image encoder and a text encoder — and pre-trains them with pairs of images and texts from a dataset of 400 million images with captions drawn from publicly available sources on the Internet. The separate text encoder and image encoder are based on existing architectures for addressing the two media types separately. The main innovation of CLIP is to join the two encoders together at training time.
The results is a system in which, for example, the image encoder will translate a picture of a dog into a vector close to the vector that the text encoder produces for the word “dog”. This means we can search for pictures that match the text "dog" by looking for images that have nearby vector representations.
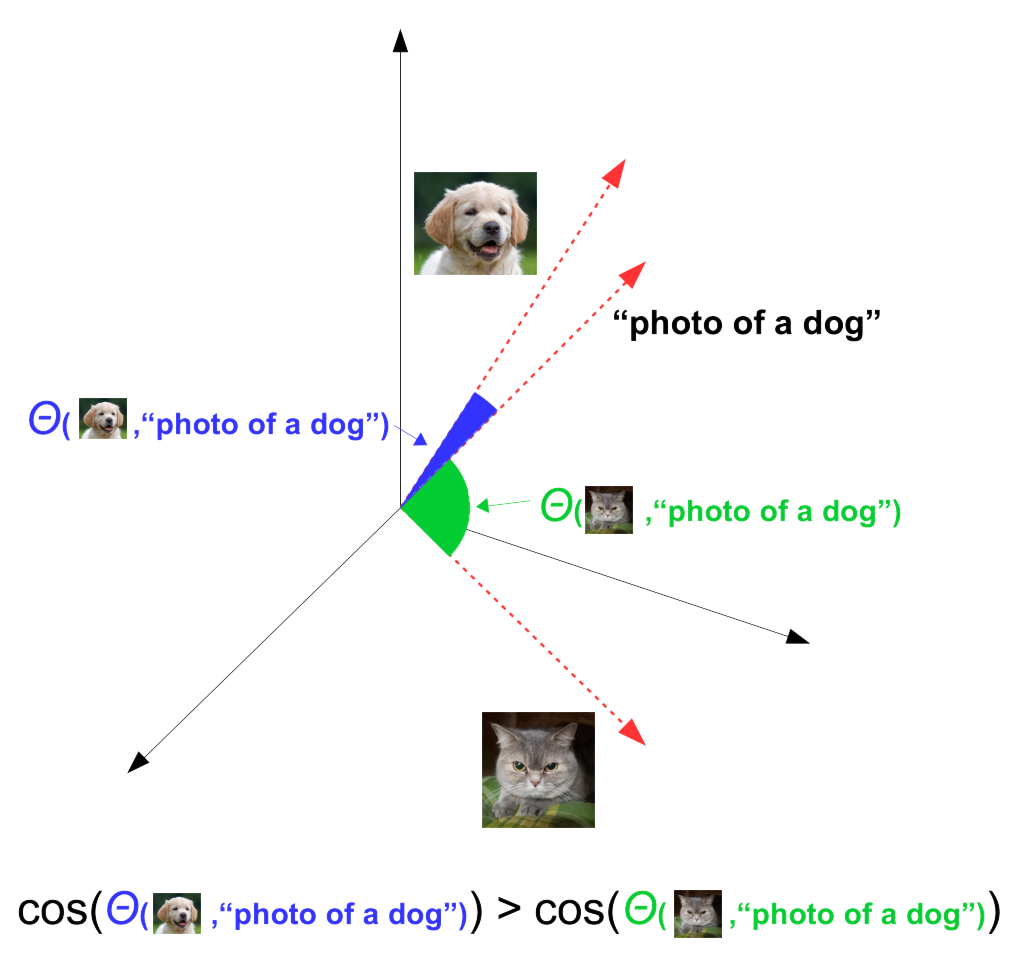
Because of the very large and diverse image dataset used to train CLIP, it is a good performer in general purpose text-to-image search without any further training.
Fine-tuning and CLIP Benchmark
We used three models for benchmarking, all available via OpenCLIP:
| model name | number of parameters | notes |
|---|---|---|
| ViT-B-32#openai | ~151 million | Original CLIP model from OpenAI |
| ViT-B-32-quickgelu#laion400m | ~151 million | Model trained with very large LAION 400M dataset |
| ViT-B-16-plus#laion400m | ~208 million | Model with significantly more parameters |
We chose these three models because the first is the original CLIP model and the most widely used, the second is the currently recommended model from OpenCLIP and has been pre-trained with a different dataset, and the third is a moderately larger (~38% larger) model than the others.
CLIP Benchmark also uses three datasets of captioned images derived from Internet sources. They are widely used in academic and commercial research.
| dataset name | number of images with captions |
|---|---|
| Flickr8k | 8,000 |
| Flickr30k | ~31,800 |
| MS-COCO (subset with captions) | ~200,000 |

Fine-tuning is very straightforward using Jina AI Finetuner. First, you must prepare the training data as a Jina DocumentArray as described in the Finetuner documentation. Then, run the Finetuner on the Jina Cloud in one command, setting relevant hyper-parameters, like the learning rate, loss function, and number of epochs.
import finetuner
from docarray import DocumentArray
flickr8k_training_data = DocumentArray(...) # create training dataset
finetuner.login()
run = finetuner.fit(
model='ViT-B-32#openai',
train_data=flickr8k_training_data,
run_name='my-clip-run',
loss='CLIPLoss',
epochs=5,
learning_rate=1e-6,
)
Fine-tuning may take some time, and you can use the finetuner.run object to monitor the task in progress and download the newly fine-tuned model, as described in the Finetuner documentation.
Results
To reproduce our results, or to try Finetuner on your own data, you can use this Google Colab notebook.


Using the CLIP Benchmark, we measured image recall by testing whether the top five images retrieved for a given text query contained the correct image for that text. We did this for the pre-trained CLIP models and then for the fine-tuned ones, for all three CLIP models and all three datasets.
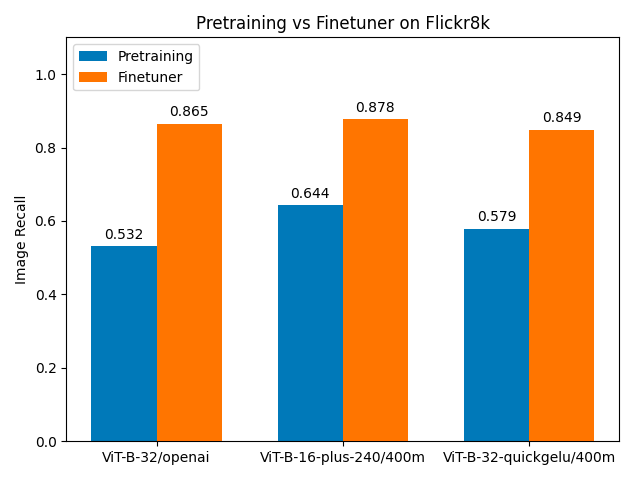
Flickr8k
| model | image recall: Pre-training | image recall: Finetuner | % improvement |
|---|---|---|---|
| ViT-B-32#openai | 0.532 | 0.865 | 62.6% |
| ViT-B-16-plus-240 | 0.644 | 0.878 | 36.3% |
| ViT-B-32-quickgelu#laion400m_e32 | 0.579 | 0.849 | 46.6% |
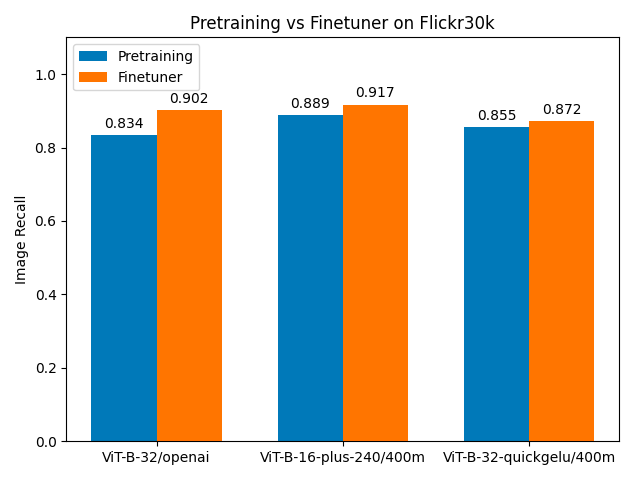
Flickr30k
| model | image recall: Pre-training | image recall: Finetuner | % improvement |
|---|---|---|---|
| ViT-B-32#openai | 0.834 | 0.902 | 8.4% |
| ViT-B-16-plus-240 | 0.889 | 0.917 | 3.4% |
| ViT-B-32-quickgelu#laion400m_e32 | 0.855 | 0.872 | 2.0% |
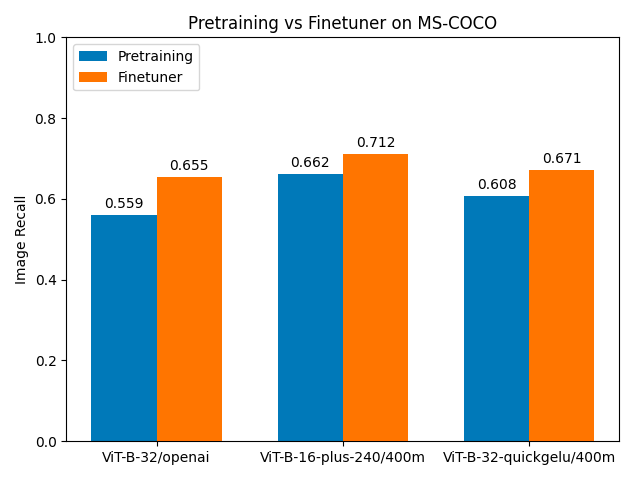
MS-COCO
| model | image recall: Pre-training | image recall: Finetuner | % improvement |
|---|---|---|---|
| ViT-B-32#openai | 0.559 | 0.655 | 17.2% |
| ViT-B-16-plus-240 | 0.662 | 0.712 | 7.6% |
| ViT-B-32-quickgelu#laion400m_e32 | 0.608 | 0.671 | 10.4% |
For every model and dataset, there was improvement.
Finetuner brought the most improvement with those datasets for which the pre-trained CLIP model had the poorest image recall. For the Flickr8k data, we see recall values in the range of 0.5 to 0.65 before fine-tuning, and values of 0.85 and up after fine-tuning, representing a very large 36% to 63% increase in recall.
For the Flickr30k data, we see much higher recall scores with only pre-training, and much less net improvement: Under 10% for all three models. When the pre-model is already doing very well, there is much less room for improvement. Although Finetuner does less to raise recall scores for this dataset, it still improves all models by a visible amount.
For the MS-COCO dataset, we see pre-training recall scores only slightly higher than for the Flickr8k dataset, but much less improvement: 7% to 17% depending on the model. MS-COCO, however, is a larger and much more diverse dataset and we should expect, given identical training hyper-parameters, that improvement would be smaller. This is still considerably more improvement than for the Flickr30k dataset.
Finetuner's impact on image recall scores is positive for every test condition used in CLIP Benchmark. This finding is robust over different models and datasets. Furthermore, the amount of improvement matches our intuitions about the effect fine-tuning should have. We see here that effect can be quite large. Going from recall levels of 0.55 to 0.87 is a dramatic increase in quality for a search system.
Summary
We have shown that using Finetuner leads to performance gains, sometimes very large performance gains.
Fine-tuning is an established technique for improving the performance of large neural network models in specific use-cases. However, the practical complexity of performing fine-tuning can be daunting to IT professionals who do not routinely work with this kind of AI. Finetuner takes care of most of these problems for you via its simple interface.
Finetuner is not limited to CLIP, and can be used to tune other models including ResNet, EfficientNet and language models like BERT. See the Benchmarks section of the Finetuner README on GitHub for some additional examples.
Please check out the Finetuner's documentation for more information.

