Finding Optimal Breakpoints in Long Documents Using Small Language Models
We trained three small language models to better segment long documents into chunks, and here are the key lessons we learned.



In our previous posts, we explored the challenges of chunking and introduced the concept of late chunking, which helps reduce context loss when embedding chunks. In this post, we'll focus on another challenge: finding optimal breakpoints. While our late chunking strategy has proven quite resilient to poor boundaries, this doesn't mean we can ignore them—they still matter for both human and LLM readability. Here's our perspective: when determining breakpoints, we can now fully concentrate on readability without worrying about semantic or context loss. Late chunking can handle both good and poor breakpoints, so readability becomes your primary concern.
With this in mind, we trained three small language models specifically designed to segment long documents while maintaining semantic coherence and handling complex content structures. They are:

simple-qwen-0.5, which segments text based on the structural elements of the document.

topic-qwen-0.5, which segments text based on topics within the text.

summary-qwen-0.5, which generates summaries for each segment.
In this post, we’ll discuss why we developed this model, how we approached its three variants, and how they benchmark against Jina AI's Segmenter API. Finally, we'll share what we've learned and some thoughts for the future.
Segmentation Problem
Segmentation is a core element in RAG systems. How we break long documents into coherent, manageable segments directly affects the quality of both retrieval and generation steps, influencing everything from answer relevance to summarization quality. Traditional segmentation methods have produced decent results but aren't without limitations.
To paraphrase our prior post:
When segmenting a long document, a key challenge is deciding where to create the segments. This can be done using fixed token lengths, a set number of sentences, or more advanced methods like regex and semantic segmentation models. Establishing accurate segment boundaries is crucial, as it not only enhances the readability of search results but also ensures that the segments provided to an LLM in a RAG system are both precise and sufficient.
While late chunking enhances retrieval performance, in RAG applications, it's crucial to ensure that, as much as possible, every segment is meaningful on its own, and not just a random chunk of text. LLMs rely on coherent, well-structured data to generate accurate responses. If segments are incomplete or lack meaning, the LLM may struggle with context and accuracy, impacting overall performance despite late chunking’s benefits. In short, whether or not you use late chunking, having a solid segmentation strategy is essential for building an effective RAG system (as you’ll see in the benchmark section further down).
Traditional segmentation methods, whether breaking content at simple boundaries like new lines or sentences, or using rigid token-based rules, often face the same limitations. Both approaches fail to account for semantic boundaries and struggle with ambiguous topics, leading to fragmented segments. To address these challenges, we developed and trained a small language model specifically for segmentation, designed to capture topic shifts and maintain coherence while remaining efficient and adaptable across various tasks.
Why Small Language Model?
We developed a Small Language Model (SLM) to address specific limitations we encountered with traditional segmentation techniques, particularly when handling code snippets and other complex structures like tables, lists, and formulas. In traditional approaches, which often rely on token counts or rigid structural rules, it was difficult to maintain the integrity of semantically coherent content. For instance, code snippets would frequently be segmented into multiple parts, breaking their context and making it harder for downstream systems to understand or retrieve them accurately.
By training a specialized SLM, we aimed to create a model that could intelligently recognize and preserve these meaningful boundaries, ensuring that related elements stayed together. This not only improves the retrieval quality in RAG systems but also enhances downstream tasks like summarization and question-answering, where maintaining coherent and contextually relevant segments is critical. The SLM approach offers a more adaptable, task-specific solution that traditional segmentation methods, with their rigid boundaries, simply cannot provide.
Training SLMs: Three Approaches
We trained three versions of our SLM:
simple-qwen-0.5is the most straightforward model, designed to identify boundaries based on the structural elements of the document. Its simplicity makes it an efficient solution for basic segmentation needs.topic-qwen-0.5, inspired by Chain-of-Thought reasoning, takes segmentation a step further by identifying topics within the text, such as "the beginning of the Second World War," and using these topics to define segment boundaries. This model ensures that each segment is topically cohesive, making it well-suited for complex, multi-topic documents. Initial tests showed that it excels at segmenting content in a way that closely mirrors human intuition.summary-qwen-0.5not only identifies text boundaries but also generates summaries for each segments. Summarizing segments is highly advantageous in RAG applications, especially for tasks like long document question-answering, although it comes with the trade-off of demanding more data when training.
All of the models return only segment heads—a truncated version of each segment. Instead of generating entire segments, the models output key points or subtopics, which improves boundary detection and coherence by focusing on semantic transitions rather than simply copying input content. When retrieving the segments, the document text is split based on those segment heads, and the full segments are reconstructed accordingly.
Dataset
We used the wiki727k dataset, a large-scale collection of structured text snippets extracted from Wikipedia articles. It contains over 727,000 sections of text, each representing a distinct part of a Wikipedia article, such as an introduction, section, or subsection.
 koomri
koomriData Augmentation
To generate training pairs for each model variant, we used GPT-4o to augment our data. For each article in our training dataset, we sent the prompt:
f"""
Generate a five to ten words topic and a one sentence summary for this chunk of text.
```
{text}
```
Make sure the topic is concise and the summary covers the main topic as much as possible.
Please respond in the following format:
```
Topic: ...
Summary: ...
```
Directly respond with the required topic and summary, do not include any other details, and do not surround your response with quotes, backticks or other separators.
""".strip()We used simple splitting to generate sections from each article, splitting on \\n\\n\\n, and then subsplitting on \\n\\n to get the following (in this case, an article on Common Gateway Interface):
[
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
We then generated a JSON structure with the sections, topics and summaries:
{
"sections": [
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
"topics": [
"Common Gateway Interface in Web Servers",
"The History and Standardization of CGI",
"CGI Scripts for Editing Web Pages",
"Reducing Web Server Overhead in Command Invocation"
],
"summaries": [
"CGI provides a protocol for web servers to run programs that generate dynamic web pages.",
"The NCSA initially defined CGI in 1993, leading to its adoption as a standard for Web servers and later formalization in RFC 3875 chaired by Ken Coar.",
"This text describes how a CGI script can handle editing and saving web page content through HTML forms.",
"The text discusses techniques to minimize server overhead from frequent command invocation, including process preforking, using precompiled CGI programs, and implementing custom web server modules."
]
}
We also added noise by shuffling data, adding random characters/words/letters, randomly removing punctuation, and always removing new line characters.
All of that can go part of the way to developing a good model - but only so far. To really pull out all the stops we needed the model to create coherent chunks without breaking down code snippets. To do this, we augmented the dataset with code, formulae, and lists generated by GPT-4o.
The Training Setup
For training the models, we implemented the following setup:
- Framework: We used Hugging Face’s
transformerslibrary integrated withUnslothfor model optimization. This was crucial for optimizing memory usage and speeding up training, making it feasible to train small models with large datasets effectively. - Optimizer and Scheduler: We used the AdamW optimizer with a linear learning rate schedule and warm-up steps, allowing us to stabilize the training process during the initial epochs.
- Experiment Tracking: We tracked all training experiments using Weights & Biases, and logged key metrics like training and validation loss, learning rate changes, and overall model performance. This real-time tracking provided us with insights into how the models were progressing, enabling quick adjustments when necessary to optimize learning outcomes.
The Training Itself
Using qwen2-0.5b-instruct as a base model, we trained three variations of our SLM with Unsloth, each with a different segmentation strategy in mind. For our samples we used training pairs, consisting of the text of an article from wiki727k and the resulting sections, topics, or summaries (mentioned above in the “Data Augmentation” section) depending on the model being trained.
simple-qwen-0.5: We trainedsimple-qwen-0.5on 10,000 samples with 5,000 steps, achieving fast convergence and effectively detecting boundaries between cohesive sections of text. The training loss was 0.16.topic-qwen-0.5: Likesimple-qwen-0.5, we trainedtopic-qwen-0.5on 10,000 samples with 5,000 steps, achieving a training loss of 0.45.summary-qwen-0.5: We trainedsummary-qwen-0.5on 30,000 samples with 15,000 steps. This model showed promise but had a higher loss (0.81) during training, suggesting the need for more data (around double our original sample count) to reach its full potential.
The Segments Themselves
Here are examples of three consecutive segments from each segmentation strategy, along with Jina’s Segmenter API. To produce these segments we first used Jina Reader to scrape a post from the Jina AI blog as plain text (including all page data, like headers, footers, etc), then passed it to each segmentation method.

Jina Segmenter API
Jina Segmenter API took a very granular approach to segmenting the post, splitting on characters like \n, \t, etc, to break the text into often very small segments. Just looking at the first three, it extracted search\\n, notifications\\n and NEWS\\n from the website’s navigation bar, but nothing relevant to the post content itself:

Further on, we at last got some segments from the actual blog post content, though little context was retained in each:

(In the interests of fairness, we showed more chunks for Segmenter API than for the models, simply because otherwise it would have very few meaningful segments to show)
simple-qwen-0.5
simple-qwen-0.5 broke the blog post down based on semantic structure, extracting much longer segments that had a cohesive meaning:
topic-qwen-0.5
topic-qwen-0.5 first identified topics based on the document’s content, then segmented the document based on those topics:
summary-qwen-0.5
summary-qwen-0.5 identified segment boundaries and generated a summary of the content within each segment:
Benchmarking the Models
To benchmark the performance of our models, we scraped eight blog posts from the Jina AI blog and generated six questions and ground truth answers using GPT-4o.
We applied each segmentation method, including Jina Segmenter API, to these blog posts, and then generated embeddings for the resulting segments using jina-embeddings-v3, without late chunking or reranking.

Each set of segments was then indexed separately and we used a RAG system to query each index with the previously generated questions.
topic-qwen-0.5 and summary-qwen-0.5 we indexed only the segments themselves, not the generated summaries or topics. Indexing this additional data would likely further improve performance.To measure performance, we compared the answers generated from each segmentation method’s index with the ground truth answers using F1 scores from the ROUGE-L evaluation, where higher scores indicate better performance.
For example, given the question: “What factors impact the numerical comparison abilities of the jina-embeddings-v2-base-en model?”, we received the following answers:
Ground Truth (Generated by GPT-4o from The Full Post Text):
"The two key factors are tokenization and training data. Tokenization determines how numbers are segmented into tokens, and training data influences numerical reasoning abilities."
Jina Segmenter API (score: 0.166667)
"The context does not provide specific factors that impact the numerical comparison abilities of the jina-embeddings-v2-base-en model."
simple-qwen-0.5 (score: 0.279070)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by tokenization and training data."
topic-qwen-0.5 (score: 0.190476)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by factors such as tokenization and its ability to handle different numerical formats, including small integers, large numbers, floats, negative numbers, currency, dates, and times."
summary-qwen-0.5 (0.318182)
"The factors impacting the numerical comparison abilities of the jina-embeddings-v2-base-en model are tokenization and training data."
topic-qwen-0.5's score so low?This is mostly just a fluke based on the particular question we asked the model. As you can see in the table below,
topic-qwen-0.5's average ROUGE score is the highest of all the segmenting methodologies.We also evaluated the speed of each method (by timing how long it took to both generate and embed segments) and estimated disk space (by multiplying embeddings count by size of a single 1024-dimension embedding from jina-embeddings-v3). This allowed us to assess both accuracy and efficiency across the different segmentation strategies.
Key Findings
After testing the model variants against each other and Jina's Segmenter API, we realized that the new models did in fact show improved scores using all three methods, especially topic segmentation:
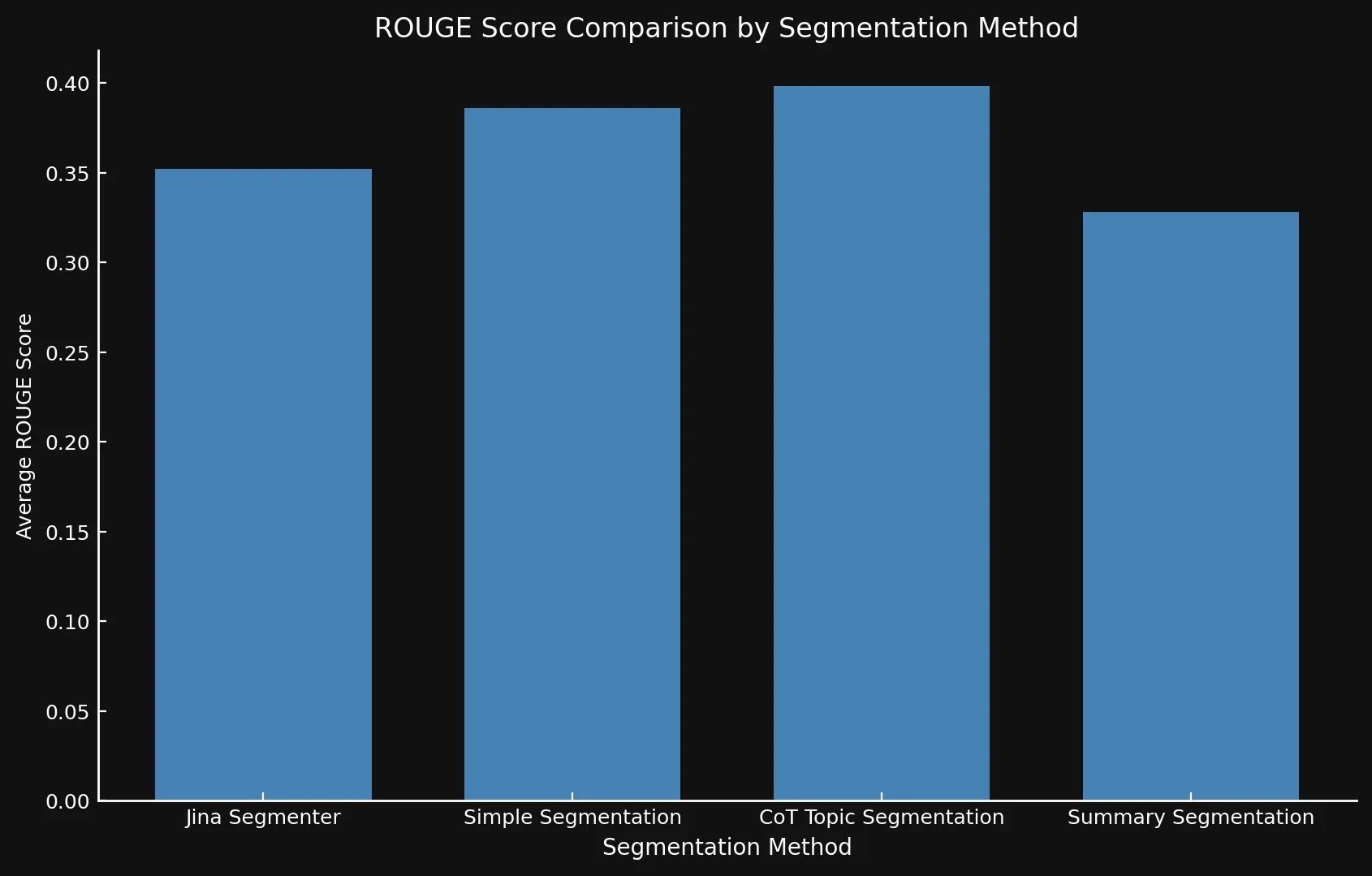
| Segmentation Method | Average ROUGE Score |
|---|---|
| Jina Segmenter | 0.352126 |
simple-qwen-0.5 |
0.386096 |
topic-qwen-0.5 |
0.398340 |
summary-qwen-0.5 |
0.328143 |
summary-qwen-0.5 have a lower ROUGE score than topic-qwen-0.5? In short, summary-qwen-0.5 showed a higher loss during training, revealing the need for more training to receive better results. That may be a subject for future experimentation.However, it would be interesting to review the results with the late chunking feature of jina-embeddings-v3, which increases the context relevance of segment embeddings, providing more relevant results. That may be a topic for a future blog post.
Regarding speed, it can be difficult to compare the new models to Jina Segmenter, since the latter is an API, while we ran the three models on an Nvidia 3090 GPU. As you can see any performance gained during the Segmenter API’s speedy segmenting step is swiftly overtaken by the need to generate embeddings for so many segments:
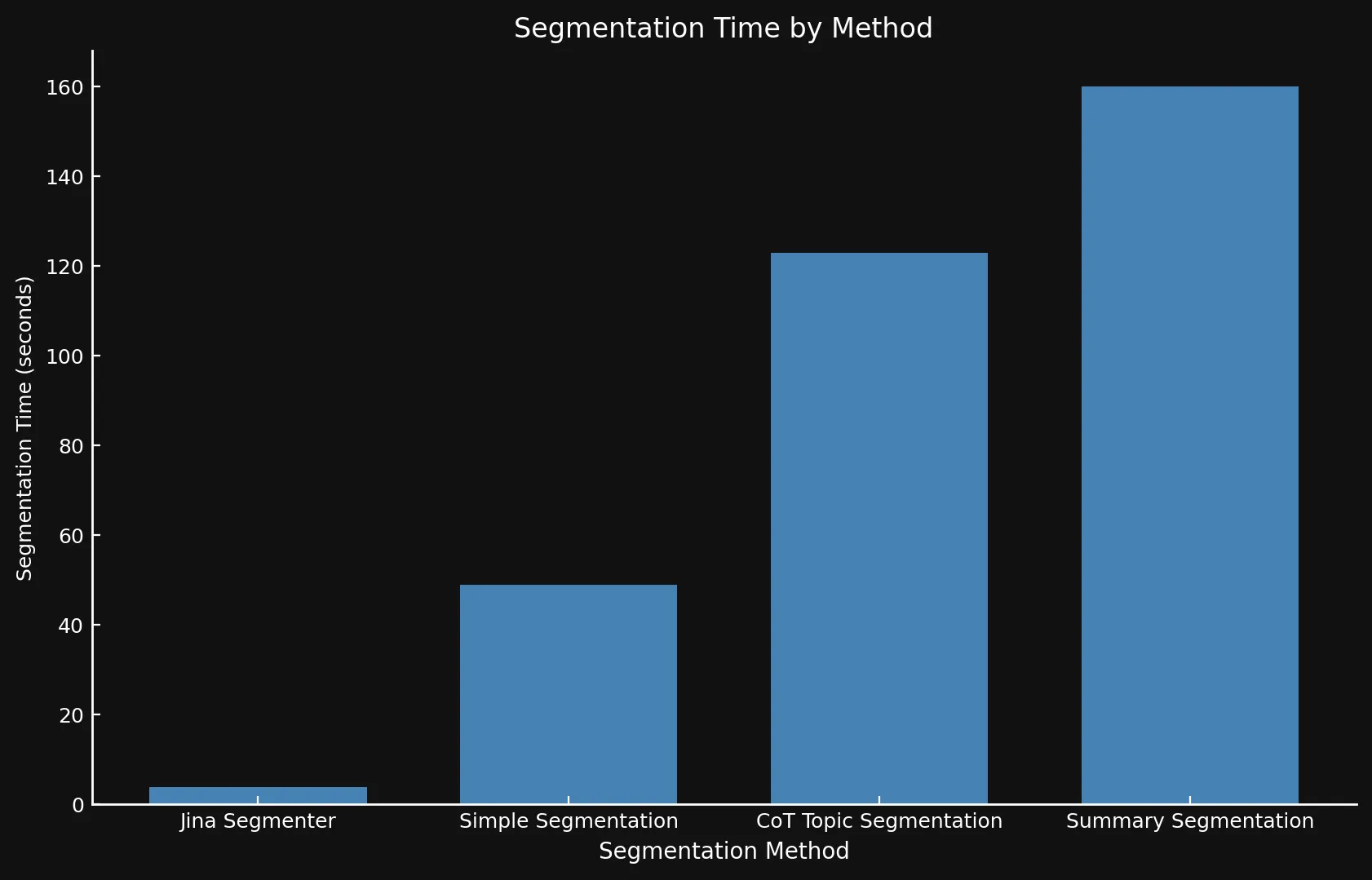
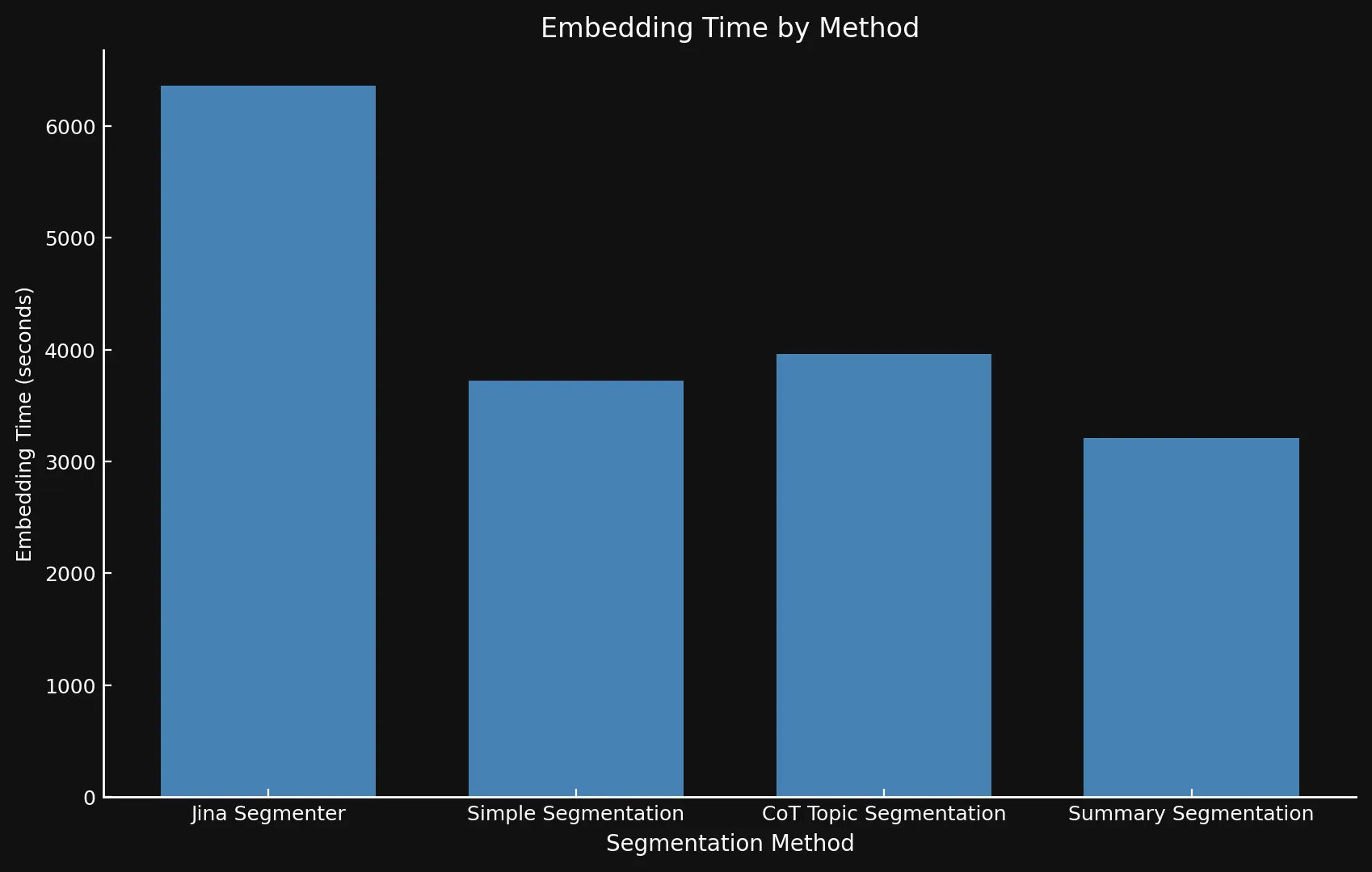
• We use different Y-axis on both graphs because presenting such different timeframes with one graph or consistent Y-axes was not feasible.
• Since we were performing this purely as an experiment, we didn’t use batching when generating embeddings. Doing so would substantially speed up operations for all methods.
Naturally, more segments means more embeddings. And those embeddings take up a lot of space: The embeddings for the eight blog posts we tested on took up over 21 MB with Segmenter API, while Summary Segmentation came in at a svelte 468 KB. This, plus the higher ROUGE scores from our models mean fewer segments but better segments, saving money and increasing performance:
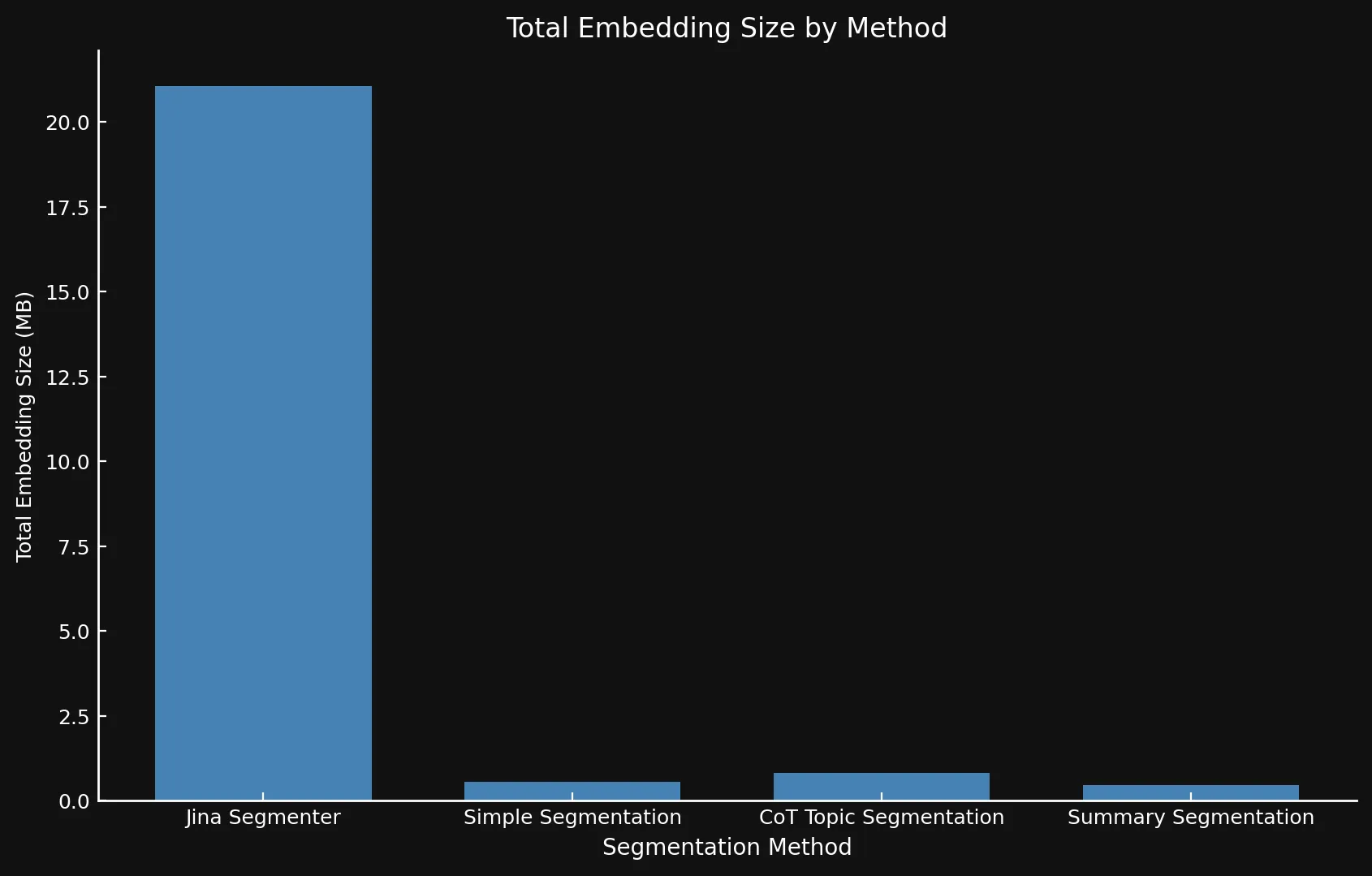
| Segmentation Method | Segment Count | Average Length (characters) | Segmentation Time (minutes/seconds) | Embedding Time (hours/minutes) | Total Embedding Size |
|---|---|---|---|---|---|
| Jina Segmenter | 1,755 | 82 | 3.8s | 1h 46m | 21.06 MB |
simple-qwen-0.5 |
48 | 1,692 | 49s | 1h 2m | 576 KB |
topic-qwen-0.5 |
69 | 1,273 | 2m 3s | 1h 6m | 828 KB |
summary-qwen-0.5 |
39 | 1,799 | 2m 40s | 53m | 468 KB |
What We Learned
Problem Formulation is Critical
One key insight was the impact of how we framed the task. By having the model output segment heads, we improved boundary detection and coherence by focusing on semantic transitions rather than simply copy-pasting the input content into separate segments. This also resulted in a faster segmentation model, as generating less text allowed the model to complete the task more quickly.
LLM-Generated Data is Effective
Using LLM-generated data, particularly for complex content like lists, formulas, and code snippets, broadened the model’s training set and improved its ability to handle diverse document structures. This made the model more adaptable across varied content types, a crucial advantage when dealing with technical or structured documents.
Output-Only Data Collation
By using an output-only data collator, we ensured that the model focused on predicting the target tokens during training, rather than merely copying from the input. The output-only collator ensured the model learned from the actual target sequences, emphasizing the correct completions or boundaries. This distinction allowed the model to converge faster by avoiding overfitting to the input and helped it generalize better across different datasets.
Efficient Training with Unsloth
With Unsloth, we streamlined the training of our small language model, managing to run it on an Nvidia 4090 GPU. This optimized pipeline allowed us to train an efficient, performant model without the need for massive computational resources.
Handling Complex Texts
The segmentation models excelled at handling complex documents containing code, tables, and lists, which are typically difficult for more traditional methods. For technical content, sophisticated strategies like topic-qwen-0.5 and summary-qwen-0.5 were more effective, with the potential to enhance downstream RAG tasks.
Simple Methods for Simpler Content
For straightforward, narrative-driven content, simpler methods like the Segmenter API are often sufficient. Advanced segmentation strategies may only be necessary for more complex, structured content, allowing for flexibility depending on the use case.
Next Steps
While this experiment was designed primarily as a proof of concept, if we were to extend it further, we could make several enhancements. First, although continuation of this specific experiment is unlikely, training summary-qwen-0.5 on a larger dataset—ideally 60,000 samples instead of 30,000—would likely lead to more optimal performance. Additionally, refining our benchmarking process would be beneficial. Instead of evaluating the LLM-generated answers from the RAG system, we would focus instead on comparing the retrieved segments directly to the ground truth. Finally, we would move beyond ROUGE scores and adopt more advanced metrics (possibly a combination of ROUGE and LLM scoring) that better capture the nuances of retrieval and segmentation quality.
Conclusion
In this experiment, we explored how custom segmentation models designed for specific tasks can enhance the performance of RAG. By developing and training models like simple-qwen-0.5, topic-qwen-0.5, and summary-qwen-0.5, we addressed key challenges found in traditional segmentation methods, particularly with maintaining semantic coherence and effectively handling complex content like code snippets. Among the models tested, topic-qwen-0.5 consistently delivered the most meaningful and contextually relevant segmentation, especially for multi-topic documents.
While segmentation models provide the structural foundation necessary for RAG systems, they serve a different function compared to late chunking, which optimizes retrieval performance by maintaining contextual relevance across segments. These two approaches can be complementary, but segmentation is particularly crucial when you need a method that focuses on splitting documents for coherent, task-specific generation workflows.