Fact-Checking with New Grounding API in Jina Reader
With the new g.jina.ai, you can easily ground statements to reduce LLM hallucinations or improve the integrity of human-written content.

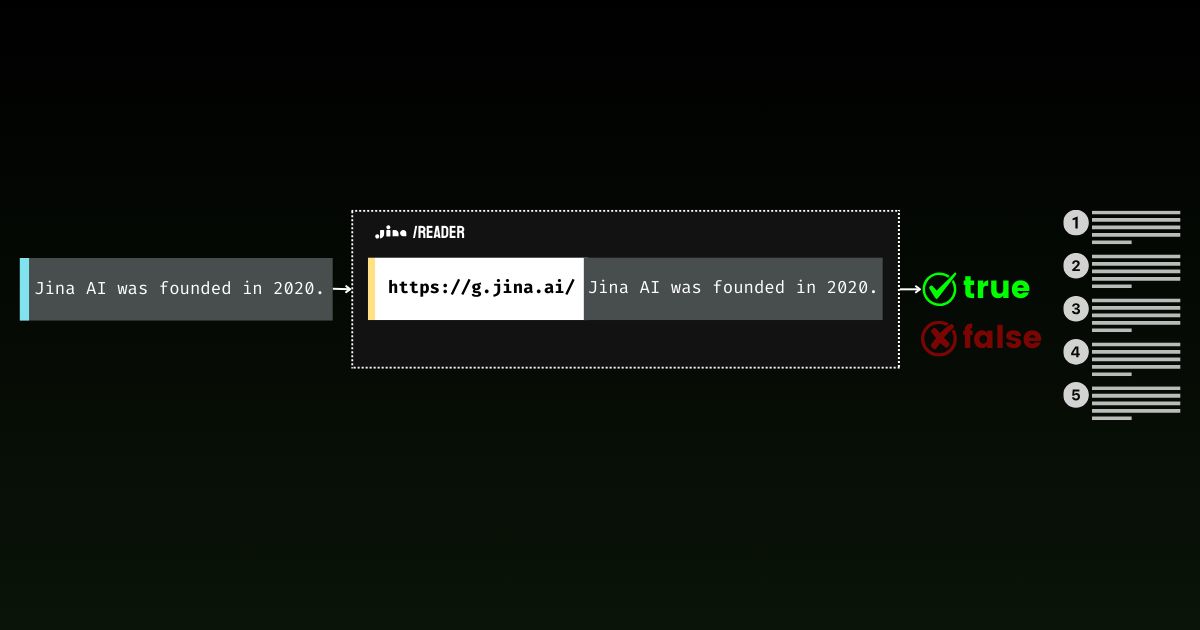
Grounding is absolutely essential for GenAI applications.
Without grounding, LLMs are more prone to hallucinations and generating inaccurate information, especially when their training data lacks up-to-date or specific knowledge. No matter how strong an LLM's reasoning ability is, it simply can't provide a correct answer if the information was introduced after its knowledge cut-off date.
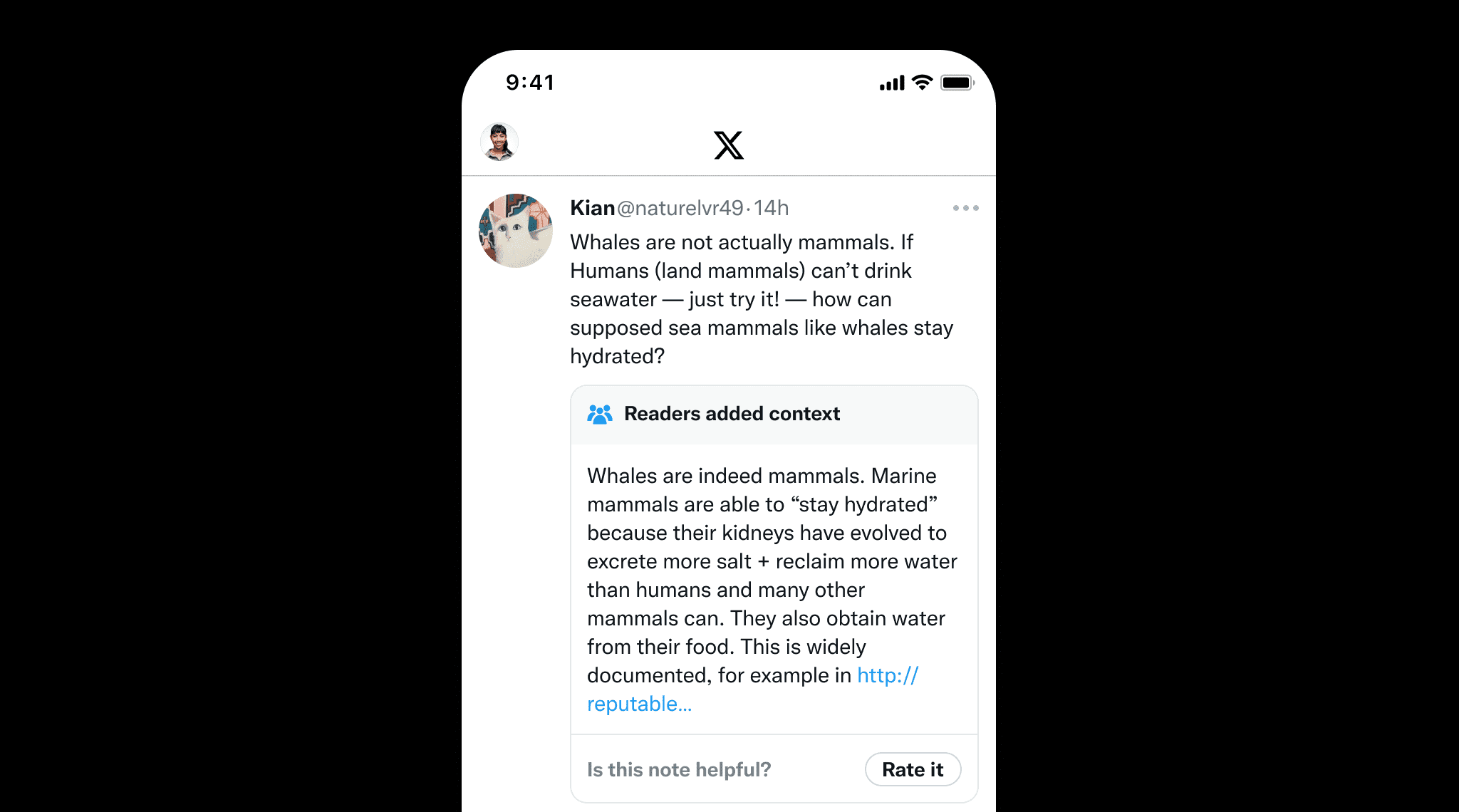
Grounding is not just important for LLMs but also for human-written content to prevent misinformation. A great example is X's Community Notes, where users collaboratively add context to potentially misleading posts. This highlights the value of grounding, which ensures factual accuracy by providing clear sources and references, much like Community Notes helps maintain information integrity.
With Jina Reader, we’ve been actively developing an easy-to-use grounding solution. For example, r.jina.ai converts web pages into LLM-friendly markdown, and s.jina.ai aggregates search results into a unified markdown format based on a given query.

Today, we're excited to introduce a new endpoint to this suite: g.jina.ai. The new API takes a given statement, grounds it using real-time web search results, and returns a factuality score and the exact references used. Our experiments show this API achieves a higher F1 score for fact-checking compared to models like GPT-4, o1-mini and Gemini 1.5 Flash & Pro with search grounding.

What sets g.jina.ai apart from Gemini’s Search Grounding is that each result includes up to 30 URLs (typically providing at least 10), each accompanied by direct quotes that contribute to the conclusion. Below is an example of grounding the statement, "The latest model released by Jina AI is jina-embeddings-v3," using g.jina.ai (as of Oct. 14, 2024). Explore the API playground to discover the full features. Note that limitations apply:
curl -X POST https://g.jina.ai \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_JINA_TOKEN" \
-d '{
"statement":"the last model released by Jina AI is jina-embeddings-v3"
}'YOUR_JINA_TOKEN is your Jina AI API key. You can get 1M free tokens from our homepage, which allows for about three or four free trials. With the current API pricing of 0.02USD per 1M tokens, each grounding request costs approximately $0.006.
{
"code": 200,
"status": 20000,
"data": {
"factuality": 0.95,
"result": true,
"reason": "The majority of the references explicitly support the statement that the last model released by Jina AI is jina-embeddings-v3. Multiple sources, such as the arXiv paper, Jina AI's news, and various model documentation pages, confirm this assertion. Although there are a few references to the jina-embeddings-v2 model, they do not provide evidence contradicting the release of a subsequent version (jina-embeddings-v3). Therefore, the statement that 'the last model released by Jina AI is jina-embeddings-v3' is well-supported by the provided documentation.",
"references": [
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "arXiv September 18, 2024 jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens.",
"isSupportive": true
},
{
"url": "https://azuremarketplace.microsoft.com/en-us/marketplace/apps/jinaai.jina-embeddings-v3?tab=Overview",
"keyQuote": "jina-embeddings-v3 is a multilingual multi-task text embedding model designed for a variety of NLP applications.",
"isSupportive": true
},
{
"url": "https://docs.pinecone.io/models/jina-embeddings-v3",
"keyQuote": "Jina Embeddings v3 is the latest iteration in the Jina AI’s text embedding model series, building upon Jina Embedding v2.",
"isSupportive": true
},
{
"url": "https://haystack.deepset.ai/integrations/jina",
"keyQuote": "Recommended Model: jina-embeddings-v3 : We recommend jina-embeddings-v3 as the latest and most performant embedding model from Jina AI.",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "The embedding model was trained using 512 sequence length, but extrapolates to 8k sequence length (or even longer) thanks to ALiBi.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "With a standard size of 137 million parameters, the model enables fast inference while delivering better performance than our small model.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "We offer an `encode` function to deal with this.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jinaai/jina-embeddings-v3 Feature Extraction • Updated 3 days ago • 278k • 375",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "the latest version (3.1.0) of [SentenceTransformers] also supports jina-embeddings-v3",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://jina.ai/embeddings/",
"keyQuote": "v3: Frontier Multilingual Embeddings is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model",
"keyQuote": "Jina Embeddings v3: A Frontier Multilingual Embedding Model jina-embeddings-v3 is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model/",
"keyQuote": "As of its release on September 18, 2024, jina-embeddings-v3 is the best multilingual model ...",
"isSupportive": true
}
],
"usage": {
"tokens": 112073
}
}
}The response of of grounding the statement, "The latest model released by Jina AI is jina-embeddings-v3," using g.jina.ai (as of Oct. 14, 2024).
How Does It Work?
At its core, g.jina.ai wraps s.jina.ai and r.jina.ai , adding multi-hop reasoning through Chain of Thought (CoT). This approach ensures that each grounded statement is thoroughly analyzed with the help of online searches and document reading.

s.jina.ai and r.jina.ai, adding CoT for planning and reasoning. Step-by-Step Explanation
Let’s walk through the entire process to better understand how g.jina.ai handles grounding from input to final output:
- Input Statement:
The process begins when a user provides a statement they want to ground, such as "The latest model released by Jina AI is jina-embeddings-v3." Note, there is no need to add any fact-checking instruction before the statement. - Generate Search Queries:
An LLM is employed to generate a list of unique search queries that are relevant to the statement. These queries aim to target different factual elements, ensuring that the search covers all key aspects of the statement comprehensively. - Call
s.jina.aifor Each Query:
For each generated query,g.jina.aiperforms a web search usings.jina.ai. The search results consist of a diverse set of websites or documents related to the queries. Behind the scene,s.jina.aicallsr.jina.aito fetch the page content. - Extract References from Search Results:
From each document retrieved during the search, an LLM extracts the key references. These references include:url: The web address of the source.keyQuote: A direct quote or excerpt from the document.isSupportive: A Boolean value indicating whether the reference supports or contradicts the original statement.
- Aggregate and Trim References:
All the references from the retrieved documents are combined into a single list. If the total number of references exceeds 30, the system selects 30 random references to maintain manageable output. - Evaluate the Statement:
The evaluation process involves using an LLM to assess the statement based on the gathered references (up to 30). In addition to these external references, the model’s internal knowledge also plays a role in the evaluation. The final result includes:factuality: A score between 0 and 1 that estimates the factual accuracy of the statement.result: A Boolean value indicating whether the statement is true or false.reason: A detailed explanation of why the statement is judged as correct or incorrect, referencing the supporting or contradicting sources.
- Output the Result:
Once the statement has been fully evaluated, the output is generated. This includes the factuality score, the assertion of the statement, a detailed reasoning, and a list of references with citations and URLs. The references are limited to the citation, URL, and whether or not they support the statement, keeping the output clear and concise.
Benchmark
We manually collected 100 statements with ground truth labels of either true (62 statements) or false (38 statements) and used different methods to determine if they could be fact-checked. This process essentially converts the task into a binary classification problem, where the final performance is measured by the precision, recall and F1 score—the higher, the better.
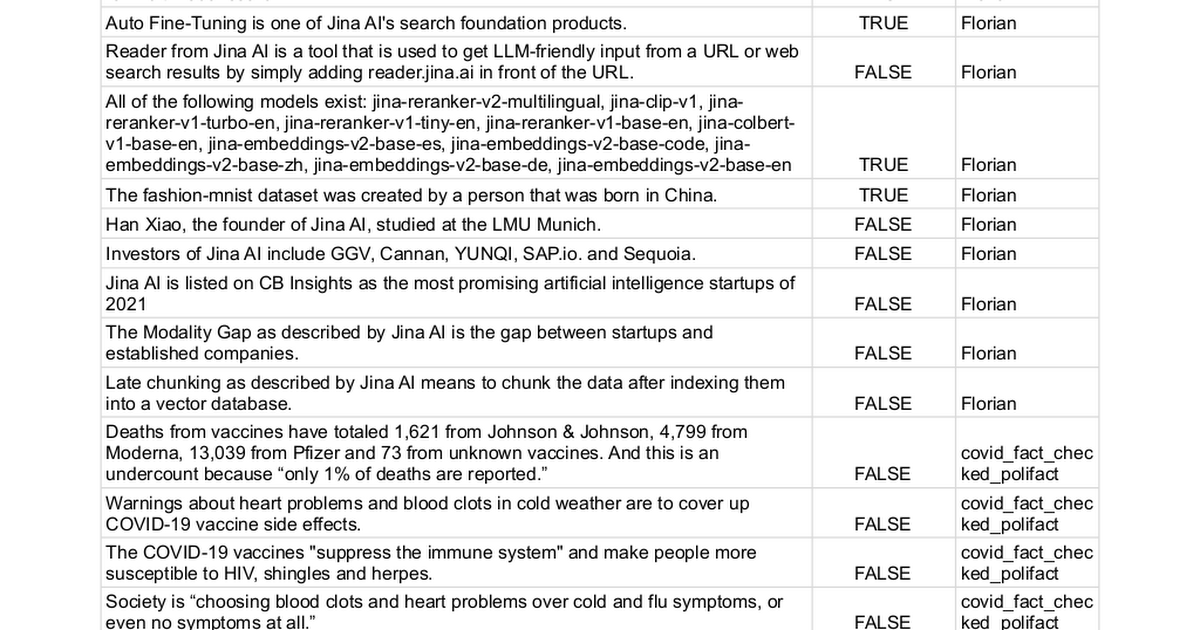
The full list of statements can be found here.
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| Jina AI Grounding API (g.jina.ai) | 0.96 | 0.88 | 0.92 |
| Gemini-flash-1.5-002 w/ grounding | 1.00 | 0.73 | 0.84 |
| Gemini-pro-1.5-002 w/ grounding | 0.98 | 0.71 | 0.82 |
| gpt-o1-mini | 0.87 | 0.66 | 0.75 |
| gpt-4o | 0.95 | 0.58 | 0.72 |
| Gemini-pro-1.5-001 w/ grounding | 0.97 | 0.52 | 0.67 |
| Gemini-pro-1.5-001 | 0.95 | 0.32 | 0.48 |
Note, in practice, some LLMs return a third class, I don’t know, in their predictions. For evaluation, these instances are excluded from the score calculation. This approach avoids penalizing uncertainty as harshly as incorrect answers. Admitting uncertainty is preferred over guessing, to discourage models from making uncertain predictions.
Limitations
Despite the promising results, we’d like to highlight some limitations of the current version of the grounding API:
- High Latency & Token Consumption: A single call to
g.jina.aican take around 30 seconds and use up to 300K tokens, due to the active web search, page reading, and multi-hop reasoning by the LLM. With a free 1M token API key, this means you can only test it about three or four times. To maintain service availability for paid users, we've also implemented a conservative rate limit forg.jina.ai. With our current API pricing of $0.02 per 1M tokens, each grounding request costs approximately 0.006 USD. - Applicability Constraints: Not every statement can or should be grounded. Personal opinions or experiences, such as “I feel lazy,” are not suitable for grounding. Similarly, future events or hypothetical statements do not apply. There are many cases where grounding would be irrelevant or nonsensical. To avoid unnecessary API calls, we recommend users selectively submit only sentences or sections that genuinely require fact-checking. On the server side, we’ve implemented a comprehensive set of error codes to explain why a statement might be rejected for grounding.
- Dependence on Web Data Quality: The accuracy of the grounding API is only as good as the quality of the sources it retrieves. If the search results contain low-quality or biased information, the grounding process might reflect that, potentially leading to inaccurate or misleading conclusions. To prevent this issue, we allow users to manually specify the
referencesparameter and restrict the URLs that the system searches against. This gives users more control over the sources used for grounding, ensuring a more focused and relevant fact-checking process.
Conclusion
The grounding API offers end-to-end, near real-time fact-checking experience. Researchers can use it to find references that support or challenge their hypotheses, adding credibility to their work. In company meetings, it ensures strategies are built on accurate, up-to-date information by validating assumptions and data. In political discussions, it quickly verifies claims, bringing more accountability to debates.
Looking ahead, we plan to enhance the API by integrating private data sources like internal reports, databases, and PDFs for more tailored fact-checking. We also aim to expand the number of sources checked per request for deeper evaluations. Improving multi-hop question-answering will add depth to the analysis, and increasing consistency is a priority to ensure that repeated requests produce more reliable, consistent results.