DocArray and Weaviate: Your Guide to Hybrid Search
Discover the power of hybrid search, a cutting-edge technology bridging keyword precision with vector versatility for a tailored search experience. Dive into how hybrid search works, its essential components, and using DocArray with Weaviate for optimized searches on your data.


Hybrid search is an innovative approach that unites the best of both worlds in search technology! It fuses the precision of keyword-based algorithms with the versatility of vector search techniques, creating a search experience tailored for modern users. By harnessing the strengths of various algorithms, hybrid search ensures improved accuracy and relevance in search results, revolutionizing the way we explore the vast expanse of digital information.
In this blog post, you will learn how hybrid search works, its component algorithms, and how to use DocArray with Weaviate as a vector database to perform an optimized hybrid search on your data easily.
Hybrid Search
Hybrid search uses sparse and dense vectors to represent the meaning and context of search queries and documents. Let’s look at these in turn.
Sparse Vectors: Smart Keyword Scoring
Sparse vectors, receiving their name by consisting mainly of zero values with a few non-zero values, are generated by algorithms like BM25 and SPLADE. These consider the appearance of keywords in queries and documents.
BM25, which we will be using in the hybrid search experiment later, is like the smarter sibling of TF-IDF: They both rank search results based on exact matches in your text documents. These algorithms consider your documents and queries as high-dimensional sparse vectors, where each dimension corresponds to a unique term (word or word-piece) from your collection of documents. Most of these dimensions will be zero for a given document because there are a lot of words and most don't appear in any one document. Only a few will contain non-zero values, hence the name "sparse" vectors.
BM25 considers how often a term appears in a document (just like TF-IDF), but it knows not to overvalue a word just because it appears a lot. It also levels the playing field between long and short documents, so a term does not get extra points just for being in a longer piece. In a nutshell, BM25 is a more refined way of figuring out what documents match your search query best.
Here are some of the advantages of sparse vectors in search:
- Storage and Computational Efficiency: Sparse vectors are memory efficient as they store only non-zero values, thereby conserving computational resources.
- Relevance Identification: They effectively capture the occurrence of less frequent but potentially more relevant terms, helping to identify the relevance of documents even with rare keywords.
- Scalability: Sparse vectors can efficiently handle large-scale, high-dimensional data, which is a common characteristic of text data in information retrieval.
- Fine-tuning: The ability to adjust parameters in BM25 helps in customizing the algorithm for specific datasets, improving the precision of search results.
- Better Noise Handling: Sparse vectors are better at handling 'noise' in the data (such as common words that might be less informative), as they focus on relevant, non-zero elements.
- Easy to Debug: Unlike dense vectors, sparse vectors are easier to debug and understand due to their non-zero focus. You only need to investigate the non-zero elements, which are typically fewer, significantly simplifying the process of troubleshooting and understanding model behavior. This transparency in the data representation aids in diagnosing and resolving potential issues more effectively.
Dense Vectors: Packed with Information
Dense vectors, on the other hand, predominantly contain non-zero values and are produced by machine learning models such as GloVe and Transformers. Given that different machine learning models support various modalities, dense vectors can represent various types of data stored in a database, including (but not limited to) text and images. These embeddings are generated by machine learning models that convert data into densely-packed vectors filled with non-zero values. Vector databases like Weaviate store these embeddings and enable lightning-fast retrieval based on the distance between them, using, for example, cosine similarity. In other words, vector databases add an additional vector-based index, which allows you to quickly discover data objects based on the similarity or dissimilarity between documents in this latent space.
In our experiments below, we will use a language model from sentence transformers (Sentence-BERT) to create dense representations of our textual data.
The Power of Hybrid Search
Hybrid search seamlessly blends dense and sparse vectors, delivering the best features of both search methods. Dense vectors excel at making sense of the context of a query, while sparse vectors master keyword matches. For instance, consider the query “red heels with bow”. The dense vector representation can distinguish the word “heel” as meaning “high-heeled shoes” instead of “the back part of the foot” by considering the contextual words “red” and “bow”. In contrast, the sparse vector search will contribute higher scores for exact matches of the keyword “red”, making your search results more accurate. Hybrid search brilliantly combines the strengths of both sparse and dense vectors.
Now that we have a good understanding of hybrid search and the gains we can get from it, we can jump into a working example using DocArray!
You can find all related code in a Jupyter Notebook in this GitHub repository. You can try it out in Google Colab by following the link below:


What is DocArray and how does it work with Weaviate?
The integration of Weaviate as a document store in DocArray provides a high-performing solution for the storage and retrieval of multimodal data. Weaviate, a vector database, can be utilized to store DocumentArray instances, which are used to handle nested, unstructured, and multimodal data including text, image, audio, video, 3D mesh, and more. This configuration significantly enhances the capabilities for document retrieval on embeddings, making functions like .match() and .find() more efficient and rapid.
The process of setting up Weaviate as the storage backend is streamlined and user-friendly. After installing the necessary package weaviate-client using pip, users can launch the Weaviate service by creating and running a Docker Compose configuration. The Weaviate service is designed with restart-on-failure capabilities, enabling consistent performance and reliability. Once the service is started and configured (with a default server address at http://localhost:8080), users can instantiate a DocumentArray with Weaviate storage in a single line of code.
An additional advantage of integrating Weaviate as a document store in DocArray is the seamless access to formerly-persisted DocumentArrays. Users can connect to the server by specifying the name, host, port, and protocol. The name parameter is required for this function, but all other parameters are optional, offering a versatile solution for different scenarios and configurations. Despite the changes in the backend storage, all other functions behave the same as in an in-memory DocumentArray, ensuring continuity in the user experience and functionality. This integration, therefore, presents a robust and efficient solution for managing and retrieving unstructured and multimodal data in various applications.
Setup Weaviate
Ensure you have a docker instance with Weaviate running locally or set credentials for connecting to a remote instance. To run Weaviate locally, first download the docker-compose.yml and then run docker-compose as follows:
curl -o docker-compose.yml "https://configuration.weaviate.io/v2/docker-compose/docker-compose.yml?modules=standalone&runtime=docker-compose&weaviate_version=v1.19.2"
docker-compose up -dThis will start the Weaviate cluster locally. Note that we have specified the version v1.19.2 above, which should be updated with the latest release from Weaviate (check the latest version here).
Next, you will need to create a virtual environment with all requirements from the GitHub repository installed:
python3 -m venv hybrid-venv
source hybrid-venv/bin/activate
pip install -r requirements.txt
It’s also a good idea to register this new environment as an IPython Kernel:
python -m ipykernel install --user --name=hybrid-venv
You can now select this kernel on the top right corner of your notebook and ensure you have all dependencies ready and installed!
Keeping it Real: Using Hybrid Search with Movie Data
We will use the IMDB Movies Dataset from Kaggle, containing 1000 top-rated movies on IMDB.


To download this dataset, we will use the opendatasets package, which will download the data as a CSV file into the following directory structure:
imdb-dataset-of-top-1000-movies-and-tv-shows/imdb_top_1000.csv
Run the following code to download the dataset:
import opendatasets as od
od.download("https://www.kaggle.com/datasets/harshitshankhdhar/imdb-dataset-of-top-1000-movies-and-tv-shows")
Document Schema
After the data is downloaded, we define a DocArray document schema for our data, consisting of a text field (concatenation of title, overview, and actors’ names of the movies) and an embedding field.
from docarray.typing import NdArray
from docarray import BaseDoc
from pydantic import Field
class MovieDocument(BaseDoc):
text: str # concatenation of title, overview and actors names
embedding: NdArray[384] = Field(
is_embedding=True
) # vector representation of the documentEncoding
We also define a helper function encode() to help us encode our text fields using sentence-transformers. We will be using the 'multi-qa-MiniLM-L6-cos-v1' model, which has been specifically trained for semantic search, using 215M question-answer pairs from various sources and domains, including StackExchange, Yahoo Answers, Google and Bing search queries, and many more. This model should perform well across many search tasks and domains, including movies. Let’s see how well it does.
from sentence_transformers import SentenceTransformer, util
import csv
model = SentenceTransformer(
"multi-qa-MiniLM-L6-cos-v1"
) # may take some time to load!
def encode(text: str):
embedding = model.encode(text)
return embedding
# Load the data
docs = []
with open(
"imdb-dataset-of-top-1000-movies-and-tv-shows/imdb_top_1000.csv", newline=""
) as csvfile:
movie_reader = csv.reader(csvfile, delimiter=",")
h = movie_reader.__next__()
c = 0
for row in movie_reader:
text = " ".join([row[1], row[2], row[5], row[7]] + row[9:13])
embedding = encode(text=text)
d = MovieDocument(text=text, embedding=embedding, id=c)
docs.append(d)
c += 1Here’s how the first document in our dataset looks, loaded and processed:

Now that we have 1,000 encoded documents, let’s get indexing!
Indexing
Next, we want to store our documents in a document store, in this case, in a Weaviate document index. We assume a local Weaviate instance is set up and therefore use the URL http://localhost:8080 to access it, but if you have set up a remote instance instead, you can follow the documentation for connecting to your Weaviate index.
from docarray.index.backends.weaviate import WeaviateDocumentIndex
batch_config = {
"batch_size": 20,
"dynamic": False,
"timeout_retries": 3,
"num_workers": 1,
}
runtimeconfig = WeaviateDocumentIndex.RuntimeConfig(batch_config=batch_config)
store = WeaviateDocumentIndex[MovieDocument](
host="http://localhost:8080", index_name="MovieDocument"
)
store.configure(runtimeconfig) # Batch settings being passed on
store.index(docs)Now that we have our documents indexed, we will experiment with three different approaches to search:
- Pure text search (sparse vector and keyword search with BM25)
- Dense vector search
- Hybrid search (combining sparse and dense vector approaches)
1. Text Search
Now, we can start to search our IMDB Movies data! First, we use text search with a text query to find some results. The text_search() method on the Weaviate document store will find case insensitive exact matches for our text query, meaning the words must appear in the document’s text to be returned as a result.
# Define text query
text_query = "monster scary"
# Build the query
text_q = (
store.build_query()
.text_search(text_query, search_field="text")
.limit(10)
.build()
)
# Execute the query
text_results = store.execute_query(text_q)
print("Number of documents returned: ", len(text_results))Number of documents returned: 3
The results contain three movies:



- Frankenstein (1931)
- Beauty and the Beast (1991)
- Bride of Frankenstein (1935)
The descriptions of each include the word “monster”.
Because only exact matches are returned, we only get three results, even though we set the limit to ten. This means the text search does not automatically return “similar” results - nope! It only returns results that contain our term(s). Unfortunately, there are no exact matches for the term “scary” in our dataset.
2. Vector Search
Next, we’ll try to use the embeddings supplied by the inference endpoint by also encoding the query and computing the similarity between our query vector and the vectors of our documents. We call the find() method with a query embedding on our document store.
q_embedding = encode(text_query)
vector_q = store.build_query().find(q_embedding).limit(10).build()
vector_results = store.execute_query(vector_q)
print("Number of documents returned: ", len(vector_results))Number of documents returned: 10

Great! We have ten results now. That’s because the vector comparison can still find “similar” results even if there are no explicit mentions of our terms “monster” and “scary”. We’ll take a closer look at the results in a comparative analysis below.
3. Hybrid Search
Finally, let’s build a hybrid search query, combining the precision of our text search with the recall of our vector search.
q_embedding = encode(text_query)
hybrid_q = (
store.build_query()
.text_search(
text_query,
search_field=None, # Set as None as it is required but has no effect
)
.find(q_embedding)
.limit(10)
.build()
)
hybrid_results = store.execute_query(hybrid_q)
print("Number of documents returned: ", len(hybrid_results))Number of documents returned: 10

We again have a total of ten results. These results should combine the best of both worlds, pushing documents to the top that explicitly mention our search terms and filling up the rest of the list with highly relevant results, possibly containing synonyms and related topics. We’ll analyze this below!
Results: A Comparative Analysis
Now that we have many search results from our various approaches, let’s see how many relevant results were retrieved using these approaches. The following code with display the results in a neat table.
def display_result(
bm25_data: List[MovieDocument],
vec_data: List[MovieDocument],
hyb_data: List[MovieDocument],
):
df1 = bm25_data.to_dataframe()
df2 = vec_data.to_dataframe()
df3 = hyb_data.to_dataframe()
df = pd.concat([df1, df2, df3], axis=1).drop(["embedding"], axis=1)
df.columns = [
[
"text search results",
"text search results",
"vector search results",
"vector search results",
"hybrid search results",
"hybrid search results",
],
["text", "id", "text", "id", "text", "id"],
]
return df.style.set_table_styles(
[
{"selector": "", "props": [("border", "1px solid grey")]},
{"selector": "tbody td", "props": [("border", "1px solid grey")]},
{"selector": "th", "props": [("border", "1px solid grey")]},
]
)
display_result(text_results, vector_results, hybrid_results)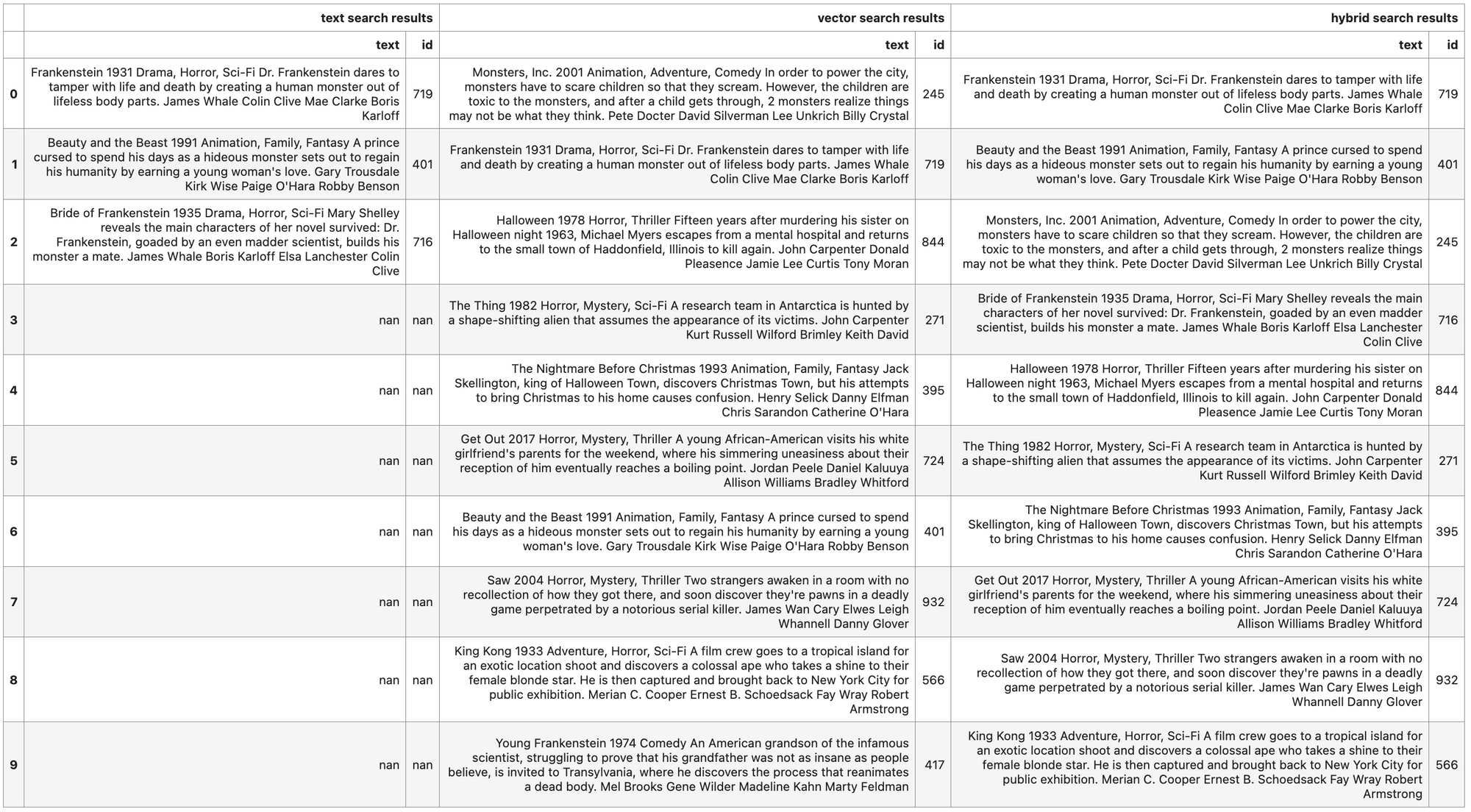
As discussed above, the text search using BM25 only returns results containing an exact match for our query terms, in this case, only matching three documents. We know with certainty that these three documents are relevant to our query, making the precision of this approach very high. However, many documents are missing, even ones that contain a pluralized form of our search terms (for example, “monsters”), making the recall of this approach poor.
The top five vector search results are also all relevant to our query, containing mentions of “monsters”, “beasts”, “Frankenstein” (also a ‘monster’), a “shape-shifting alien”, and “ogre”, though only two of the three documents retrieved by the text search approach appear in the ten results retrieved using vector search (documents 719 and 401). “Bride of Frankenstein” seems to be missing in the top ten. There are also some documents returned that don’t seem to be relevant, for example, documents 58, 740, and 984 (though they may still be ‘scary’? Actually, no. “The Muppet Movie” and “Wreck-It Ralph” are certainly not scary).

Nonetheless, the vector search approach here does quite well as it goes on latent representations of our data, capturing content with similar meanings, such as beasts, threat, ogre, victims and is thereby able to successfully retrieve quite a few relevant documents (7 out of 10), with only a few non-relevant entries.
Finally, let's look at the hybrid search results, the top five of which contain our exact matches (documents 719, 401, 716) from the text search approach! This is because these documents got a higher combined score from the BM25 component in our hybrid scoring calculation. The rest of the results are filled in by the vector search component, showing improved results over a simple BM25 search but still incorporating the advantages of this approach into the hybrid search. Although “The Muppet Movie” and “Wreck-It Ralph” (our non-relevant results) still appear in the top ten, they’ve been pushed down the list, making way for more relevant search results.
Wrapping up
In conclusion, hybrid search presents a powerful and innovative approach to search technology, offering the best of both keyword-based and vector search techniques. By combining the precision of sparse vectors generated by algorithms like BM25 with the contextual understanding provided by dense vectors, hybrid search delivers more accurate and relevant search results than either method alone. Our working example using DocArray and Weaviate demonstrates how easy it is to implement hybrid search on your data and showcases the benefits of this approach. The comparative analysis of text search, vector search, and hybrid search results highlights the improved precision and recall achieved with hybrid search, making it a promising solution for the ever-growing expanse of digital information. As search technologies continue to evolve, hybrid search stands out as a valuable tool for harnessing the power of multiple algorithms to create a superior search experience for modern users.
Keep the conversation going!
Want to discuss this post or learn more about DocArray and hybrid search? Join our Discord community and get chatting!