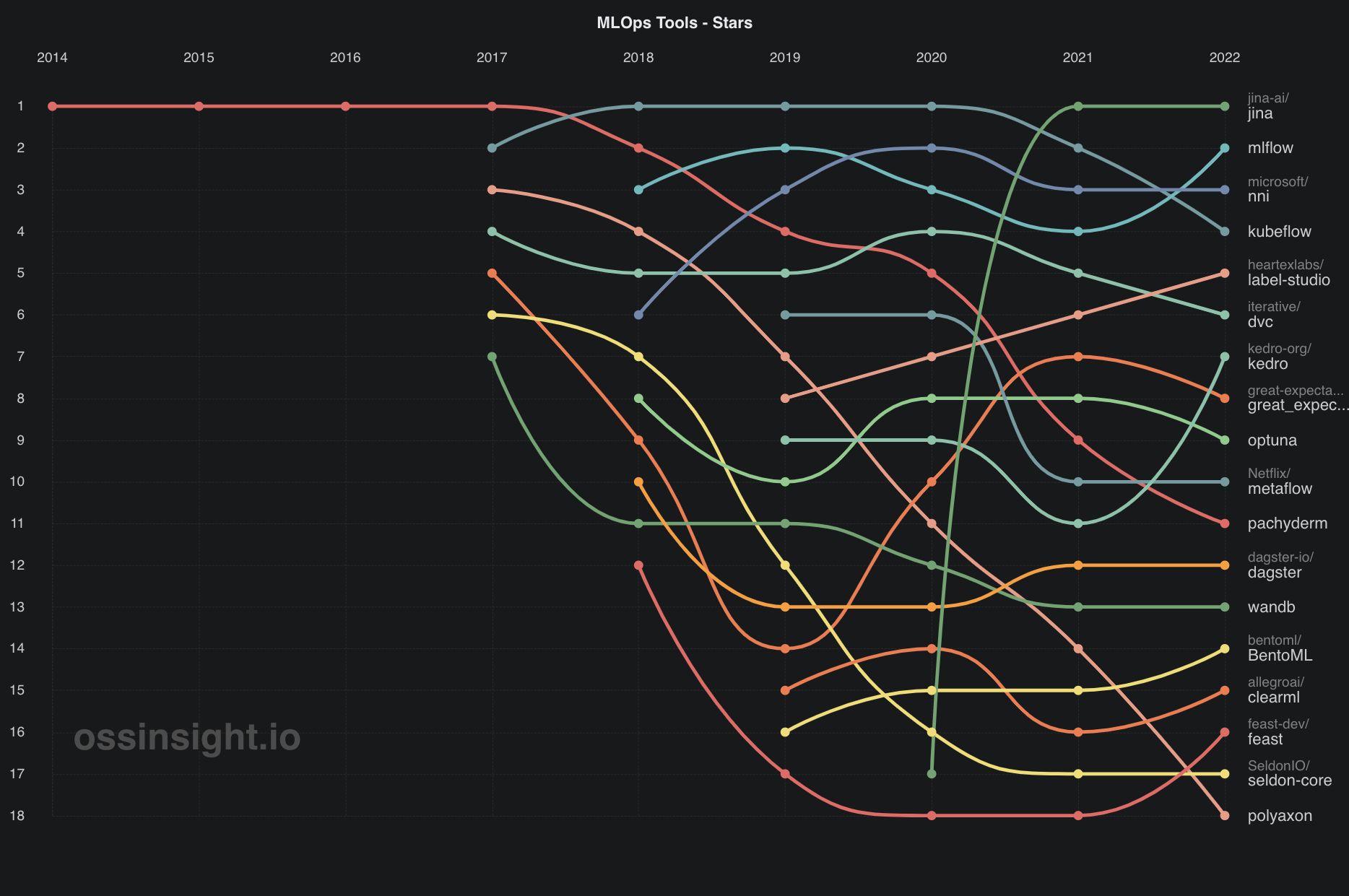
5 Most Trending Open Source MLOps Tools of 2022
MLOps helps organizations better manage the complexities of ML in production. This article reviews the top-5 most trending open source MLOps tools listed on OSSInsight.io in 2022.


MLOps, or DevOps for machine learning, is a set of practices that aim to automate and improve the collaboration between data scientists and software engineers. It helps organizations better manage the complexities of developing and deploying machine learning models in production. In this article, we will review the top-5 most trending open source MLOps tools listed on OSSInsight.io in 2022.
Benefits of MLOps
One of the biggest benefits of MLOps is that it allows data scientists and engineers to work more closely together. Data scientists can focus on developing models, while engineers can focus on operationalizing them. This collaboration helps to ensure that models are deployed quickly and efficiently and that they meet the needs of the business.
Another benefit of MLOps is that it helps to automate the process of model development and deployment. This means that data scientists can spend less time on repetitive tasks, and more time on developing new models. Automation also helps to ensure that models are deployed consistently and with high quality.
Common Practices in MLOps
MLOps is still a relatively new field (as we shall see below, all five tools were first released in 2018), and there is no one-size-fits-all approach to implementing it. However, some common practices are often used. One common practice is to use pipelines. These pipelines help to automate the process of building, testing and deploying machine learning models.
Another common practice is to use containerization technologies, such as Docker, to package machine learning models. This allows models to be easily deployed in different environments.
Finally, many MLOps practitioners use monitoring and logging tools to keep track of the performance of machine learning models in production. This allows for the early detection of issues and can help to improve the overall quality of the models.
Best 5 MLOps Tools in 2022
Implementing MLOps can be a challenge, but the benefits are clear. Organizations that adopt MLOps practices can improve the quality of their machine learning models and speed up the development and deployment process. In this article, we select the top-5 most trending open source MLOps tools in 2022 listed on OSSInsight.io, namely Jina (No.1), MLFlow (No.2), NNI (No.3), Kubefliow (No.4) and Label Studio (No.5). The rank is based on the stars, pull requests, pull request creators, and issues on the Github in 2022. OSSInsight is a powerful insight tool that can help one analyze in depth any single GitHub repository/developers, compare any two repositories using the same metrics, and provide comprehensive, valuable, and trending open source insights.
1. Jina
 jina-ai
jina-ai| First Release | Stars | Commits | Issues | PR creators | Language |
|---|---|---|---|---|---|
| April 2020 | 16952 | 24607 | 1521 | 229 | Python |
Jina from Jina AI is the top-1 most trending MLOps tool according to OSSInsight. Jina is an MLOps framework for multimodal AI. It eases the building of neural search and creative AI on the cloud. Jina uplifts a PoC into a production-ready service. Jina handles the infrastructure complexity, making advanced solution engineering and cloud-native technologies accessible to every developer.

Despite the advanced cloud-native features that Jina offers, learning Jina is very straightforward. Document, Executor, and Flow are three fundamental concepts in Jina.
- Document is the fundamental data structure. (This project is also an opensource project by the Linux Foundation)
- Executor is a Python class with functions that use Documents as IO.
- Flow ties Executors together into a pipeline and exposes it with an API gateway.
With these three concepts, one can easily build a semantic text search with sharding technology in just 45 lines of code!
from pprint import pprint
from jina import Flow, requests, DocumentArray, Document, Executor
class MyFeature(Executor):
@requests
async def foo(self, docs, **kwargs):
docs.apply(Document.embed_feature_hashing)
class MyDB(Executor):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.db = DocumentArray()
@requests(on='/index')
def index(self, docs, **kwargs):
self.db.extend(docs)
@requests(on='/query')
def query(self, docs, **kwargs):
return self.db.find(docs, metric='jaccard', use_scipy=True)[0][:3]
class MyRanker(Executor):
@requests(on='/query')
async def foo(self, docs, **kwargs):
return DocumentArray(sorted(docs, key=lambda x: x.scores['jaccard'].value))
d = Document(uri='https://www.gutenberg.org/files/1342/1342-0.txt').load_uri_to_text()
da = DocumentArray(Document(text=s.strip()) for s in d.text.split('\n') if s.strip())
if __name__ == '__main__':
f = (
Flow()
.add(uses=MyFeature)
.add(uses=MyDB, shards=3, polling={'/query': 'ALL', '/index': 'ANY'})
.add(uses=MyRanker)
)
with f:
f.post('/index', da, show_progress=True)
pprint(
f.post('/query', Document(text='she smiled too much'))[
:, ('text', 'scores__jaccard__value')
]
)
With Executor Hub, one can easily use LLMs or pretrained models on Hugging Face to embed Documents. However, in practice the performance is often suboptimal without proper domain adoption or knowledge transferring. Fine-tuning is an effective solution to improve the performance on neural search and embedding-related tasks. Jina AI also provides Finetuner tools makes fine-tuning easier, faster and performant by streamlining the workflow and handling all complexity and infrastructure on the cloud.
Finally, Jina AI also offers a hosting service for Jina projects, allowing one to deploy CPU/GPU-based Jina Flow with auto-provisioning in Kubernetes. It is in public beta and the hosting is for free at the moment.

2. MLFlow
mlflow| First Release | Stars | Commits | Issues | PR creators | Language |
|---|---|---|---|---|---|
| June 2018 | 12817 | 4948 | 2503 | 661 | Python |
MLflow is the No.2 on the trending board. Unlike Jina which specializes on the neural search and multimodal AI applications, MLflow is a more general platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. It offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
- MLflow Tracking: An API to log parameters, code, and results in machine learning experiments and compare them using an interactive UI.
- MLflow Projects: A code packaging format for reproducible runs using Conda and Docker, so you can share your ML code with others.
- MLflow Models: A model packaging format and tools that let you easily deploy the same model (from any ML library) to batch and real-time scoring on platforms such as Docker, Apache Spark, Azure ML and AWS SageMaker.
- MLflow Model Registry: A centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of MLflow Models.
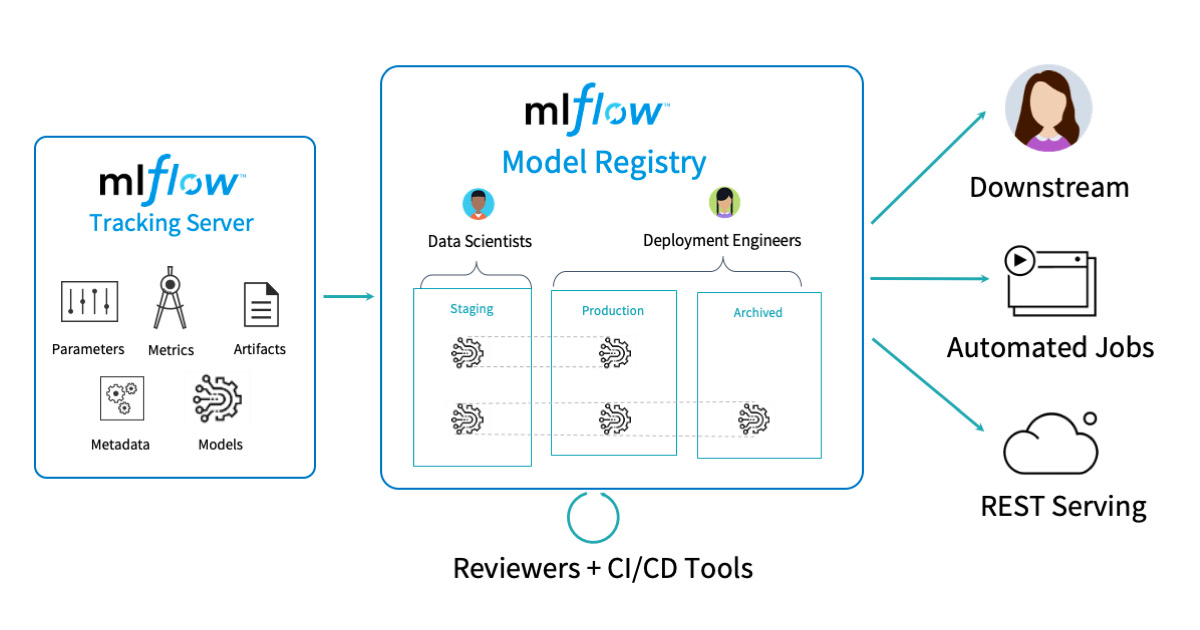
MLflow Projects provide a standard format for packaging reusable data science code. Each project is simply a directory with code or a Git repository, and uses a descriptor file to specify its dependencies and how to run the code. A MLflow Project is defined by a simple YAML file called MLproject.
name: My Project
conda_env: conda.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
Projects can specify their dependencies through a Conda environment. A project may also have multiple entry points for invoking runs, with named parameters. You can run projects using the mlflow run command-line tool, either from local files or from a Git repository:
mlflow run example/project -P alpha=0.5
mlflow run git@github.com:databricks/mlflow-example.git -P alpha=0.5
MLflow will automatically set up the right environment for the project and run it.
3. NNI
microsoft| First Release | Stars | Commits | Issues | PR creators | Language |
|---|---|---|---|---|---|
| Sept. 2018 | 12508 | 18653 | 1745 | 206 | Python |
Microsoft NNI (Neural Network Intelligence) is a lightweight but powerful toolkit to help users automate feature engineering, neural architecture search, hyperparameter tuning, and model compression for deep learning. NNI eases the effort to scale and manage AutoML experiments.
Unlike Jina which focuses more on inference, NNI focuses on model training and experimenting. It provides powerful and easy-to-use APIs for facilitating advanced training such as AutoML. Automatic neural architecture search is playing an increasingly important role in finding better models. Recent research has proven the feasibility of automatic NAS and has led to models that beat many manually designed and tuned models. Representative works include NASNet, ENAS, DARTS, Network Morphism, and Evolution.
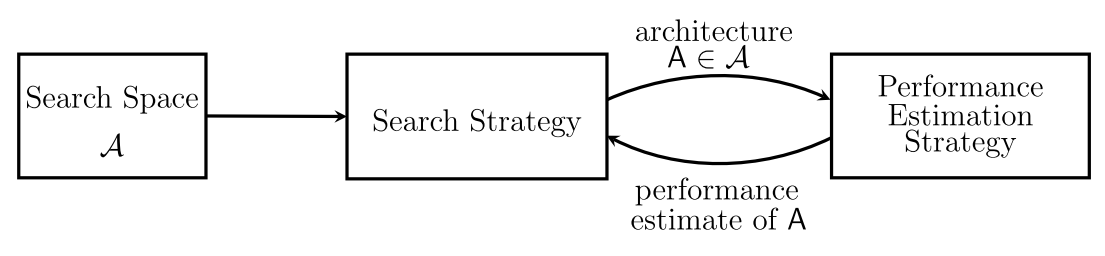
In general, neural architecture search typically consists of three tasks: search space design, search strategy selection, and performance evaluation. These tasks are non-trivial by individual, but can be easily solved in NNI:
# define model space
class Model(nn.Module):
self.conv2 = nn.LayerChoice([
nn.Conv2d(32, 64, 3, 1),
DepthwiseSeparableConv(32, 64)
])
model_space = Model()
# search strategy + evaluator
strategy = RegularizedEvolution()
evaluator = FunctionalEvaluator(
train_eval_fn)
# run experiment
RetiariiExperiment(model_space,
evaluator, strategy).run()4. Kubeflow
kubeflow| First Release | Stars | Commits | Issues | PR creators | Language |
|---|---|---|---|---|---|
| Nov. 2017 | 12171 | 2641 | 3575 | 367 | Python + Go |
Kubeflow is the machine learning toolkit for Kubernetes. It started as an open sourcing of the way Google ran Tensorflow internally. It began as just a simpler way to run TensorFlow jobs on Kubernetes, but has since expanded to be a multi-architecture, multi-cloud framework for running end-to-end machine learning workflows.

Kubeflow is dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable. The goal is not to recreate other services, but to provide a straightforward way to deploy best-of-breed open-source systems for ML to diverse infrastructures. Anywhere you are running Kubernetes, you should be able to run Kubeflow.
Compared to Jina, MLFlow, and NNI, Kubeflow covers the most complete ML lifecycle including:
- Training
- AutoML
- Deployment
- Serving
- Pipelines
- Manifests
- Notebooks
Kubeflow pipeline also covers more comparing to Jina "Flow" and MLFlow "Project" concepts. Kubeflow Pipelines is a platform for building and deploying portable, scalable machine learning (ML) workflows based on Docker containers. Specifically, it consists of:
- A user interface (UI) for managing and tracking experiments, jobs, and runs.
- An engine for scheduling multi-step ML workflows.
- An SDK for defining and manipulating pipelines and components.
- Notebooks for interacting with the system using the SDK.
5. Label Studio
heartexlabs| First Release | Stars | Commits | Issues | PR creators | Language |
|---|---|---|---|---|---|
| July 2019 | 11105 | 8396 | 1167 | 136 | Python + Go |
Label Studio is an open source tool from Heartex that focuses on an early but important stage of the ML lifecycle: data annotation.
Data annotation is the process of adding labels to data sets so that they can be used to train machine learning models. There are a few reasons why data annotation is so important. First, it allows for better-quality data sets. If data sets are not labeled, they can be more difficult for machine learning models to learn from. Second, data annotation can help to speed up the training process. And third, data annotation can improve the results of machine learning models by making them more accurate. Data annotation is usually done by hand, which can be a time-consuming and expensive process.
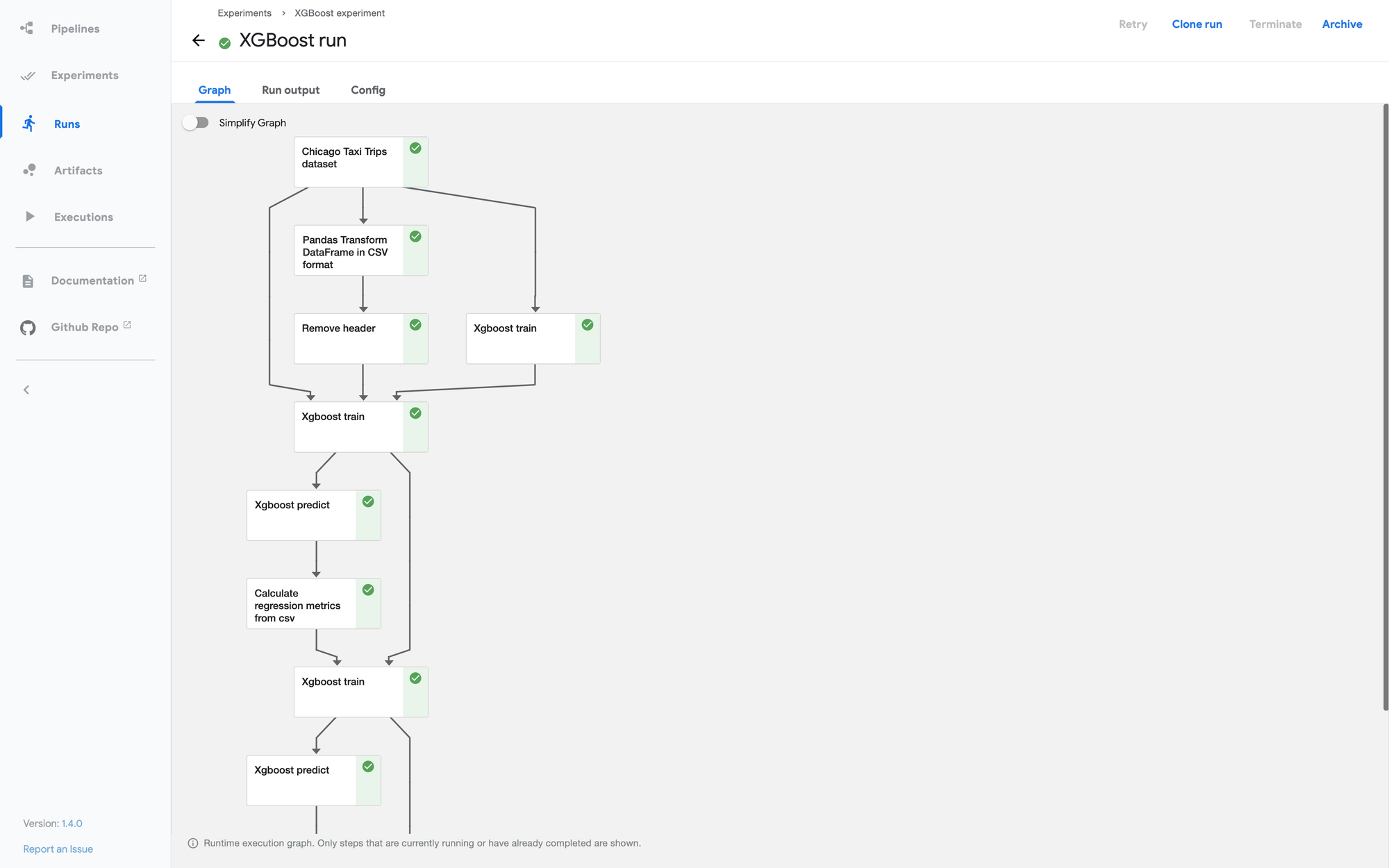
Label Studio lets you label data types like audio, text, images, videos, and time series with a simple UI and export them to various model formats. It can be used to prepare raw data or improve existing training data to get more accurate ML models.
You can also integrate Label Studio with machine learning models to supply predictions for labels (pre-labels), or perform continuous active learning. The Label Studio ML backend is an SDK that lets you wrap your machine learning code and turn it into a web server. You can then connect that server to a Label Studio instance to perform 2 tasks:
- Dynamically pre-annotate data based on model inference results
- Retrain or fine-tune a model based on recently annotated data
For example, to initialize an ML backend based on an example script:
label-studio-ml init my_ml_backend --script label_studio_ml/examples/simple_text_classifier/simple_text_classifier.py
label-studio-ml start my_ml_backendAfter you define the loaders, you can define two methods for your model: an inference call and a training call.
One can use an inference call to get pre-annotations from your model on-the-fly. You must update the existing predict method in the example ML backend scripts to make them work for your specific use case.
def predict(self, tasks, **kwargs):
predictions = []
# Get annotation tag first, and extract from_name/to_name keys from the labeling config to make predictions
from_name, schema = list(self.parsed_label_config.items())[0]
to_name = schema['to_name'][0]
for task in tasks:
# for each task, return classification results in the form of "choices" pre-annotations
predictions.append({
'result': [{
'from_name': from_name,
'to_name': to_name,
'type': 'choices',
'value': {'choices': ['My Label']}
}],
# optionally you can include prediction scores that you can use to sort the tasks and do active learning
'score': 0.987
})
return predictionsWrite your own training call to update your model with new annotations, by overriding the fit(annotations, **kwargs) method, which takes JSON-formatted Label Studio annotations and returns an arbitrary dict where some information about the created model can be stored.
def fit(self, completions, workdir=None, **kwargs):
# ... do some heavy computations, get your model and store checkpoints and resources
return {'checkpoints': 'my/model/checkpoints'} # <-- you can retrieve this dict as self.train_output in the subsequent calls
After you wrap your model code with the class, define the loaders, and define the methods, you're ready to run your model as an ML backend with Label Studio.
Hard to deny that the success of any machine learning model depends heavily on the quality of the data it is trained on. This explains why Label Studio is trending in 2022 and playes a crucial role in MLOps.
MLOps Adoption Inside Companies
In the past year, we've seen a number of companies adopting MLOps practices, and the trend is only accelerating. We see more companies adopting MLOps practices and sharing their experiences. In particular, there are two main approaches to MLOps: the centralized approach and the decentralized approach.
The centralized approach is typified by companies like Google and Facebook, who have centralized teams that are responsible for developing and managing the entire ML pipeline. The decentralized approach is typified by companies like Amazon and Netflix, who have decentralized teams that each manage a part of the ML pipeline.
- The centralized approach has the advantage of being able to develop and manage the entire ML pipeline in-house, which allows for greater control and transparency. The disadvantage of the centralized approach is that it can be very siloed, with different teams working in isolation from each other.
- The decentralized approach has the advantage of being able to move faster and be more agile since each team is only responsible for a part of the ML pipeline. The disadvantage of the decentralized approach is that it can be less transparent and more difficult to track down issues.
In 2022, the best MLOps setups have a mix of both centralized and decentralized approaches, depending on the needs of the company. For example, a company might have a centralized team responsible for developing the ML algorithms, and a decentralized team responsible for training and deploying the models.
Moving Forward to 2023
In 2023, we expect to see more companies adopting MLOps practices, and the benefits of MLOps will become even more apparent. Especially with the paradigm shift of multimodal AI, more text, image, video, or even 3D mesh data are available, we will see datasets becoming more complex, and the need for automated data pipelines and machine learning management processes will become more critical.

In 2023, the most successful MLOps setups will be the ones that can strike the right balance between people, process, and tooling. We anticipate that the most popular open source MLOps tools will be those that provide easy-to-use interfaces and allow for customizations to fit specific needs. The tools and platforms mentioned in this article will continue to evolve and become more user-friendly, making them accessible to a wider range of users. We also expect to see new platforms emerge, as well as new features and capabilities being added to existing platforms.
In terms of specific tools, we think that version control tools will become increasingly important for managing ML code and models. Data annotation and labeling tools will also gain popularity, as the need for high-quality training data becomes more apparent. And finally, model management tools will become essential for managing the various machine learning models that are deployed in production. Overall, we expect the MLOps landscape to become more diverse, with a wider range of tools available to meet the needs of different organizations.
In 2023, MLOps will be an essential part of any company that wants to stay competitive in the ever-changing world of machine learning. So if you're thinking about adopting MLOps, now is the time to do it. The benefits are clear, and the future looks very bright for MLOps.