Beyond CLIP: How Jina-CLIP Advances Multimodal Search
Learn how Jina-CLIP enhances OpenAI's CLIP with better retrieval accuracy and more diverse results through unified text-image embeddings.



Multimodal search, which combines text and images into a seamless search experience, has gained momentum thanks to models like OpenAI's CLIP. These models effectively bridge the gap between visual and textual data, enabling us to connect images with relevant text and vice versa.
While CLIP and similar models are powerful, they have notable limitations, particularly when processing longer texts or handling complex textual relationships. This is where jina-clip-v1 steps in.
Designed to address these challenges, jina-clip-v1 offers improved text comprehension while maintaining robust text-image matching capabilities. It provides a more streamlined solution for applications using both modalities, simplifying the search process and removing the need to juggle separate models for text and images.
In this post, we'll explore what jina-clip-v1 brings to multimodal search applications, showcasing experiments that demonstrate how it enhances both the accuracy and variety of results through integrated text and image embeddings.
What is CLIP?
CLIP (Contrastive Language–Image Pretraining) is an AI model architecture developed by OpenAI that connects text and images by learning joint representations. CLIP is essentially a text model and an image model soldered together — it transforms both types of input into a shared embedding space, where similar texts and images are positioned closely together. CLIP was trained on a vast dataset of image-text pairs, enabling it to understand the relationship between visual and textual content. This allows it to generalize well across different domains, making it highly effective in zero-shot learning scenarios, such as generating captions or image retrieval.
Since CLIP’s release, other models like SigLiP, LiT, and EvaCLIP have expanded on its foundation, enhancing aspects such as training efficiency, scaling, and multimodal understanding. These models often leverage larger datasets, improved architectures, and more sophisticated training techniques to push the boundaries of text-image alignment, further advancing the field of image-language models.
While CLIP can work with text alone, it faces significant limitations. First, it was trained only on short text captions, not long texts, handling a maximum of about 77 words. Second, CLIP excels at connecting text to images but struggles when comparing text with other text, like recognizing that the strings a crimson fruit and a red apple may refer to the same thing. This is where specialized text models, like jina-embeddings-v3, shine.
These limitations complicate search tasks involving both text and images, for example, a “shop the look” online store where a user can search fashion products using either a text string or image. When indexing your products, you need to process each one multiple times - once for the image, once for the text, and once more with a text-specific model. Likewise, when a user searches for a product, your system needs to search at least twice to find both text and image targets:
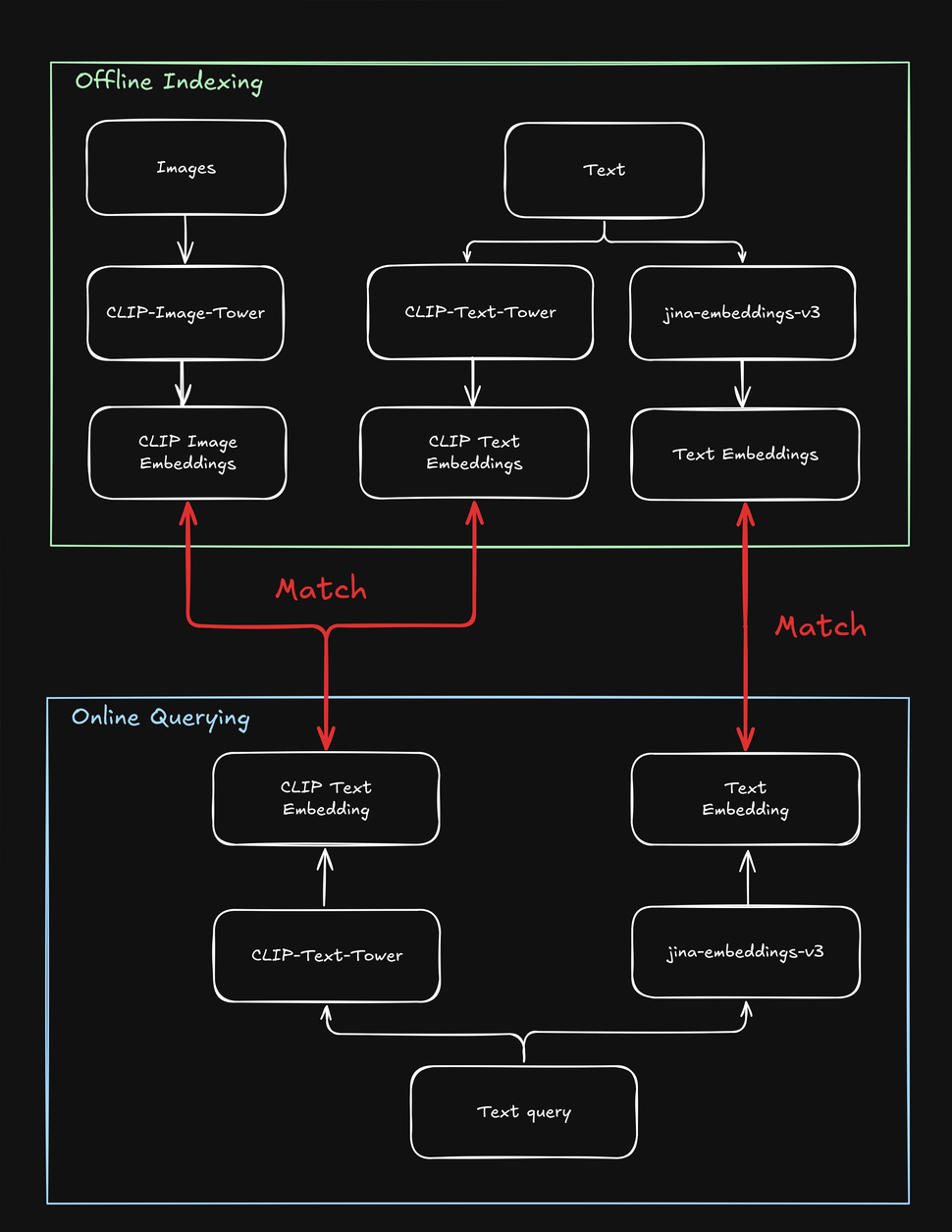
How jina-clip-v1 Solves CLIP’s Shortcomings
To overcome CLIP’s limitations, we created jina-clip-v1 to understand longer texts and more effectively match text queries to both texts and images. What makes jina-clip-v1 so special? First of all, It uses a smarter text understanding model (JinaBERT), helping it understand longer and more complicated pieces of text (like product descriptions), not just short captions (like product names). Secondly, we trained jina-clip-v1 to be good at two things at once: both matching text to images and matching text to other pieces of text.
With OpenAI CLIP, that isn’t the case: For both indexing and querying, you need to invoke two models (CLIP for images and short texts like captions, another text embedding for longer texts like descriptions). Not only does this add overhead, it slows down search, an operation that should be really fast. jina-clip-v1 does all that in one model, without the sacrifices in speed:

This unified approach opens up new possibilities that were challenging with earlier models, potentially reshaping how we approach search. In this post, we ran two experiments:
- Improving search results by combining text and image search: Can we combine what
jina-clip-v1understands from text with what it understands from images? What happens when we blend these two types of understanding? Does adding visual information change our search results? In short, can we get better results if we search with both text and images at the same time? - Using images to diversify search results: Most search engines maximize text matches. But can we use
jina-clip-v1image understanding as a "visual shuffle"? Instead of just showing the most relevant results, we could include visually diverse ones. This isn't about finding more related results – it's about showing a wider range of perspectives, even if they're less closely related. By doing this, we may discover aspects of a topic we hadn't considered before. For example, in the context of fashion search, if a user searches “multicolor cocktail dress”, do they want the top listings to all look the same (i.e. very close matches), or a wider variety to choose from (via visual shuffle)?
Both approaches are valuable across a variety of use cases where users might search with either text or images, such as in e-commerce, media, art and design, medical imaging, and beyond.
Averaging Text and Image Embeddings for Above Average Performance
When a user submits a query (usually as a text string), we can use jina-clip-v1 text tower to encode the query into a text embedding. jina-clip-v1 strength lies in its ability to understand both text and images by aligning text-to-text and text-to-image signals in the same semantic space.
Can we improve retrieval results if we combine the pre-indexed text and image embeddings of each product by averaging them?
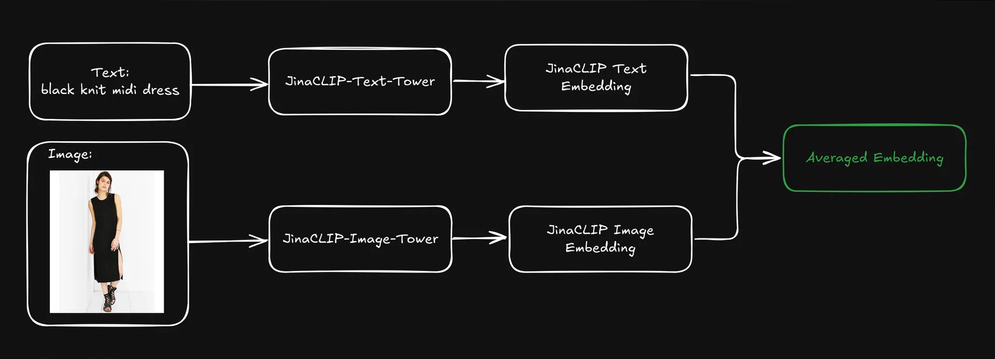
This creates a single representation that includes both textual information (e.g. product description) and visual information (e.g. product image). We can then use the text query embedding to search these blended representations. How does this affect our search results?
To find out, we used the Fashion200k dataset, a large-scale dataset specifically created for tasks related to fashion image retrieval and cross-modal understanding. It consists of over 200,000 images of fashion items, such as clothes, shoes, and accessories, along with corresponding product descriptions and metadata.
 xthan
xthanWe further categorized each item into a broad category (for example, dress) and a fine-grained category (like knit midi dress).
Analyzing Three Retrieval Methods
To see whether averaging text and image embeddings yielded better retrieval results, we experimented with three types of search, each of which uses a text string (e.g. red dress) as the query:
- Query to Description using text embeddings: Search product descriptions based on text embeddings.
- Query to Image using cross-modal search: Search product images based on image embeddings.
- Query to Average Embedding: Search averaged embeddings of both product descriptions and product images.
We first indexed the entire dataset, and then randomly generated 1,000 queries to evaluate performance. We encoded each query into a text embedding, and matched the embedding separately, based on the methods outlined above. We measured accuracy by how closely the categories of the returned products matched the input query.
When we used the query multicolor henley t-shirt dress, Query-to-Description search achieved the highest top-5 precision, but the last three top-ranked dresses were visually identical. This is less than ideal, as an effective search should balance relevance and diversity to better capture the user's attention.

The Query-to-Image cross-modal search used the same query and took the opposite approach, presenting a highly diverse collection of dresses. While it matched two out of five results with the correct broad category, none matched the fine-grained category.

The averaged text and image embedding search yielded the best outcome: all five results matched the broad category, and two out of five matched the fine-grained category. Additionally, visually duplicated items were eliminated, providing a more varied selection. Using text embeddings to search averaged text and image embeddings seems to maintain search quality while incorporating visual cues, leading to more diverse and well-rounded results.

Scaling Up: Evaluating With More Queries
To see if this would work on a larger scale, we continued running the experiment over additional broad and fine-grained categories. We ran several iterations, retrieving a different number of results (”k-values”) each time.
Across both broad and fine-grained categories, the Query to Average Embedding consistently achieved the highest precision across all k-values (10, 20, 50, 100). This shows that combining text and image embeddings provides the most accurate results for retrieving relevant items, regardless of whether the category is broad or specific:

| k | Search Type | Broad Category Precision (cosine similarity) | Fine-grained Category Precision (cosine similarity) |
|---|---|---|---|
| 10 | Query to Description | 0.9026 | 0.2314 |
| 10 | Query to Image | 0.7614 | 0.2037 |
| 10 | Query to Avg Embedding | 0.9230 | 0.2711 |
| 20 | Query to Description | 0.9150 | 0.2316 |
| 20 | Query to Image | 0.7523 | 0.1964 |
| 20 | Query to Avg Embedding | 0.9229 | 0.2631 |
| 50 | Query to Description | 0.9134 | 0.2254 |
| 50 | Query to Image | 0.7418 | 0.1750 |
| 50 | Query to Avg Embedding | 0.9226 | 0.2390 |
| 100 | Query to Description | 0.9092 | 0.2139 |
| 100 | Query to Image | 0.7258 | 0.1675 |
| 100 | Query to Avg Embedding | 0.9150 | 0.2286 |
- Query to Description using text embeddings performed well in both categories but slightly lagged behind the averaged embedding approach. This suggests that textual descriptions alone provide valuable information, particularly for broader categories like "dress," but may lack the subtlety needed for precise fine-grained classification (e.g. distinguishing between different types of dresses).
- Query to Image using cross-modal search consistently had the lowest precision in both categories. This suggests that while visual features can help identify broad categories, they’re less effective for capturing the fine-grained distinctions of specific fashion items. The challenge of distinguishing fine-grained categories purely from visual features is particularly evident, where visual differences may be subtle and require additional context provided by text.
- Overall, combining textual and visual information (via averaged embeddings) achieved high precision in both broad and fine-grained fashion retrieval tasks. Textual descriptions play an important role, especially in identifying broad categories, while images alone are less effective in both cases.
All in all, precision was much higher for broad categories compared to fine-grained categories, mostly due to items in broad categories (e.g. dress) being more represented in dataset than fine-grained categories (e.g. henley dress), simply because the latter is a subset of the former. By its very nature a broad category is easier to generalize than a fine-grained category. Outside of the fashion example, it’s straightforward to identify that something, in general, is a bird. It’s much harder to identify it as a Vogelkop Superb Bird of Paradise.
Another thing to note is that the information in a text query more easily matches other texts (like product names or descriptions), rather than visual features. Therefore, if a text is used as input, texts are a more likely output than images. We get the best results by combining both images and text (via averaging the embeddings) in our index.
Retrieve Results with Text; Diversify Them with Images
In the previous section, we touched on the issue of visually duplicated search results. In search, precision alone is not always enough. In many cases, maintaining a concise yet highly relevant and diverse ranked list is more effective, especially when the user’s query is ambiguous (for example, if a user searches black jacket — do they mean a black biker jacket, bomber jacket, blazer, or some other kind?).
Now, instead of leveraging the jina-clip-v1 cross-modal capability, let’s use the text embeddings from its text tower for the initial text search, then apply the image embeddings from the image tower as a "visual reranker" to diversify the search results. This is illustrated in the diagram below:
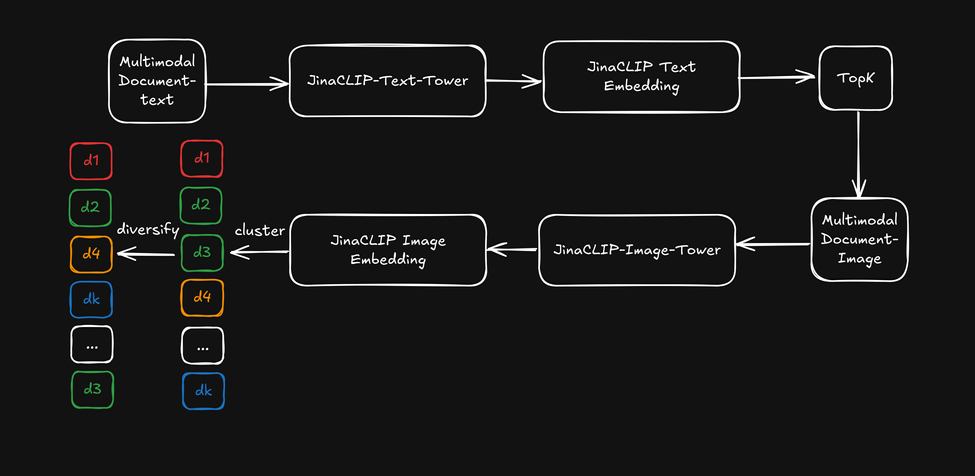
- First, retrieve the top-k search results based on text embeddings.
- For each top search result, extract visual features and cluster them using image embeddings.
- Re-order the search results by selecting one item from each cluster and present a diversified list to the user.
After retrieving the top fifty results, we applied a lightweight k-means clustering (k=5) to the image embeddings, then selected items from each cluster. The category precision remained consistent with the Query-to-Description performance, as we used the query-to-product category as the measurement metric. However, the ranked results started to cover more different aspects (like fabric, cut, and pattern) with the image-based diversification. For reference, here’s the multicolor henley t-shirt dress example from before:

Now let’s see how the diversification affects search results by using text embedding search combined with image embedding as a diversification reranker:

The ranked results originate from the text-based search but begin to cover more diverse "aspects" within the top five examples. This achieves a similar effect to averaging embeddings without actually averaging them.
However, this does come at a cost: we have to apply an additional clustering step after retrieving the top-k results, which adds a few extra milliseconds, depending on the size of the initial ranking. Additionally, determining the value of k for k-means clustering involves some heuristic guessing. That’s the price we pay for improved diversification of results!
Conclusion
jina-clip-v1 effectively bridges the gap between text and image search by unifying both modalities in a single, efficient model. Our experiments have shown that its ability to process longer, more complex text inputs alongside images delivers superior search performance compared to traditional models like CLIP.
Our testing covered various methods, including matching text to descriptions, images, and averaged embeddings. The results consistently showed that combining text and image embeddings produced the best outcomes, improving both accuracy and search result diversity. We also discovered that using image embeddings as a "visual reranker" enhanced result variety while maintaining relevance.
These advances have significant implications for real-world applications where users search using both text descriptions and images. By understanding both types of data simultaneously, jina-clip-v1 streamlines the search process, delivering more relevant results and enabling more diverse product recommendations. This unified search capability extends beyond e-commerce to benefit media asset management, digital libraries, and visual content curation, making it easier to discover relevant content across different formats.
While jina-clip-v1 currently supports only English, we're currently working on jina-clip-v2. Following in the footsteps of jina-embeddings-v3 and jina-colbert-v2, this new version will be a state-of-the-art multilingual multimodal retriever supporting 89 languages. This upgrade will open up new possibilities for search and retrieval tasks across different markets and industries, making it a more powerful embedding model for global applications in e-commerce, media, and beyond.