How to Personalize Stable Diffusion for ALL the Things
Jina AI's BIG metamodel lets you fine-tune Stable Diffusion to the next level, creating images of multiple subjects in any style you want




Jina AI is really into generative AI. It started out with DALL·E Flow, swiftly followed by DiscoArt. And then…🦗🦗<cricket sounds>🦗🦗. At least for a while…
That while has ended. We’re Back In the Game, baby. Big time, with our new BIG metamodel. You might be wondering: What’s so meta about it? Before you needed multiple Stable Diffusion models, but now with BIG you have one model for everything.
In short, BIG lets you fine-tune Stable Diffusion to the next level, letting you create images of multiple subjects and in any style you want. That means you can take a picture of you and a picture of your pooch and combine them into a composite image in the style of Picasso, Pixar or pop art.
We created BIG by taking the DreamBooth paper, which allows fine-tuning with one subject, and leveling it up it into a metamodel to learn multiple new objects without using up all your compute. In this blog post we’ll go over how we did that, and how well it works.
But first, let’s take a quick look at how we got here, by starting off with Stable Diffusion itself.
Stable Diffusion: Fine-tune to your favorite artist (but forget everyone else)
In the beginning there was Stable Diffusion and it was good. “Create a Banksy picture” you would say, and verily a Banksy would be created. “Create an artwork in the style of Picasso” you would exclaim. And verily an image of a woman with too many angles would be created.
“Generate an image in the style of Leon Löwentraut” you proclaim. And Stable Diffusion did say “uh, what? lol I’ll give it my best. And verily it was rubbish.
Luckily, this can be fixed by fine-tuning (yeah, we’re dropping the Biblical speak). If you feed Stable Diffusion a Leon Löwentraut image it can learn his style (using, for example, text-to-image fine-tuning for Stable Diffusion.)


The only problem is it gets amnesia for everything else it’s learned before. So if you then try to create the style of Banksy or Picasso on your newly fine-tuned model they all turn out pretty Löwentrautian:


a banksy painting, before fine-tuning; Right: Generated images for prompt a banksy painting, after fine-tuning to Löwentraut.

a picasso painting, before fine-tuning; Right: Generated image for prompt a picasso painting, after fine-tuning to LöwentrautDreamBooth: Fine-tune to your favorite artist (and remember!)
DreamBooth fixes that. At least to a point. You want to train it for your dog? Piece of cake. Fine-tune it for your favorite artist? A walk in the park. And Mona Lisa would still look like it came from Leonardo and Starry Night from Van Gogh.
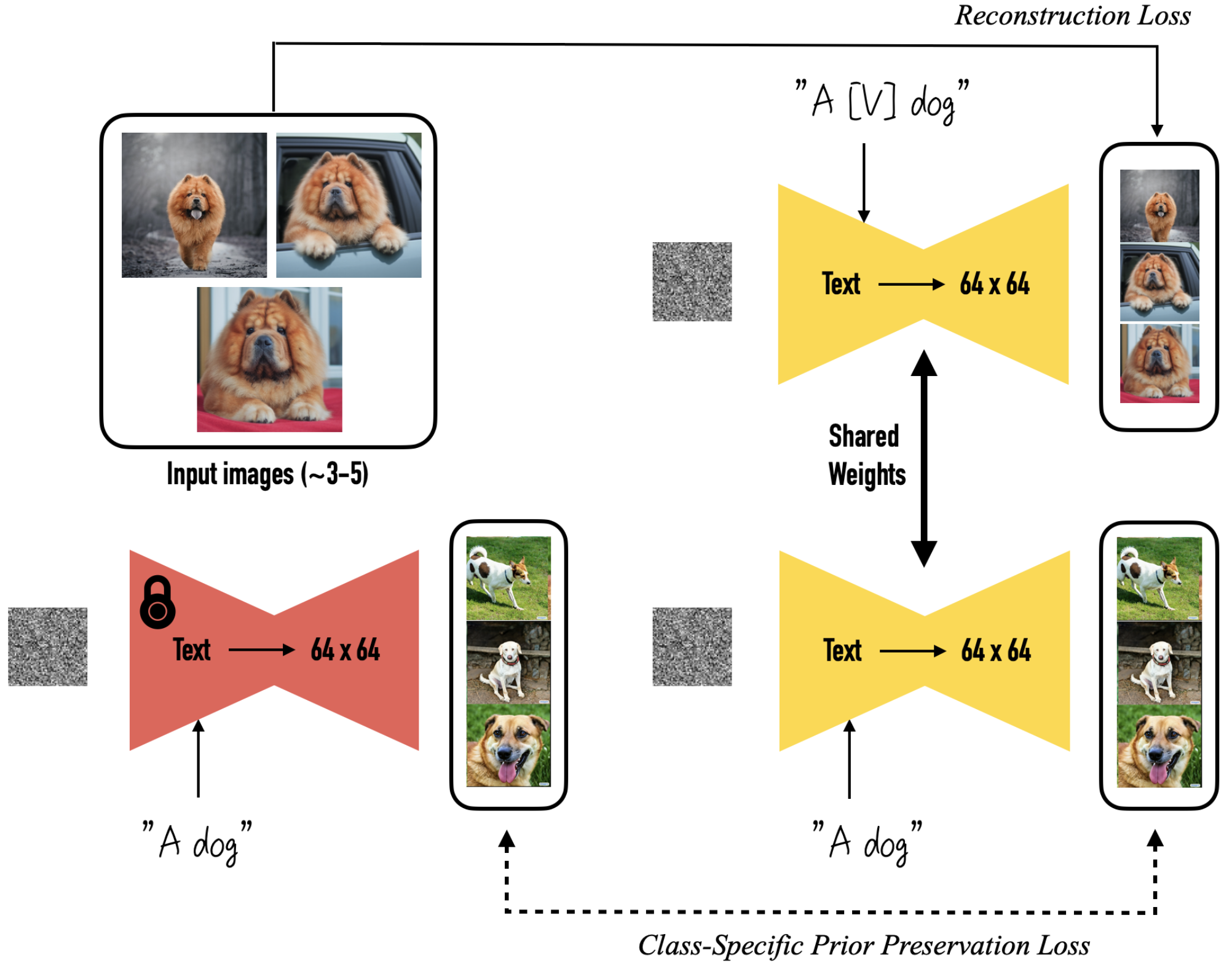
It does this by extending Stable Diffusion’s fine-tuning loss with a prior preservation loss to train the model to still generate diverse images for the category of that style (e.g. Löwentraut) or object (e.g. a dog). The prior preservation loss is the mean squared error of the now generated images and the pre-training generated images for the category in the latent space.
This fine-tuning involves two prompts:
- a
[CATEGORY]: The prompt for the prior preservation loss is the category of the style or object in question, likedogorpainting. - a
[RARE_IDENTIFIER] [CATEGORY]: The prompt for fine-tuning to a new object or style, generally a string that corresponds to a token the model is unfamiliar with. This is a unique reference to the object you want Stable Diffusion to learn. Example strings would besksorbtb.
So, to fine-tune Stable Diffusion to create images of your dog, you would:
- Take 5-8 high quality images of your dog.
- Fine-tune the model to recreate these images for the prompt
a sks dogand the same time still create diverse images for the prompta dog.
Creating diverse images is helped along the way by generating images for the prompt a dog and using them as training images.
Unstable Confusion: The amnesia creeps back in
So far, so good! But what if you first use DreamBooth to fine-tune Stable Diffusion on your dog, then train on Leon Löwentraut, then ask it to create a picture of your dog in his style? Or train for artist_1, then train for artist_2, then try to create a new image by artist_1?
That shouldn’t be too hard, right?
Too hard for DreamBooth unfortunately.
DreamBooth falls over on this because it has a selective short-term memory. Using it to teach Stable Diffusion something new (let’s say the style of Löwentraut) works great. And then you can create images of all kinds of places and objects (already known to Stable Diffusion) in his style. But then if you decide to train it in the style of another artist it’ll forget everything it learned about Löwentraut’s style.
That’s why we created BIG: To let you train on multiple objects and styles without the amnesia. But more on that in a later section.
To see DreamBooth’s amnesia in action, let’s use it to fine-tune a model for two different artists:
- Leon Löwentraut (using the
RARE_IDENTIFIERoflnl) - Vexx (using the
RARE_IDENTIFIERofqzq)


To generate a painting in one of the above styles, we’d use a prompt like a lnl painting or a qzq painting.
Using DreamBooth and the prompt a lnl painting to fine-tune a model to fit the art style of Leon Löwentraut works great. For this we used four training images and trained for 400 steps with a learning rate of 1e-6.
The left and center images show the model before fine-tuning. Note how it doesn’t know either lnl or loewentraut.



a qzq painting; Center: Generated image by Stable Diffusion with prompt a vexx painting; Right: Generated image for a qzq painting after fine-tuning for Vexx.But can the model still produce images in the styles of Picasso, Matisse and Banksy? Yes!



a banksy painting after fine-tuning for Vexx; Center: Generated image for prompt a mattisse painting after fine-tuning for Vexx; Left: Generated image for prompt a picasso painting after fine-tuning for Vexx.Now, after learning Vexx, does our model still remember Leon Löwentraut?

a lnl painting after fine-tuning for Vexx.Damn. Where did Leon go? It seems fine-tuning for Vexx overpowered Stable Diffusion’s memory of Leon. And it would do just the same if we trained it first on pictures of our favorite pooch and then secondly on our favorite artist. The result? Bye bye doggie.
How can we cure DreamBooth’s amnesia?
To solve the problem of forgetting Leon Löwentraut while learning Vexx, we included the images of Leon Löwentraut in the prior preservation loss during the fine-tuning. This is equivalent to further fine-tuning on Löwentraut while fine-tuning on Vexx, but less so than the original fine-tuning of Löwentraut. It works best to reuse the actual images for the style than the images the model generated.
So, now we can generate all the artists we encounter in our travels. After teaching Stable Diffusion model to create images in the style of Leon Löwentraut from the prompt a lnl painting, we wanted to create images of our favourite mate tea bottle. So, again we used the Leon Löwentraut fine-tuned model as initialization to train my Stable Diffusion model to create images of Mio Mio Mate for a sks bottle (giving it a unique RARE_IDENTIFIER).



a mio mio mate bottle; Right: Generated image by Stable Diffusion with prompt: a sks bottleAgain, this works for the new object, yet the model doesn’t quite remember how to produce images for Leon Löwentraut under a lnl painting.


a sks bottle after fine-tuning for Mio Mio bottle; Right: Generated image for a lnl painting after fine-tuning for Mio Mio bottle.To solve this issue, we can also think about using the previous images for Leon Löwentraut in the prior preservation loss. This helps remember the style of Leon Löwentraut. Yet, art styles which have similar geometric features (like Picasso) are not as accurately reproduced. This makes intuitive sense and is also the reason DreamBooth was introduced in the first place. Building on it, we need to not only incorporate the images of Leon Löwentraut in the prior preservation loss but also images of paintings, i.e., incorporate additionally the previous objects/styles and their categories into the prior preservation loss.
BIG Metamodel: Fine-tune Stable Diffusion to your favorite artist and dog
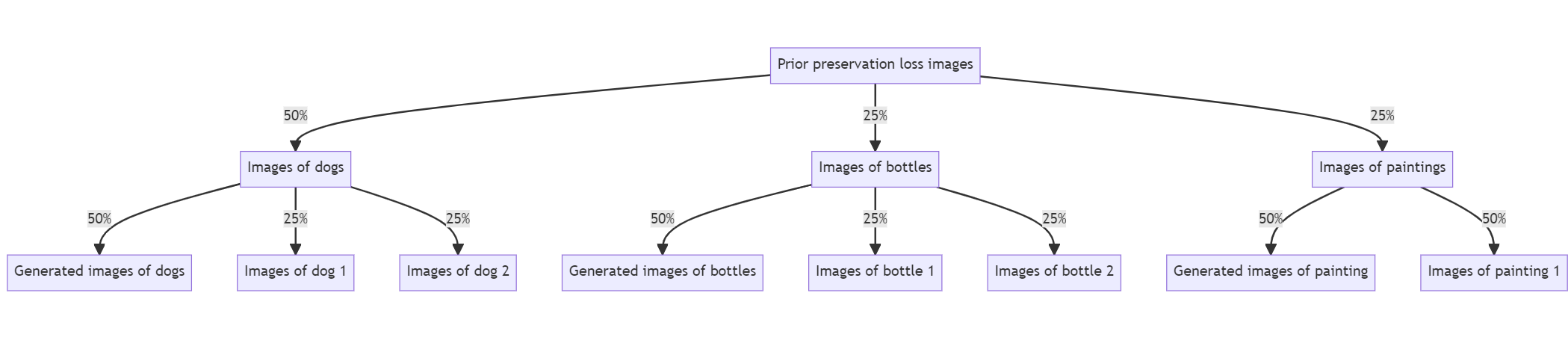
Now piecing together the above ideas raises the question: how do we split the images for the prior preservation loss as a batch that always consists of N instance images and N prior preservation loss images? Well, the following intuitive split works great:
- Use half of the prior preservation loss image for the current category and its previously learned instances
- 50% of those are generated images for the category
- Remaining 50% equally divided among previously used instance images
- Use the other half equally among the previously trained categories; so for every category, split available images into:
- 50% generated images for category (prompt is e.g.
a painting) - Remaining 50% equally divided among previously used instance images
- 50% generated images for category (prompt is e.g.
To illustrate this, let’s assume we have a metamodel which has learnt:
- Two objects for category
bottle - Two for
dog - One for
painting
To learn another dog the top-level split between the categories and the for the individual categories are as follows:
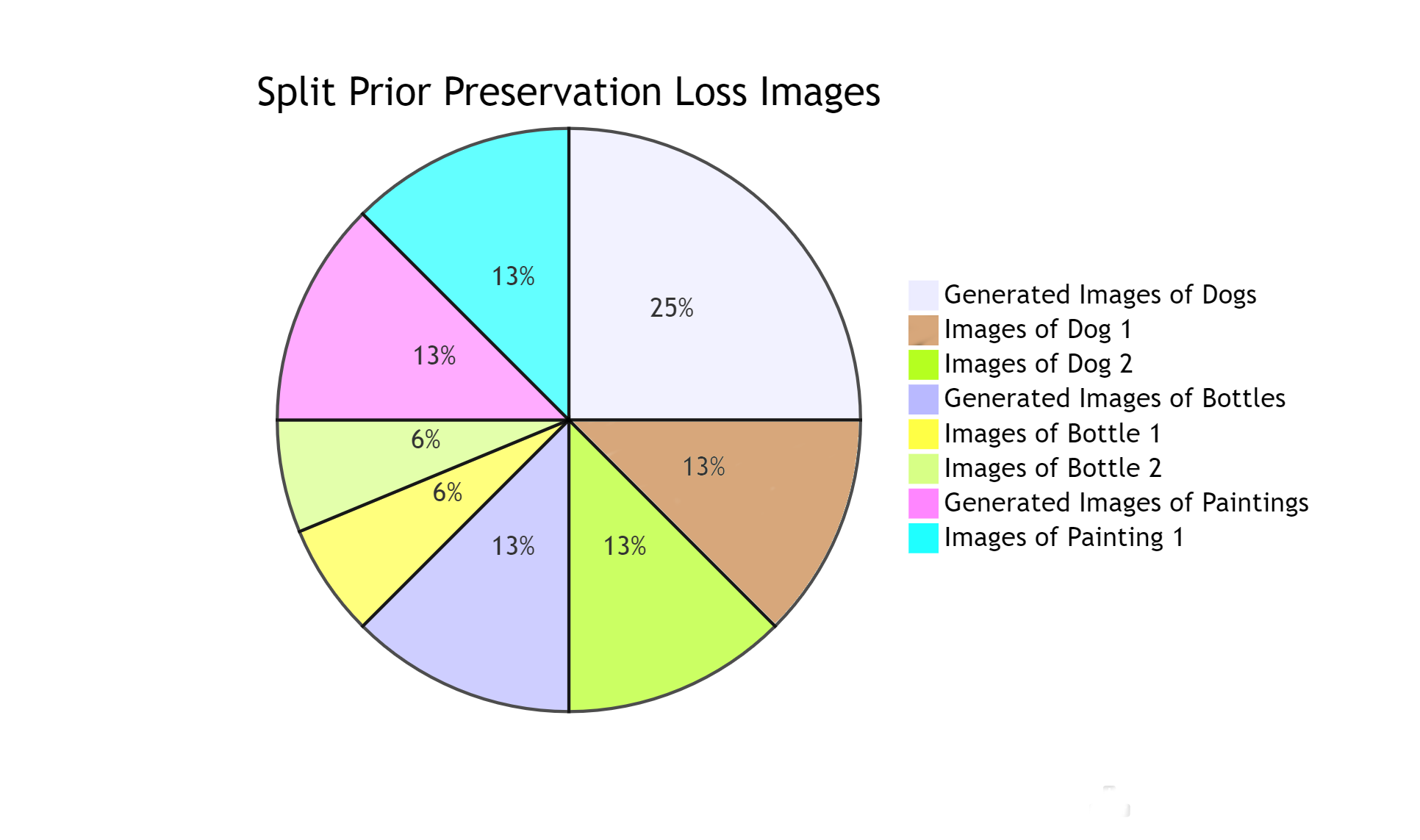
Visualizing it as a pie chart, this is the split of all images for the prior preservation loss:
To abstract that logic away, we created an Executor to quickly fine-tune private (i.e. owned by a specific user) models for specific objects/styles, as well as create public and private metamodels. To do that it exposes the following endpoints:
/finetuneendpoint:- Fine-tunes a model for a particular style or object which is private (
private model) - Incrementally fine-tunes a model for various styles and objects which is only accessible by particular user (
private metamodel) - Incrementally fine-tunes a model for various styles and objects which is accessible for everyone and to which everyone can contribute (
metamodel)
- Fine-tunes a model for a particular style or object which is private (
/generateendpoint:- Generates images for any of above models as well as for a
pretrainedmodel
- Generates images for any of above models as well as for a
The Hitchhiker's Guide to Building Your Own Metamodel
So how do you train your metamodel?
First, fit a private model to find the right learning rate and training steps. A low learning rate of 1e-6 is best across different styles and objects. We found that starting from 200 training steps and slowly increasing to 600 is best to find the sweet spot of fitting and not overfitting for objects and styles. To recreate faces, we recommend starting from 600 training steps and increasing to 1,200.
The second and final step is to reuse the same parameters for the request but change the target_model to meta or private_meta.
Now you have your (private) metamodel. In a script, fine-tuning is made very simple as shown below:
from jina import Client, DocumentArray
import hubble
# specify the path to the images
path_to_instance_images = '/path/to/instance/images'
# specify the category of the images, this could be e.g. 'painting', 'dog', 'bottle', etc.
category = 'category of the objects'
# 'private' for training private model from pretrained model, 'meta' for training metamodel
target_model = 'private'
# some custom parameters for the training
max_train_steps = 300
learning_rate = 1e-6
docs = DocumentArray.from_files(f'{path_to_instance_images}/**')
for doc in docs:
doc.load_uri_to_blob()
doc.uri = None
client = Client(host='grpc://host_big_executor:port_big_executor')
identifier_doc = client.post(
on='/finetune',
inputs=docs,
parameters={
'jwt': {
'token': hubble.get_token(),
},
'category': category,
'target_model': target_model,
'learning_rate': learning_rate,
'max_train_steps': max_train_steps,
},
)
print(f'Finetuning was successful. The identifier for the object is "{identifier_doc[0].text}"')Results
With our new metamodel we taught Stable Diffusion to create images of the Mio Mio Mate tea bottle, a sparking water bottle from a local manufacturer, a NuPhy Air75 keyboard, and an office desk chair and artwork in the styles of Leon Löwentraut and Vexx:






Note how for both bottles a hand appears holding it. For both generated images there were six images used for fine-tuning and for both there was only one image holding the bottle by hand. Yet, the model has somewhat collapsed to always showing this hand. This shows the importance of not only high-quality but also diverse representative images. Here are the images of a hand holding the bottle that we used for fine-tuning:


The model isn’t just able to memorize the objects, but also learns how newly-learned objects and styles interact:


a qzq painting of a rvt bottle; Right: Mate bottle in Leon Löwentraut's style, generated with prompt: a lnl painting of a pyr bottle

a qzq painting of a sph keyboard; Right: NuPhy Air75 keyboard in style of Leon Löwentraut, generated with prompt: a lnl painting of a sph keyboardLast, but not least we trained it to create images of Joschka's company dog, Briscoe:



a brc dog; Right: A painting of Briscoe in the style of Leon Löwentraut generated with prompt: a lnl painting of a brc dog.What’s next?
In future, it would be interesting to enhance the performance if we additionally apply Textual Inversion to get better prompts for generating new images. This might also change how previously-learned objects are forgotten.
We could also explore other angles, like why previously learned objects and styles get overwritten, by understanding if the similarity in prompts is an issue or if semantic similarity of the new objects is a strong predictor of forgetting. The former can be solved by better sampling of the rare identifiers, using BLIP to automatically generate captions, or adapting textual inversion to incorporate the forgetting effect.
Another question is when the current form of further learning in the metamodel leads to overfitting to previously-learned objects and styles as the model is continuously trained to minimize the loss of the generated images for them. For that it’s relevant to optimize the allocation of images for the prior preservation loss in order to push the amount of new learnt objects even further.
You can also start playing around with it yourself in Google Colab or check out the GitHub repository.