Enhancing Digital Accessibility: How SceneXplain Transforms Multimedia Content for Public Sector Organizations
Explore SceneXplain's impact on digital accessibility, providing exceptional image descriptions and ensuring compliance with European standards for public sector organizations.


On a crisp autumn morning in Paris, Marie, a visually impaired woman in her early thirties, settles down in her favorite café with a warm cup of coffee. She eagerly opens her smartphone and navigates to a popular news website using her screen reader. As Marie listens to the headlines, she stumbles upon an article about a groundbreaking art exhibition.
"I wonder what the artwork looks like," she thinks aloud, as the screen reader describes the images as "Photo 1" and "Photo 2."
Frustrated, she sighs, "If only I could get a sense of the art, too."
Marie's experience is not unique; millions of visually impaired individuals worldwide face similar challenges in accessing digital content. According to the World Health Organization, there are approximately 285 million visually impaired people worldwide, with 39 million being blind. Digital accessibility is a critical issue, especially for the public sector. Governments and organizations are responsible for ensuring that their digital platforms are inclusive and accessible to all citizens, regardless of their abilities. A 2020 report by the European Commission found that only 34% of public sector websites in the EU met basic accessibility standards, highlighting the urgent need for improvement.

 CNIPA
CNIPAOne of the key components of web accessibility is providing descriptive information for images, commonly known as "alt text" or "image descriptions." A well-written image description can convey the essence of an image, allowing visually impaired users to comprehend the content and context of the image. However, even for seasoned content creators, crafting accurate and informative image descriptions is not always easy. This is where SceneXplain, a groundbreaking AI-driven solution, steps in to revolutionize how we create accessible multimedia content.
This article will explore the significance of digital accessibility, the role of image descriptions, and the challenges with existing solutions. We will then introduce SceneXplain, its advantages, and its potential applications in enhancing digital accessibility for the public sector. We will also discuss how SceneXplain can help organizations comply with European accessibility regulations and provide a roadmap for implementing SceneXplain in public sector websites and applications.
The Role of Image Descriptions in Web Accessibility
Image descriptions, also known as "alt text" or "alternative text," play a vital role in web accessibility by providing a textual representation of the visual content for users who cannot perceive it. The concept of image alt text dates back to the early days of the World Wide Web. As an example, an HTML code snippet for including an image with alt text would look like this:

<img src="image.jpg" alt="A beautiful sunset with the sun setting behind a mountain">
In this example, the alt text "A beautiful sunset with the sun setting behind a mountain" briefly describes the image, which can be read by assistive technologies or displayed when the image fails to load.
According to the Web Content Accessibility Guidelines (WCAG) 2.1, providing text alternatives for non-text content is one of the fundamental principles of web accessibility. This ensures that users who rely on assistive technologies, such as screen readers, can access and understand the visual information on websites and applications. Image descriptions are crucial in providing an inclusive and equitable online experience for people with visual impairments, those with cognitive and learning disabilities, or those with limited bandwidth or slow internet connections.
Despite the importance of image descriptions, a study by WebAIM found that only 66.3% of images on the top one million websites had alt text attributes in 2020. This demonstrates that there is still considerable room for improvement in ensuring that websites and applications are accessible to all users. Manual creation of image descriptions is often time-consuming and can be inconsistent in quality.

As we move into the era of artificial intelligence, there have been efforts to leverage AI-driven solutions to create image descriptions more efficiently. However, these solutions have their own set of limitations and shortcomings. In the following section, we will explore the challenges with existing image captioning solutions and discuss the need for more advanced and reliable tools to support digital accessibility efforts.
Challenges with Existing Image Captioning Solutions
To understand the challenges with existing image captioning solutions, we will examine the common issues faced by both industry tools and academic approaches to image description generation.
Overly Simplified or Generic Captions
One significant issue with existing image captioning solutions is the generation of overly simplified or generic captions. While these captions may be accurate in a broad sense, they often lack the necessary detail or context to provide a comprehensive understanding of the image. This shortcoming can be especially problematic for users relying on alt text for image comprehension.

Missing Nuances and Relationships
Another challenge current image captioning algorithms face is their inability to capture the nuanced relationships between objects in a scene. In many cases, these solutions may accurately identify individual objects but fail to describe the interactions or spatial relationships between them, resulting in a less informative image description.
Handling Noise and Bad Image Quality
Existing image captioning solutions often struggle with handling noisy or poor-quality images. In cases where the image has artifacts, low resolution, or poor lighting, these algorithms may fail to identify the correct objects or actions in the scene, leading to inaccurate or irrelevant captions. Users who rely on image descriptions for accessibility may face difficulties in understanding the true context of the image when the generated captions fail to accurately describe the content due to noise or bad quality.

Difficulty Handling Complex Images
Many existing image captioning algorithms struggle to generate accurate and meaningful captions for complex images. When faced with intricate scenes that contain multiple objects, actions, or interactions, these solutions may produce descriptions that fail to capture the depth and richness of the images they describe.

A captivating rendition of the iconic "Birth of Venus" painting unfolds before the eyes, as the goddess Venus emerges from a seashell. The ethereal beauty is surrounded by mythical beings and celestial figures, including a mermaid, an angel, and a woman bearing a bouquet of flowers. The delicate interplay of these characters creates a sense of enchantment and wonder, as they appear to celebrate the arrival of Venus into the world. This masterful composition invites viewers to delve into the realm of mythology and marvel at the splendor and grace that define this timeless scene.
In summary, existing image captioning solutions from the industry and academia have made significant progress in generating relevant and accurate captions. However, they often fail to provide the detail, context, and nuance necessary for truly accessible image descriptions. This is where SceneXplain can make a real difference, offering a more advanced solution for generating comprehensive and context-rich image descriptions that enhance digital accessibility.
How SceneXplain addresses the challenges in creating accessible multimedia content
SceneXplain is a cutting-edge AI-driven service that generates sophisticated textual descriptions and reveals the rich narratives hidden within images. It transcends the limitations of conventional captioning algorithms, delivering engaging, concise, and professional image storytelling experiences. With a user-friendly interface, seamless API integration, and robust multilingual support, SceneXplain empowers developers to incorporate its advanced capabilities into their multimodal applications effortlessly.

Outperforming the Competition: SceneXplain's Consistent Quality and Performance
SceneXplain's AI algorithms set the benchmark for consistent quality and performance in image captioning. In a comprehensive comparison with other popular image captioning algorithms and tools, SceneXplain consistently outperformed its competitors, capturing the most detail and context in its descriptions.


SceneXplain accurately depicts spatial relationships between objects and characters within a scene, creating rich and engaging storytelling that brings images to life. Although there is a minor tendency to hallucinate certain aspects of the scene, this can be attributed to the model's training on a vast amount of data, enabling it to make educated guesses based on similar scenarios it has encountered. Despite this, SceneXplain's performance is unrivaled, providing clear and meaningful image descriptions suitable for use as image alt tags or accessibility text for visually impaired individuals.
In contrast, solutions like Midjourney /describe and CLIP Interrogator 2.1 focus on generating creative prompts for images, rather than easily readable natural language descriptions. Meanwhile, BLIP2 generates short and concise captions, which may be suitable for simple scenes but often fail to capture more complex visuals' nuances and intricate details. Some examples are shown below; full 30 images evaluation can be found here.

SceneX: In a scene replete with historical and emotional significance, a woman proudly hoists the French flag, symbolizing the Liberation of Paris. A group of men brandishing weapons stands nearby, prepared to defend their cause. Among them, a young boy clutches his gun with determination. The tableau is interspersed with poignant scenes, such as the Crucifixion of Jesus and groups of people lying on the ground, evoking a sense of sacrifice and resilience. This powerful image serves as a testament to the human spirit and its capacity for triumph in the face of adversity.Midjourney /describe: the liberation of paris in 1832 by gustave lutin, in the style of feminist art and contemporary feminist, light navy and dark bronze, heavy use of palette knives, irony, trompe-l'œil illusionistic detail, rangercore, joyful chaos --ar 58:45BLIP2: liberty leading the peopleCLIP Interrogator 2.1: a painting of a woman holding a flag, an album cover, by Eugene Delacroix, flickr, arms held high in triumph, iconic shot, menacing!!!, trending photo
SceneX: An eye-catching billboard displays the phrase "DTF Head Over Heels," capturing the attention of passersby with its vibrant imagery and bold statement. The advertisement features various romantic scenarios, including two women sharing a tender kiss against a backdrop of a pink sky, a man and woman embracing in a heartfelt hug, and another pair of women hugging affectionately. The billboard also showcases more unconventional elements, such as a close-up of a woman's feet and the silhouette of an expectant mother. An OkCupid dating design adds context to these diverse depictions of love and relationships, inviting viewers to contemplate the vast spectrum of human connection and emotion embodied in this striking visual display.Midjourney /describe: the billboard dtf head-over-heels , in the style of feminine imagery, humor meets heart, humor meets heart, colorized, playful imagery, hikecore, sandalpunk --ar 2:1BLIP2: a billboard with the words dtf all over heelsCLIP Interrogator 2.1: a billboard that says dtf all head over heels, by Adam Dario Keel, cupid, ocult, product placement, attractive female
SceneX: A bustling city street teems with life as pedestrians traverse the urban landscape, surrounded by an array of buildings that impart a sense of metropolitan charm. The heart of Berlin, Germany, reveals itself in this dynamic scene, where people walk along the sidewalks and a tram awaits passengers at a nearby train station. The vibrant atmosphere is palpable as individuals go about their daily routines, navigating the streets and engaging with their surroundings. This lively tableau encapsulates the essence of city living, showcasing the energy and excitement inherent in urban environments.Midjourney /describe: a busy city street with a bus driving, in the style of deutscher werkbund, consumer culture critique, impressive panoramas, award-winning, poignant, passage, hypnotic symmetry --ar 50:33BLIP2: a busy city street with people walking and cars drivingCLIP Interrogator 2.1: a street filled with lots of traffic next to tall buildings, by Micha Klein, shutterstock, berlin secession, tram, stock photo, people at work, stock image
SceneX: In a bustling medieval theater, two valiant knights clad in armor engage in a thrilling joust, their lances poised for impact. The audience, dressed in period attire, watches the spectacle with bated breath. Among the onlookers are groups of men and women adorned with hats, their keen eyes following the action. Behind the scenes, a pigeon rests in its cage, seemingly indifferent to the excitement unfolding before it. This riveting scene transports viewers to a bygone era of chivalry and pageantry, where honor and bravery were celebrated through thrilling contests of skill and strength.Midjourney /describe: a drawing shows two men fighting in an arena, in the style of quirky caricatures, lively interiors, swordpunk, watercolor technique, school of london, ritualistic masks, grid-based --ar 32:21BLIP2: a drawing of men fighting in the middle of a crowdCLIP Interrogator 2.1: a couple of men standing next to each other on a stage, by George Cruikshank, shutterstock, renaissance, facing off in a duel, in medieval armoury, school class, still image from the movieSceneXplain's advanced capabilities and versatility make it a powerful tool for a wide range of applications, from providing image alt tags for accessibility to enhancing user experiences with engaging visual storytelling. With its consistent quality and performance, SceneXplain is the best choice for organizations seeking to improve digital accessibility through accurate, detailed, and contextually rich image descriptions.
Resilience to noise and varying image quality
SceneXplain's robust AI algorithms have been designed to handle varying image quality and noise levels, ensuring that the generated descriptions remain accurate and relevant even when the input image is less than ideal.
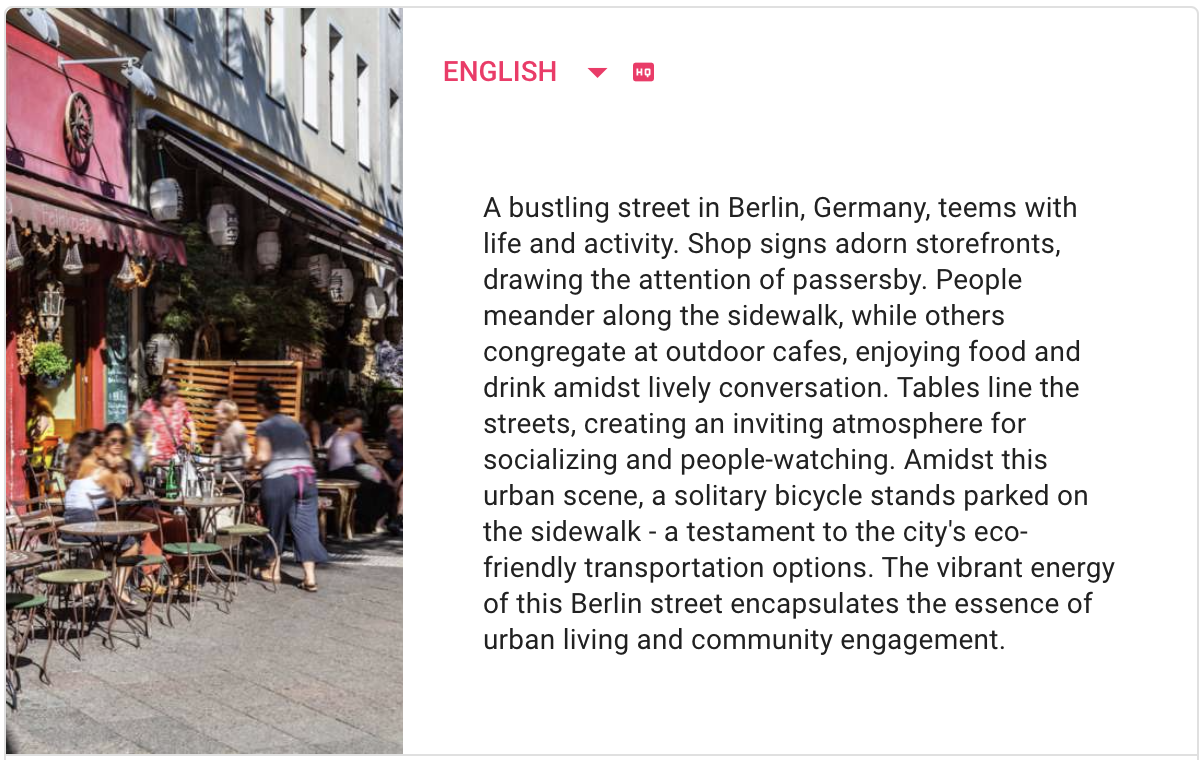

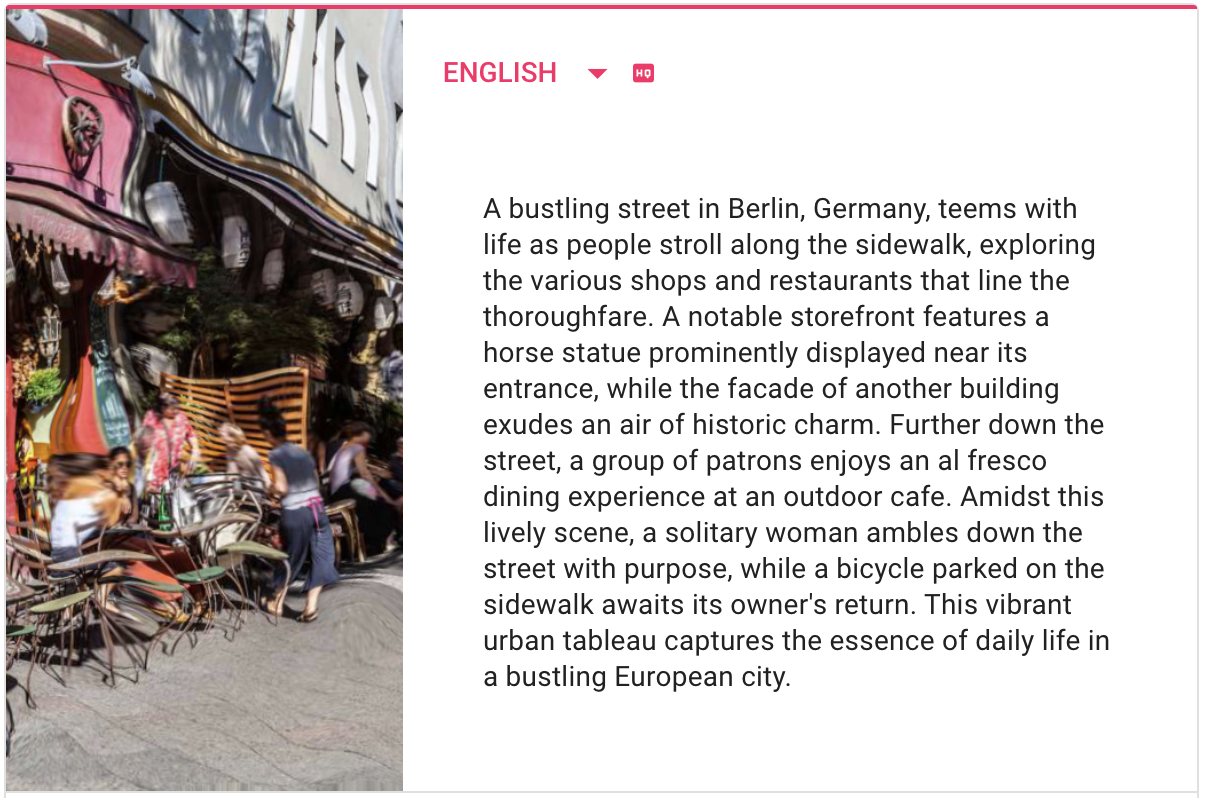

Multilingual Support for Enhanced Accessibility
One of the key features of SceneXplain that sets it apart from other image captioning solutions is its robust multilingual support. Catering to the diverse linguistic landscape of the European Union and beyond, SceneXplain can generate context-rich image descriptions in multiple languages, making it an invaluable tool for enhancing accessibility on a global scale.
This multilingual capability allows organizations to provide accurate and engaging image descriptions to users of different languages, ensuring their content is accessible to a broader audience. By offering this linguistic versatility, SceneXplain demonstrates its commitment to fostering an inclusive digital environment that embraces the rich cultural and linguistic diversity of the European Union and the world.
By addressing these key challenges, SceneXplain is poised to revolutionize the way accessible multimedia content is created and consumed. Its advanced capabilities hold great potential for enhancing the digital accessibility landscape, making the web a more inclusive space for all users.
Ensuring Compliance with European Accessibility Standards
Digital accessibility has become a priority for governments and organizations around the world. In Europe, several regulations and guidelines have been established to ensure digital content is accessible to all users, including those with disabilities. The Web Content Accessibility Guidelines (WCAG) are globally recognized recommendations for making web content more accessible. Additionally, the European Union has implemented the Web Accessibility Directive, which requires public sector organizations to adhere to WCAG 2.1 Level AA standards.

According to the European Commission, around 80 million Europeans have a disability. With the growing need for accessible content, non-compliance with accessibility regulations can lead to lawsuits and fines. In 2018, a study conducted by the European Disability Forum found that 89% of European public sector websites failed to meet accessibility standards, highlighting the urgent need for improvement.


How SceneXplain Helps Organizations Meet Accessibility Requirements
SceneXplain is designed to help organizations comply with European accessibility standards by providing accurate, detailed, and contextually rich image descriptions. By integrating SceneXplain's advanced image captioning capabilities, public sector websites and applications can generate image alt tags and other accessible multimedia content that adheres to the WCAG 2.1 Level AA guidelines. This ensures visually impaired users can better understand and engage with the content, resulting in a more inclusive digital experience.
SceneXplain's multilingual support further enhances its potential to meet accessibility requirements in the European context. By providing context-rich translations for image descriptions, SceneXplain enables organizations to cater to the diverse linguistic needs of users across the EU, ensuring that content remains accessible in multiple languages.
Benefits of Using SceneXplain in Public Sector Websites and Applications
There are several benefits to incorporating SceneXplain into public sector websites and applications:
- Improved Accessibility: SceneXplain's advanced image captioning algorithms generate detailed and accurate descriptions, ensuring that visually impaired users can better understand and engage with multimedia content.
- Compliance with Regulations: Integrating SceneXplain helps public sector organizations comply with the Web Accessibility Directive and WCAG 2.1 Level AA guidelines, minimizing the risk of non-compliance penalties. In recent years, several high-profile lawsuits have involved website accessibility, emphasizing the importance of adhering to these guidelines to avoid legal repercussions.
- Enhanced User Experience: By providing engaging and informative image descriptions, SceneXplain enriches the overall user experience for all users, not just those with disabilities.
- Multilingual Support: SceneXplain's ability to generate context-rich translations for image descriptions enables organizations to cater to the diverse linguistic needs of users across the EU, further enhancing accessibility.
By leveraging SceneXplain's advanced image captioning capabilities, European public sector organizations can ensure compliance with accessibility standards and create a more inclusive digital environment for all users. The urgency of adhering to these regulations is highlighted by the growing number of people with disabilities, the risk of lawsuits, and the need to provide everyone with equal access to digital content.
Integration Process of SceneXplain with Public Sector Websites and Applications
Integrating SceneXplain with public sector websites and applications can significantly enhance digital accessibility. SceneXplain offers multiple integration options to cater to the diverse needs of organizations. Here, we will explore three ways to integrate SceneXplain:
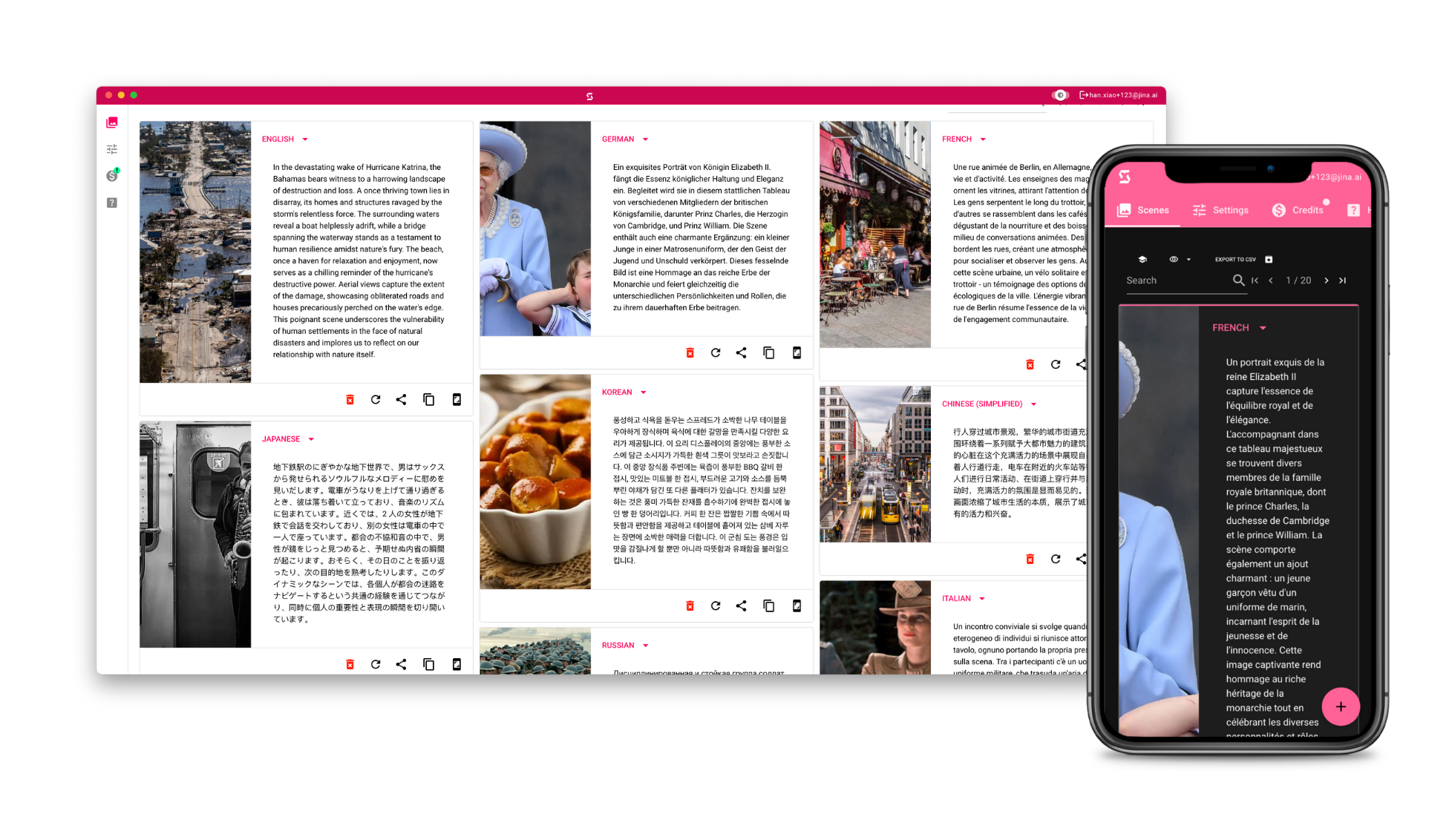
Create Accessible Image via SceneXplain UI
SceneXplain's user-friendly web interface allows organizations to quickly and easily generate image descriptions without the need for extensive technical knowledge. By uploading images directly to the web platform, users can obtain detailed textual descriptions that can then be incorporated into their website's image alt tags or other accessibility features. This approach is ideal for organizations with limited technical resources or those who require occasional image captioning services.
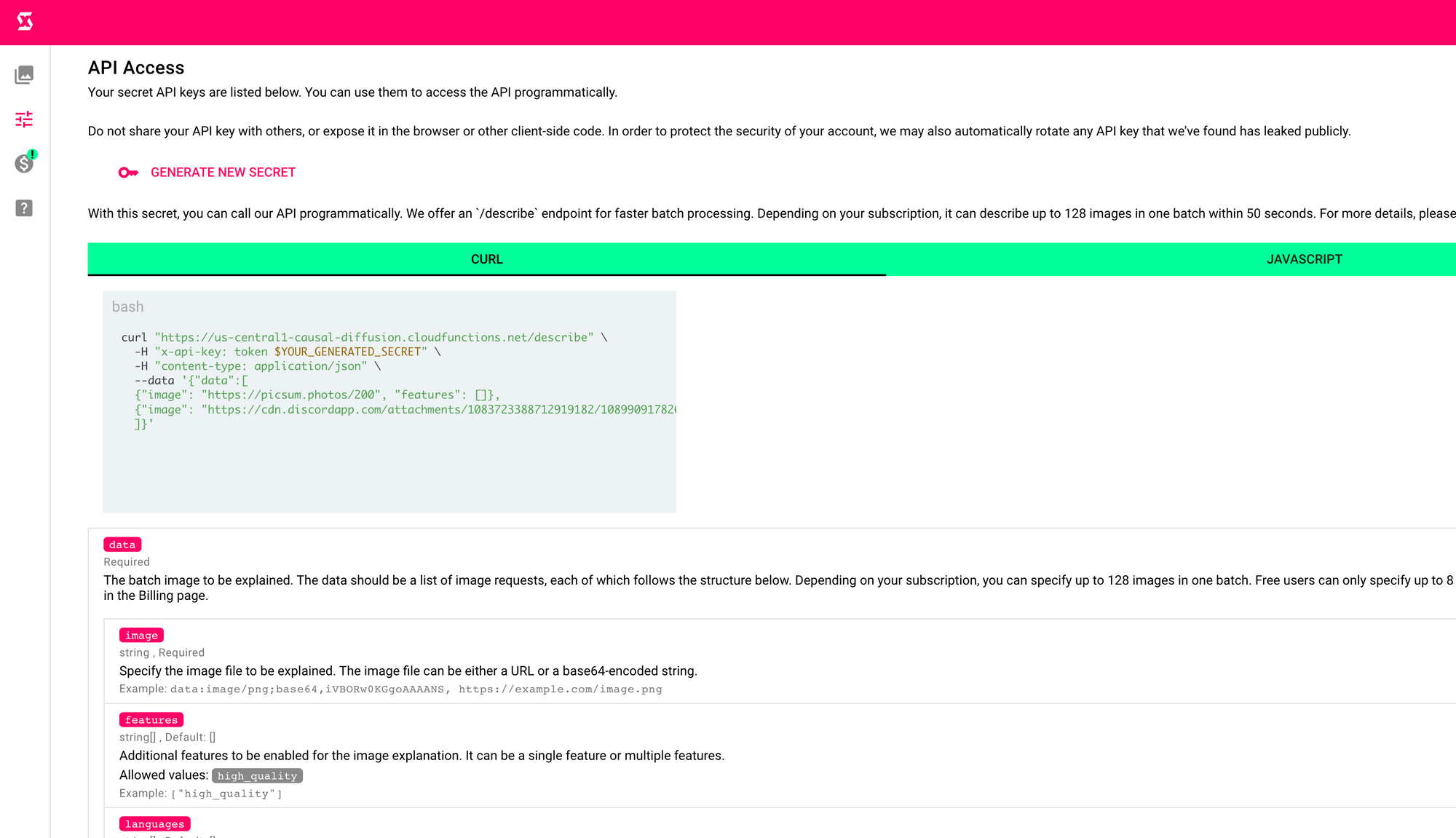
Batch Process Images via SceneXplain API
For organizations seeking an automated and seamless integration, SceneXplain offers a robust, scalable, and secure API for their systems. The fast batch API allows describing up to 128 images in one batch within 40 seconds, ideal for those requiring high volumes of image captioning services.
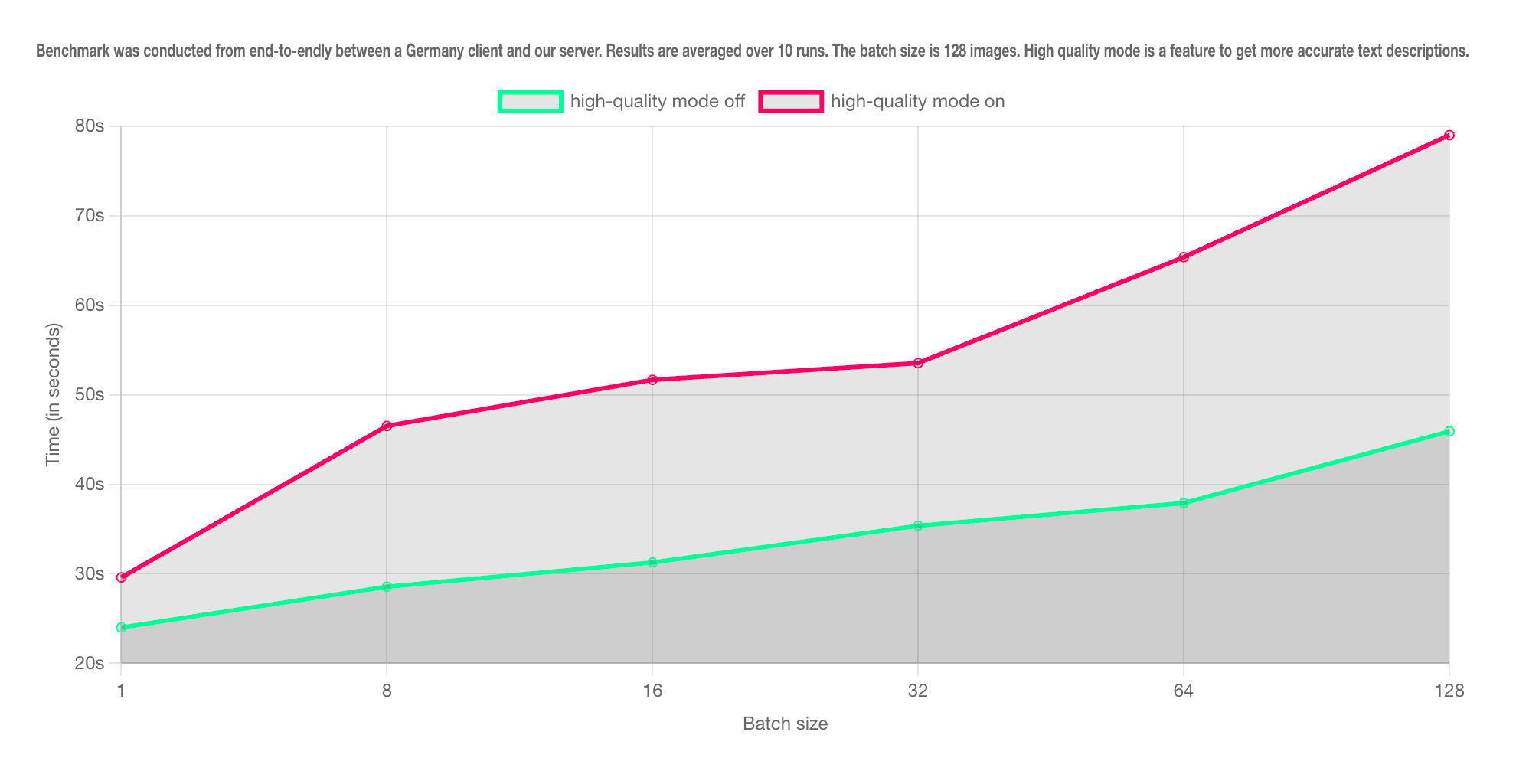
Organizations can automatically generate image descriptions by connecting SceneXplain's API to websites or applications, ensuring accessibility compliance with European standards. The API integration suits organizations with dedicated technical teams or those needing large-scale image captioning. Secure data handling ensures privacy and data protection during integration, providing a seamless experience while enhancing digital accessibility for all users.
Privacy-Preserved Solution in On-prem
SceneXplain also provides an on-premises solution for organizations that prefer to maintain full control over their data and systems. By deploying SceneXplain on their servers, organizations can ensure that their sensitive data remains within their network while benefiting from the advanced image captioning capabilities of SceneXplain. This option is particularly relevant for public sector organizations with strict data security and privacy requirements.
Each integration option offers unique benefits and caters to different organizational needs. By choosing the most suitable integration method, public sector organizations can effectively harness the power of SceneXplain to enhance digital accessibility and comply with European accessibility regulations.
Conclusion
In conclusion, SceneXplain is a groundbreaking solution advancing digital accessibility in the public sector. By leveraging its advanced AI capabilities, SceneXplain generates precise, context-rich, and engaging image descriptions, ensuring that multimedia content is accessible to all users, including those with visual impairments.

As digital accessibility becomes increasingly essential, public sector organizations must adopt innovative tools like SceneXplain to meet the demands of an inclusive online experience. Integrating SceneXplain not only ensures compliance with European accessibility standards but also enhances the overall user experience for all citizens.
Now is the time for public sector organizations to take the initiative and harness the power of SceneXplain to create a more inclusive digital landscape. Embrace the change and join the movement towards a more accessible and equal online world for everyone.