We're Donating DocArray to LF for an Inclusive and Standard Multimodal Data Model
DocArray is now hosted under the Linux Foundation AI & Data - a neutral home to build and support an open AI and data community. This is the start of a new day for DocArray.


November is a big time for Jina AI. From this month, DocArray will be hosted under the Linux Foundation AI & Data - a neutral home to build and support an open AI and data community. This is the start of a new day for DocArray.
In the ten months since DocArray's first release, we've seen more and more adoption and contributions from the open-source community. Today DocArray has over 150,000 downloads per month and powers hundreds of multimodal AI applications. At Jina AI, we're committed to delivering a powerful and easy-to-use tool for deep-learning engineers to represent, embed, search, store, and transfer multimodal data. But now we're sharing this commitment with you, our community and industry partners. Together with LF AI & Data, we're bringing together companies and individual contributors to build a neutral, inclusive and common standard multimodal data model. By donating DocArray to LF AI, we're letting it spread its wings and fly.
 docarray
docarrayWhat does it mean to host a project at LF?
Hosting a project with the Linux Foundation follows open governance, meaning there is no one company or individual in control of a project. When maintainers of an open source project decide to host it at the Linux Foundation, they specifically transfer the project's trademark ownership to the Linux Foundation.
In this post we'll review the history of DocArray and unveil our future roadmap. In particular, we'll demonstrate some cool features that we're already developing and will roll out in an upcoming release.
A Brief History of DocArray
We introduced the concept of "DocArray" in Jina 0.8 in late 2020. It was the jina.types module, intending to complete neural search design patterns by clarifying low-level data representation in Jina. Rather than working with Protobuf directly, the new Document class offered a simpler and safer high-level API to represent multimodal data.

Over time, we extended jina.types and moved beyond a simple Pythonic interface of Protobuf. We added DocumentArray to ease batch operations on multiple DocumentArrays. Then we brought in IO and pre-processing functions for different data modalities, like text, image, video, audio, and 3D meshes. The Executor class started to use DocumentArray for input and output. In Jina 2.0 (released in mid 2021) the design became stronger still. Document, Executor and Flow became Jina's three fundamental concepts:
- Document is the data IO in Jina
- Executor defines the logic of processing Documents
- Flow ties Executors together to accomplish a task.
The community loved the new design, as it greatly improved developer experience by hiding unnecessary complexity. This let developers focus on the things that really matter.
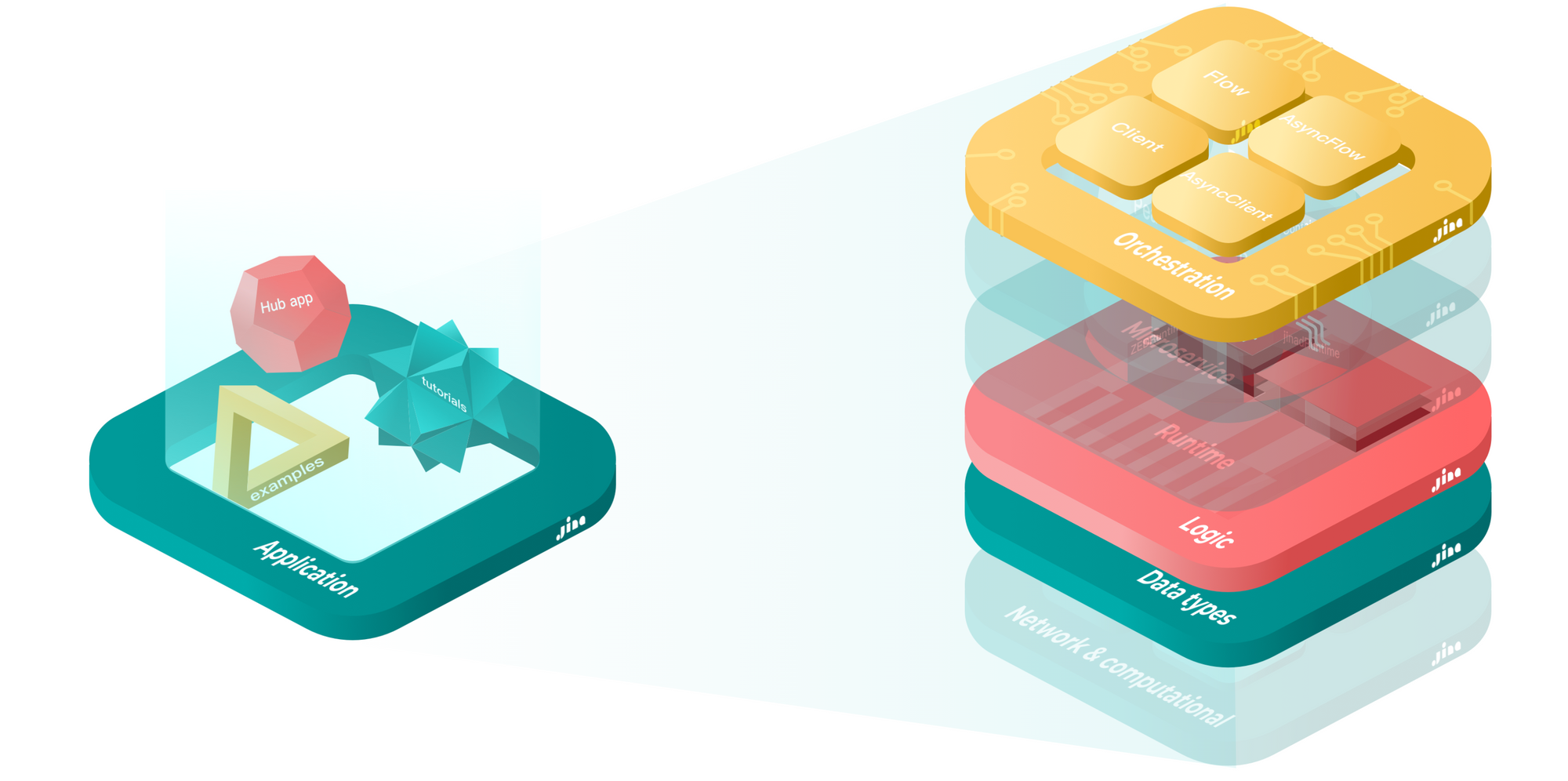
As jina.types grew, it became conceptually independent from Jina. jina.types was more about building locally, while the rest of Jina focused on service-ization. Trying to achieve two very different targets in one codebase created maintenance hurdles: On the one hand, jina.types had to evolve fast and keep adding features to meet the needs of the rapidly-evolving AI community. On the other hand, Jina itself had to remain stable and robust as it served as infrastructure. The result? A slowdown in development.
We tackled this by decoupling jina.types from Jina in late 2021. This refactoring served as the foundation of the later DocArray. It was then that DocArray's mission crystallized for the team: to provide a data structure for AI engineers to easily represent, store, transmit and embed multimodal data. DocArray focuses on local developer experience, optimized for fast prototyping. Jina scales things up and uplifts prototypes into services in production. With that in mind, we released DocArray 0.1 in parallel with Jina 3.0 in early 2022, independently as a new open source project.
DocArray is a library for nested, unstructured data such as text, image, audio, video, 3D mesh. It allows deep learning engineers to efficiently process, embed, search, recommend, store, transfer the data with Pythonic API.
— Philip Vollet (@philipvollet) January 10, 2022
JinaAI_https://t.co/vz7cu9BUqy pic.twitter.com/DYs4JMPGQX
Today, DocArray is the entrypoint of many multimodal AI applications, like the popular DALLE-Flow and DiscoArt. We've introduced new and powerful features such as dataclass and document store to improve usability even more. DocArray has allied with open-source partners like Weaviate, Qdrant, Redis, Elasticsearch, FastAPI, pydantic and Jupyter for integration and most importantly for seeking a common standard. With the paradigm shift towards multimodal AI, we see great potential for DocArray as a key player in this revolution.
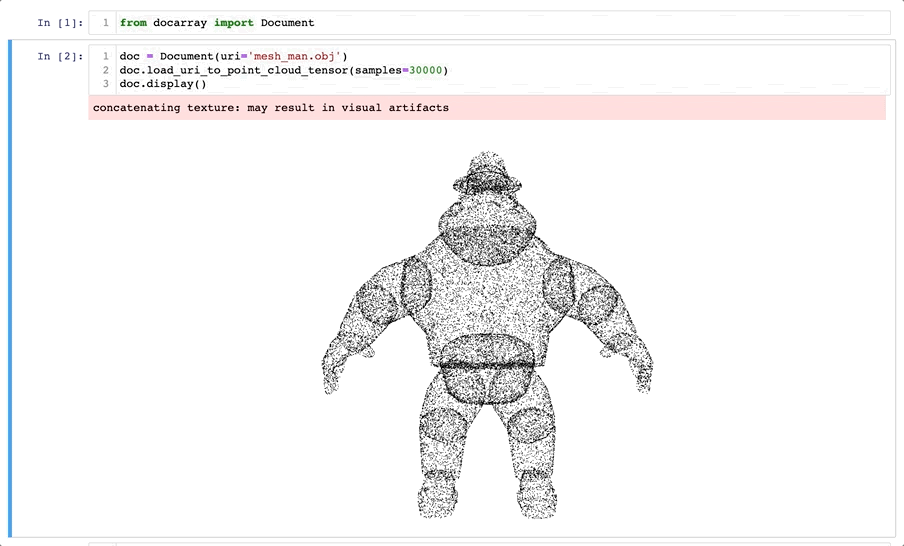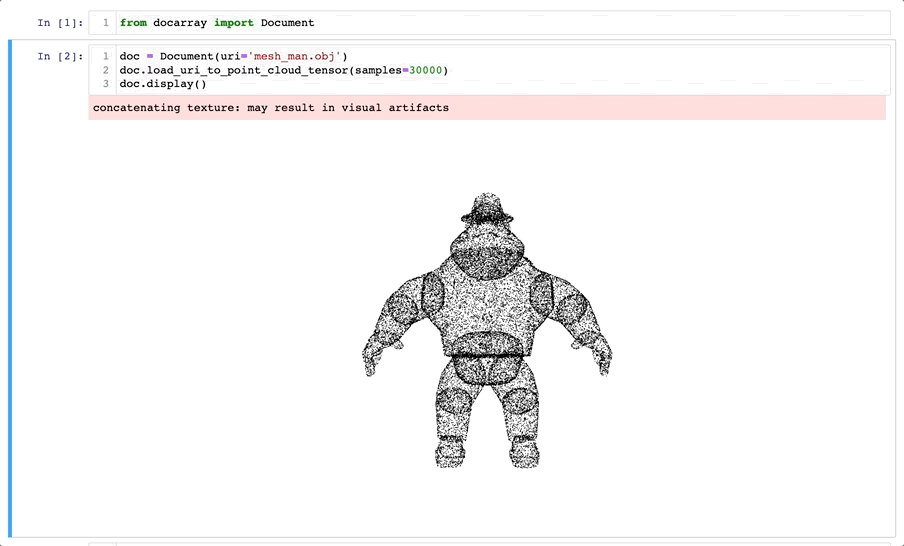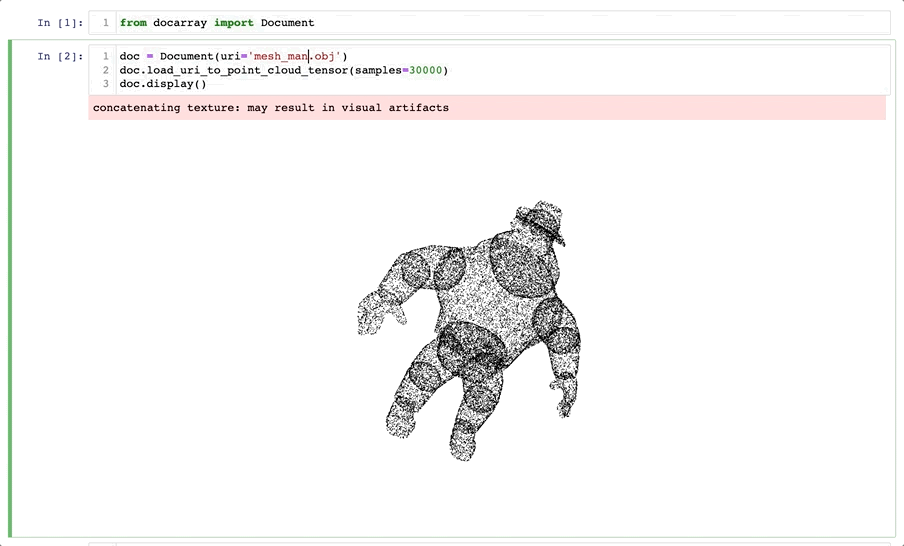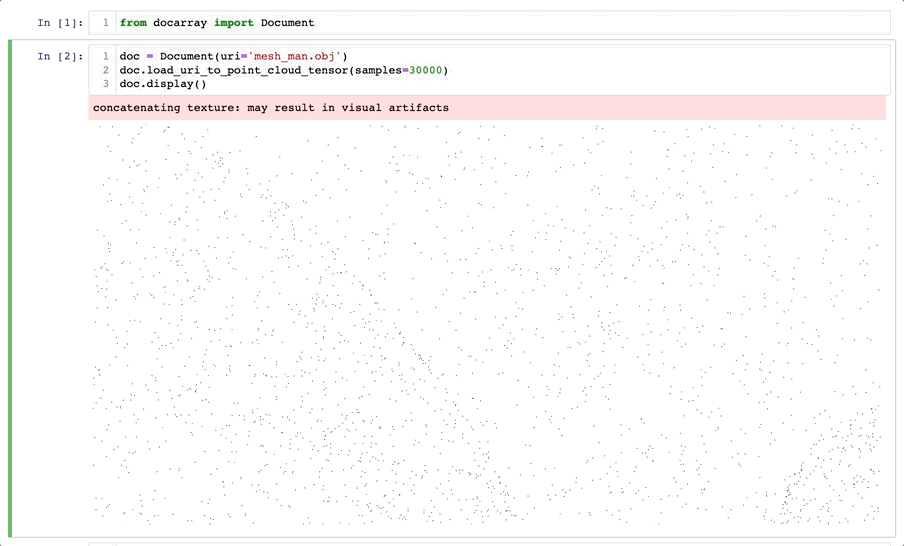
The Future of DocArray
Donating DocArray to LF marks an important milestone where we share our commitment with the open source community openly, inclusively and constructively.
The next release of DocArray focuses on four tasks:
- Representing: support Python idioms for representing complicated, nested multimodal data with ease.
- Embedding: provide smooth interfaces for mainstream deep learning models to embed data efficiently.
- Storing: support multiple vector databases for efficient persistence and approximate nearest neighbour retrieval.
- Transiting: allow fast (de)serialization and become a standard wire protocol on gRPC, HTTP and WebSockets.
We invited two core maintainers of DocArray, Sami Jaghouar and Johannes Messner, to give you a taste of the next release.
All-in-Dataclass

In DocArray, dataclass is a high-level API for representing a multimodal document. It follows the design and idiom of the standard Python dataclass, letting users represent complicated multimodal documents intuitively and process them easily via DocArray's API. The new release makes dataclass a first class citizen and refactors its old implementation by using pydantic V2.
Let's preview how to use the new dataclass. First, a Document is a pydantic model with a random ID and the Protobuf interface:
from docarray import DocumentTo create your own multimodal data type you just need to subclass from Document:
from docarray import Document
from docarray.typing import Tensor
import numpy as np
class Banner(Document):
alt_text: str
image: Tensor
banner = Banner(text='DocArray is amazing', image=np.zeros((3, 224, 224)))Once you've defined Banner, you can use it as a building block to represent more complicated data:
class BlogPost(Document):
title: str
excerpt: str
banner: Banner
tags: List[str]
content: strAdding an embedding field to BlogPost is easy: You can use the predefined Document models Text and Image, which come with the embedding field baked in:
from typing import Optional
from docarray.typing import Embedding
class Image(Document):
src: str
embedding: Optional[Embedding]
class Text(Document):
content: str
embedding: Optional[Embedding]Then you can represent your BlogPost:
class Banner(Document):
alt_text: str
image: Image
class BlogPost(Document):
title: Text
excerpt: Text
banner: Banner
tags: List[str]
content: TextThis gives your multimodal BlogPost four embedding representations: title, excerpt, content, and banner.
Milvus Support

Milvus is an open-source vector database and an open-source project hosted under LF AI & Data. It's highly flexible, reliable, and blazing fast, and supports adding, deleting, updating, and near real-time search of vectors on a trillion-byte scale. As our first step towards a more inclusive DocArray, Johannes Messner has been pushing Milvus integration in one of his gigantic pull requests.
As with other document stores, you can easily instantiate a DocumentArray with Milvus storage:
from docarray import DocumentArray
da = DocumentArray(storage='milvus', config={'n_dim': 10})Here, config is the configuration for the new Milvus collection, and n_dim is a mandatory field that specifies the dimensionality of stored embeddings. The code below shows a minimum working example with a running Milvus server on localhost:
import numpy as np
from docarray import DocumentArray
N, D = 5, 128
da = DocumentArray.empty(
N, storage='milvus', config={'n_dim': D, 'distance': 'IP'}
) # init
with da:
da.embeddings = np.random.random([N, D])
print(da.find(np.random.random(D), limit=10))
To access persisted data from another server, you need to specify collection_name, host, and port.
This allows users to enjoy all the benefits that Milvus offers, through the familiar and unified API of DocArray.
Embracing Open Governance

Finally, let's talk about how DocArray will be governed moving forwards. The term “open governance” refers to the way a project is governed – that is, how decisions are made, how the project is structured, and who is responsible for what. In the context of open source software, “open governance” means the project is governed openly and transparently, and that anyone is welcome to participate in that governance.
Open governance for DocArray has many benefits:
- DocArray will be democratically run and everyone will have a say.
- DocArray will be more accessible and inclusive, as anyone can participate in governance.
- DocArray will be higher quality, as decisions are made in a transparent and open way.
We're taking actions to embrace open governance, including:
- Creating a DocArray Technical Steering Committee (TSC) to help guide the project.
- Opening up the development process to more input and feedback from the community.
- Making DocArray development more inclusive and welcoming to new contributors.
About Linux Foundation
The Linux Foundation (LF) is a non-profit technology consortium founded in 2000 as a merger between Open Source Development Labs and the Free Standards Group to standardize Linux, support its growth, and promote its commercial adoption. Additionally, it hosts and promotes the collaborative development of open source software projects. It is a major force in promoting diversity and inclusion in both Linux and the wider open source software community. The Linux Foundation provides a neutral, trusted hub for developers to code, manage, and scale open technology projects.
About Linux Foundation AI & Data
LF AI & Data is an umbrella foundation of the Linux Foundation that supports open source innovation in artificial intelligence (AI) and data. LF AI & Data was created to support open source AI and data, and to create a sustainable open source AI and data ecosystem that makes it easy to create AI and data products and services using open source technologies. We foster collaboration under a neutral environment with an open governance in support of the harmonization and acceleration of open source technical projects.
About Jina AI
Jina AI is a commercial open-source software company founded in February 2020. It provides businesses and developers with an MLOps platform for building multimodal applications on the cloud, including neural search, creative AI, etc. The company has raised 37.5 million USD backed by top investors including Canaan Partners, GGV Capital, Yunqi Partners, SAP.io, and Mango Capital. The company is headquartered in Berlin, Germany with offices in San Jose, Beijing, and Shenzhen; its distributed team model includes members from all around the world.