Create Your Personalized Podcast With Jina Reader and PromptPerfect
Use Jina Reader and PromptPerfect to generate your custom news podcast with RSS feeds, article extraction, LLMs, and Text-to-Speech.


Like a lot of people, I listen to a bunch of podcasts. Some are about science fiction. Some are about paleontology. And some are about weird medieval guys. No true crime unfortunately, except for my occasionally poor taste.
But...it's a drag to listen to all of these podcasts. Yet they aren't the worst of it. I also subscribe to a lot of news feeds. And that can be a lot of reading. It'd be fantastic if I could just take all the content of those news feeds, put it into a five-minute summary and have my phone read it out while I brush my teeth in the morning.
I guess you can see where this is going. I'm using Python to build a tool with (mostly) the Jina tech stack to create my personalized daily news podcast.
If you want to jump ahead and just hear how it sounds, you can listen below:
What's a News Feed?
First up, I'm calling them "news feeds" since most people aren't familiar with the terms RSS or Atom feeds. In short, a feed is a structured list of articles published by a blog or news source, ordered from new to old. Many sites offer them, and there are several apps and websites that let you import all your feeds, letting you read all your news in one app, without having to visit the websites for Ars Technica, Taylor Swift fansites, and Washington Post:
They're an ancient technology from the prehistoric web, but many websites support them, including Jina AI's own blog (here's our feed).
In short, feeds let you read all your news in one place, skipping all the sidebar junk and ads. In this post, we'll be using news feeds to find and download the latest posts from the sites we follow.
Let’s Start This Feeding Frenzy
pip installs and setting keys in this post, so if you want to follow along, follow the notebook for the full experience, and stick to this post for the bigger picture.Colab link | GitHub link
To make the magic happen, we're going to use several services and Python libraries:
- Feedparser: A Python library to download and extract content from news feeds.
- Jina Reader: Jina's API to extract just the content from each article, not downloading junk like headers, footers and sidebars.
- PromptPerfect: Prompts-as-Services will summarize each article then combine those summaries into a single paragraph, in the style of a news reader from NPR.
- gTTS: Google's Text-to-Speech library, to read the news report out loud.
That's all we'll cover in the post. If you want to create a podcast feed for your personalized podcast, we suggest you check other sources.
Downloading Feeds
Since this is just a simple example, we'll stick with just a couple of news feeds for The Register and OSNews, two tech news websites.
feed_urls = [
"https://www.osnews.com/feed/",
"https://www.theregister.com/headlines.atom"
]With Feedparser we can download the feeds and then download the article links from each feed:
import feedparser
for feed_url in feed_urls:
feed = feedparser.parse(feed_url)
for entry in feed["entries"]:
page_urls.append(entry["link"])Extracting Article Text With Jina Reader
Each feed contains links to each article on the relevant website. If we just download that web page, we get a whole bunch of HTML, including sidebars, headers, footers and other junk we don't need. If you feed this to an LLM it'll be like you chewing on grass. Sure, the LLM can do it, but it's not what it naturally wants to eat.
What an LLM really wants is something close to plain text. Jina Reader converts an article to Markdown.

This makes it look more like this:
Title: Unintended acceleration leads to recall of every Cybertruck produced so far
URL Source: https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/?td=rt-3a
Published Time: 2024-04-19T13:55:08Z
Markdown Content:
Tesla has issued a recall notice for every single Cybertruck it has produced thus far, a sum of 3,878 vehicles.
Today's [recall notice](https://static.nhtsa.gov/odi/rcl/2024/RCLRPT-24V276-7026.PDF) \[PDF\] by the National Highway Traffic Safety Administration states that Cybertrucks have a defect on the accelerator pedal, which can get wedged against the interior of the car, keeping it pushed down. The pedal actually comes in two parts: the pedal itself and then a longer piece on top of it. That top piece can become partially detached and then slide off against the interior trim, making it impossible for the pedal to lift up. This defect [was already suspected](https://www.theregister.com/2024/04/15/tesla_lays_off_10_percent/) as Tesla paused production of the Cybertruck due to an "unexpected delay." Some Cybertruck owners also spoke on social media about their vehicles uncontrollably accelerating, with one crashing into a pole and another demonstrating [on film](https://www.tiktok.com/@el.chepito1985/video/7357758176504089898) how exactly the pedal breaks and gets stuck.
...We cut this shorter since including the whole article is overkill. But you can see that it's clear, human-readable (markdown) text.
Instead of this:
<!doctype html>
<html lang="en">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
<title>Unintended acceleration leads to recall of every Cybertruck • The Register</title>
<meta name="robots" content="max-snippet:-1, max-image-preview:standard, max-video-preview:0">
<meta name="viewport" content="initial-scale=1.0, width=device-width"/>
<meta property="og:image" content="https://regmedia.co.uk/2019/11/22/cybertruck.jpg"/>
<meta property="og:type" content="article" />
<meta property="og:url" content="https://www.theregister.com/2024/04/19/tesla_recalls_all_3878_cybertrucks/" />
<meta property="og:title" content="Unintended acceleration leads to recall of every Cybertruck" />
<meta property="og:description" content="That isn't what Tesla meant by Full Self-Driving" />
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:site" content="@TheRegister">
<script type="application/ld+json">
...We had to cut this short before we even got to the actual content. There's just so much non-human-readable junk.
By feeding the LLM something it can more naturally digest (like markdown rather than HTML), it can give us better output. Otherwise it's like feeding Doritos to a lion. Sure, it can eat them, but it won't be its best lion-self if it maintains that diet.
To extract just the text in a human-readable way we'll use Jina Reader's API:
import requests
articles = []
for url in page_urls:
reader_url = f"https://r.jina.ai/{url}"
article = requests.get(reader_url)
articles.append(article.text)https://r.jina.ai/<url>, for example https://r.jina.ai/https://www.theregister.com/2024/04/19/wing_commander_windows_95/Summarizing the articles with PromptPerfect
Since there may be a lot of articles, we'll use an LLM to summarize each one separately. If we just put them all together and feed that to the LLM to summarize, it may choke on too many tokens at once.
This will vary depending on how many articles you want to deal with. For just a few it may be worth concat'ing them all into one long string and just making one call, saving time and money. However for this example we'll assume we're dealing with a larger number of articles.
To summarize them we'll use a Prompt-as-a-Service from PromptPerfect.
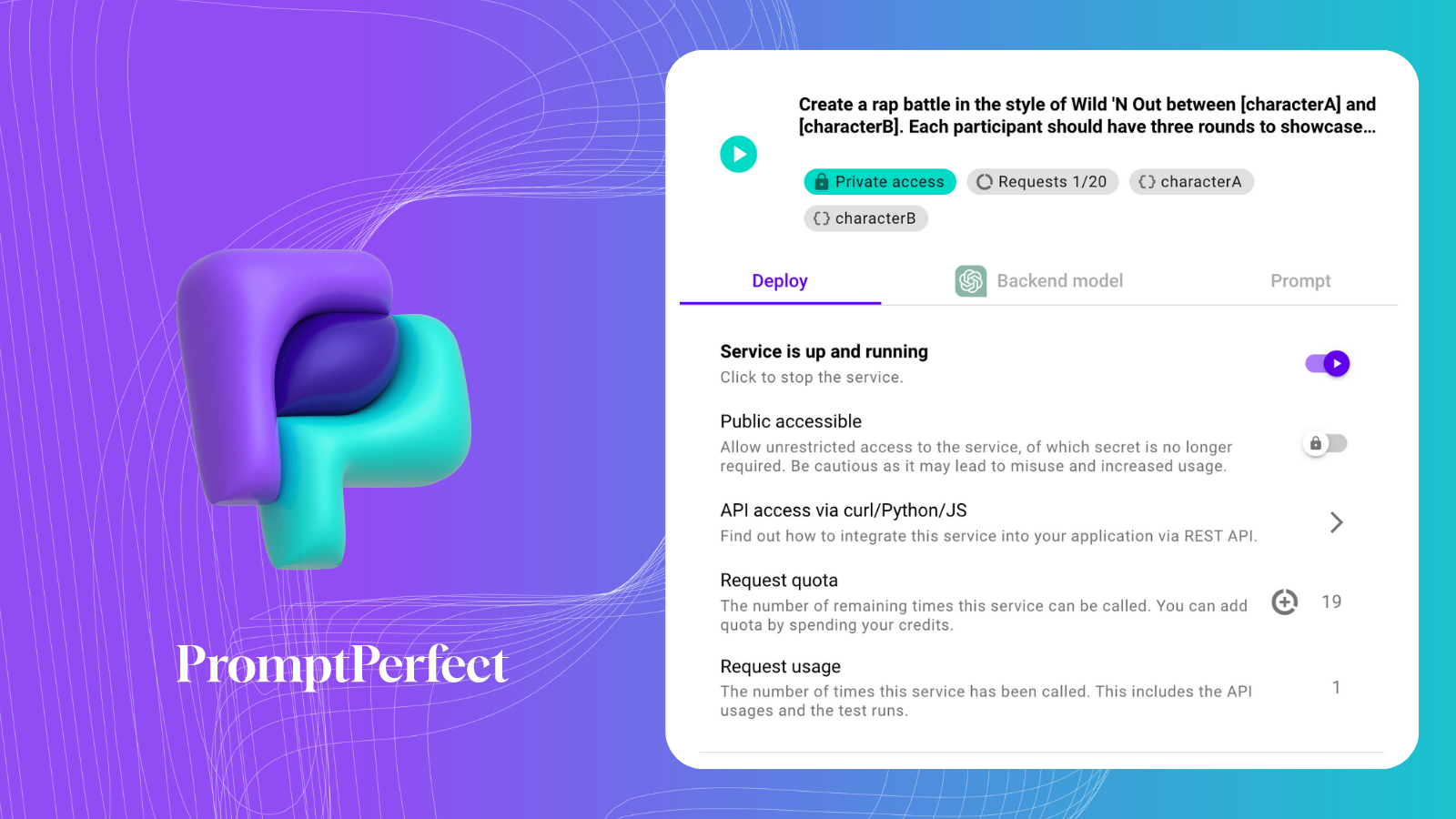
Here's our Prompt-as-Service:

We'll write a function to do this, since we'll call another Prompt-as-Service later in this post:
def get_paas_response(id, template_dict):
url = f"https://api.promptperfect.jina.ai/{id}"
headers = {
"x-api-key": f"token {PROMPTPERFECT_KEY}",
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers, json={"parameters": template_dict})
if response.status_code == 200:
text = response.json()["data"]
return text
else:
return response.textWe'll then take each summary and add them to a list, finally concat'ing them into a bulleted markdown list:
summaries = []
for article in articles:
summary = get_paas_response(
prompt_id="mkuMXLdx1kMU0Xa8l19A",
template_prompt={"article": article}
)
summaries.append(summary)
concat_summaries = "\n- ".join(summaries)Generating a News Report with PromptPerfect
Now that we've got that bulleted list, we can send that to another Prompt-as-a-Service to generate a news bulletin that sounds like natural newsreader speech:

The full prompt is:
You are an NPR technology news editor. You have received the following news summaries:
[summaries]
Your job is to give a one paragraph overview of the news, covering each item in an organic way, with segues to the next item. You can change the order of the items if that makes sense, and merge duplicates.
You will output a one paragraph script that sounds organic, to be read on NPR daily news. The script should take no longer than five minutes to read aloud.
We'll get the news script with this code:
news_script = get_paas_response(
prompt_id="tmW07mipzJ14HgAjOcfD",
template_prompt={"summaries": concat_summaries}
)Here's the final text:
Today in tech news, we have a range of updates and developments to discuss. First up, the Tiny11 Builder tool offers users the ability to debloat Windows 11, creating a customized image tailored to their preferences. Moving on to the world of gaming, we delve into the hidden components inside Super Nintendo cartridges, shedding light on the technology that fascinated gamers in the '90s. Shifting gears to software, the Niri tiling window manager for Wayland has released a major update, offering new features like infinite scrolling and improved animations. In the realm of AI, Microsoft's Copilot feature has faced some hiccups in its rollout to Windows Insiders, with bugs and intrusive behavior prompting a halt in the deployment. Meanwhile, the UK's Information Commissioner's Office raises concerns about Google's Privacy Sandbox, questioning its privacy implications and impact on competition. Lastly, the US Federal Aviation Administration has updated its launch license requirements, now mandating reentry vehicles to obtain a license before launch, following an incident involving Varda Space Industries. These diverse tech stories highlight the ongoing advancements and challenges in the tech world.
Reading the News Out Loud
To read the text out loud we'll use the Google's TTS library.


from gtts import gTTS
tts = gTTS(news_script, tld="us")
tts.save("output.mp3")This will give us a final audio file:
Next Steps
We're not going to cover the rest of the podcast creation experience in this post. That's not our forte, and just like medical advice you probably shouldn't listen to us when it comes to the nitty-gritty of setting up a podcast feed, uploading it to Spotify, Apple Podcasts, etc. For medical or podcast advice, speak to your doctor or Joe Rogan respectively.
As for what else Jina Reader can do, think of all the RAG applications you can create by downloading readable versions of any web page. Or for PromptPerfect, see how else it can help YouTubers (or marketers, if that's your jam.)