Implementing a Chat History RAG with Jina AI and Milvus Lite
Enhance your search applications in Python with Jina Embeddings and Reranker and lightweight, easy-to-deploy Milvus Lite.



Developers and operations engineers put a high value on infrastructure that they can easily set up, quickly start, and, later, efficiently deploy in a scaled production environment without additional hassle. For this reason, Milvus Lite, the latest lightweight vector database offering from our partner Milvus, is an important tool for Python developers to quickly develop search applications, especially when used together with high-quality and easy-to-use search foundation models.
In this article, we’ll describe how Milvus Lite integrates Jina Embeddings v2 and Jina Reranker v1 using the example of a Retrieval Augmented Generation (RAG) application built on a fictitious company’s internal public channel chats to let employees get answers to their organization-related questions in an accurate and helpful manner.
Overview of Milvus Lite, Jina Embeddings and Jina Reranker
Milvus Lite is a new, lightweight version of leading vector database Milvus, which is now also offered as a Python library. Milvus Lite shares the same API as Milvus deployed on Docker or Kubernetes but can be easily installed via a one-line pip command, without setting up a server.
With the integration of Jina Embeddings v2 and Jina Reranker v1 in pymilvus, Milvus's Python SDK, you now have the option to directly embed documents using the same Python client for any deployment mode of Milvus, including Milvus Lite. You can find details of the Jina Embeddings and Reranker integration on pymilvus’ documentation pages.
With its 8k-token context window and multilingual capabilities, Jina Embeddings v2 encodes the broad semantics of text and ensures accurate retrieval. By adding Jina Reranker v1 to the pipeline, you can further refine your results by cross-encoding the retrieved results directly with the query for a deeper contextual understanding.
Milvus and Jina AI Models in Action
This tutorial will focus on a practical use case: Querying a company's Slack chat history to answer a wide range of questions based on past conversations.
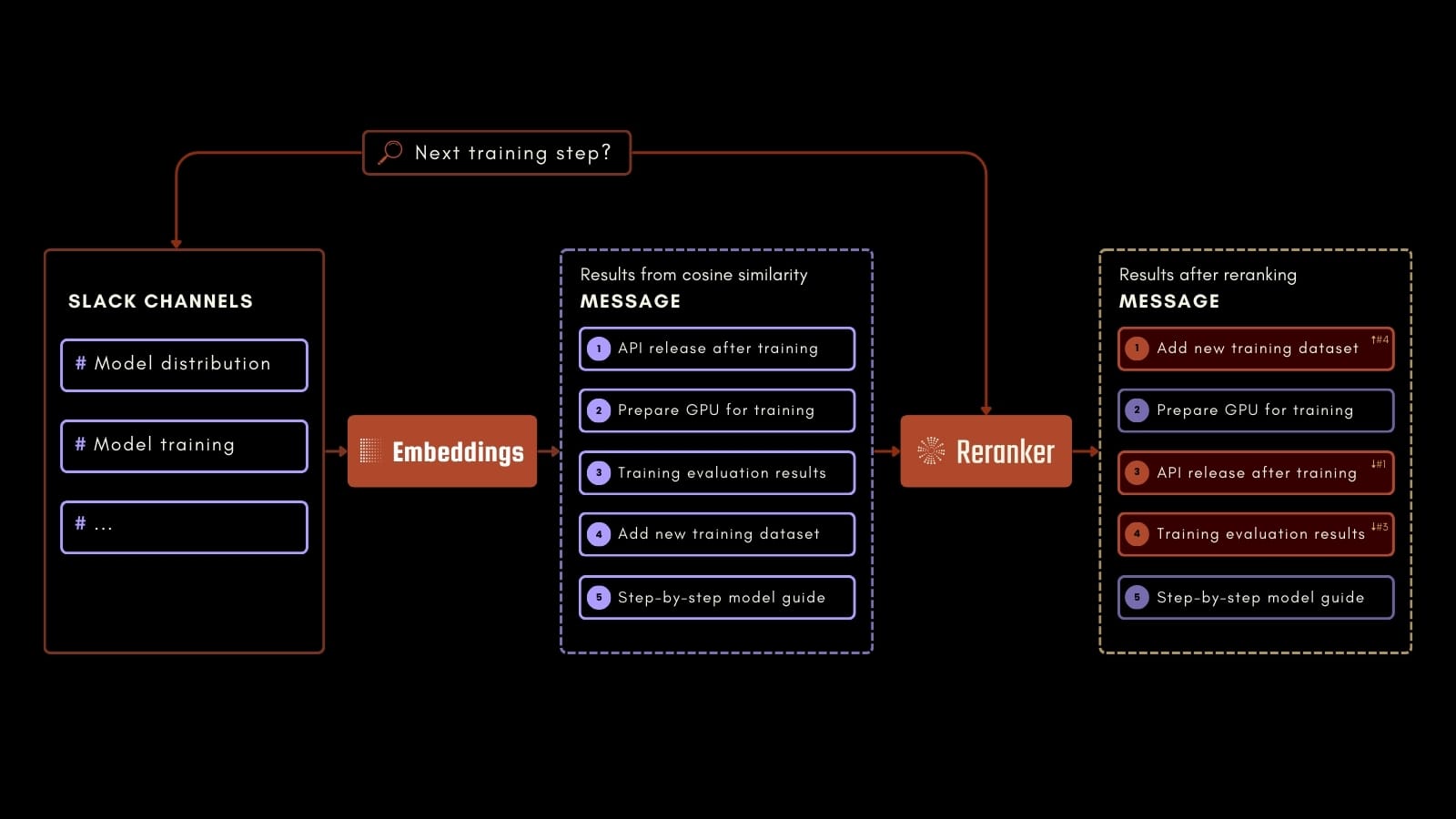
For example, an employee could ask about the next step in some AI training process, as in the process schema above. By using Jina Embeddings, Jina Reranker, and Milvus, we can accurately identify relevant information in the logged Slack messages. This application can level up your workplace productivity by making it easier to access valuable information from past communications.
To generate the answers, we will use Mixtral 7B Instruct through HuggingFace’s integration in Langchain. To use the model, you need a HuggingFace access token that you can generate as described here.
You can follow along in Colab or by downloading the notebook.


About the Dataset
The dataset used in this tutorial was generated using GPT-4 and is meant to replicate the chat histories of Blueprint AI’s Slack channels. Blueprint is a fictitious AI startup developing its own foundational models. You can download the dataset here.
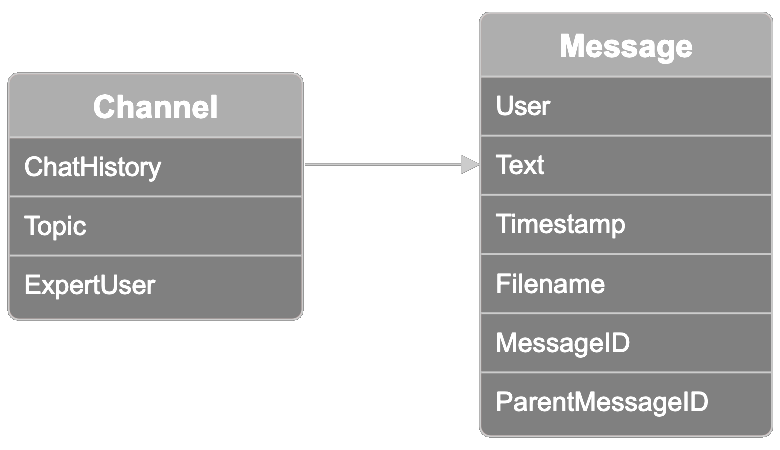
The data is organized in channels, each representative of a collection of related Slack threads. Each channel has a topic label, one of ten topic options: model distribution, model training, model fine-tuning, ethics and bias mitigation, user feedback, sales, marketing, model onboarding, creative design, and product management. One participant is known as the "expert user". You can use this field to validate the results of querying for the most expert user in a topic, which we will show you how to do below.
Each channel also contains a chat history with conversation threads of up to 100 messages per channel. Each message in the dataset contains the following information:
- The user that sent the message
- The message text sent by the user
- The timestamp of the message
- The name of the file the user might have attached to the message
- The message ID
- The parent message ID if the message was within a thread originated from another message
Set up the Environment
To start, install all the necessary components:
pip install -U pymilvus
pip install -U "pymilvus[model]"
pip install langchain
pip install langchain-community
Download the dataset:
import os
if not os.path.exists("chat_history.json"):
!wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/embeddings/milvus/chat_history.jsonSet your Jina AI API Key in an environment variable. You can generate one here.
import os
import getpass
os.environ["JINAAI_API_KEY"] = getpass.getpass(prompt="Jina AI API Key: ")Do the same for your Hugging Face Token. You can find how to generate one here. Make sure that it is set to READ to access the Hugging Face Hub.
os.environ["HUGGINGFACEHUB_API_TOKEN"] = getpass.getpass(prompt="Hugging Face Token: ")Create the Milvus Collection
Create the Milvus Collection to index the data:
from pymilvus import MilvusClient, DataType
# Specify a local file name as uri parameter of MilvusClient to use Milvus Lite
client = MilvusClient("milvus_jina.db")
schema = MilvusClient.create_schema(
auto_id=True,
enable_dynamic_field=True,
)
schema.add_field(field_name="id", datatype=DataType.INT64, description="The Primary Key", is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, description="The Embedding Vector", dim=768)
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")
client.create_collection(collection_name="milvus_jina", schema=schema, index_params=index_params)Prepare the Data
Parse the chat history and extract the metadata:
import json
with open("chat_history.json", "r", encoding="utf-8") as file:
chat_data = json.load(file)
messages = []
metadatas = []
for channel in chat_data:
chat_history = channel["chat_history"]
chat_topic = channel["topic"]
chat_expert = channel["expert_user"]
for message in chat_history:
text = f"""{message["user"]}: {message["message"]}"""
messages.append(text)
meta = {
"time_stamp": message["time_stamp"],
"file_name": message["file_name"],
"parent_message_nr": message["parent_message_nr"],
"channel": chat_topic,
"expert": True if message["user"] == chat_expert else False
}
metadatas.append(meta)
Embed the Chat Data
Create embeddings for each message using Jina Embeddings v2 to retrieve relevant chat information:
from pymilvus.model.dense import JinaEmbeddingFunction
jina_ef = JinaEmbeddingFunction("jina-embeddings-v2-base-en")
embeddings = jina_ef.encode_documents(messages)Index the Chat Data
Index the messages, their embeddings, and the related metadata:
collection_data = [{
"message": message,
"embedding": embedding,
"metadata": metadata
} for message, embedding, metadata in zip(messages, embeddings, metadatas)]
data = client.insert(
collection_name="milvus_jina",
data=collection_data
)Query the Chat History
Time to ask a question:
query = "Who knows the most about encryption protocols in my team?"Now embed the query and retrieve relevant messages. Here we retrieve the five most relevant messages and rerank them using Jina Reranker v1:
from pymilvus.model.reranker import JinaRerankFunction
query_vectors = jina_ef.encode_queries([query])
results = client.search(
collection_name="milvus_jina",
data=query_vectors,
limit=5,
)
results = results[0]
ids = [results[i]["id"] for i in range(len(results))]
results = client.get(
collection_name="milvus_jina",
ids=ids,
output_fields=["id", "message", "metadata"]
)
jina_rf = JinaRerankFunction("jina-reranker-v1-base-en")
documents = [results[i]["message"] for i in range(len(results))]
reranked_documents = jina_rf(query, documents)
reranked_messages = []
for reranked_document in reranked_documents:
idx = reranked_document.index
reranked_messages.append(results[idx])Lastly, generate an answer to the query using Mixtral 7B Instruct and the reranked messages as context:
from langchain.prompts import PromptTemplate
from langchain_community.llms import HuggingFaceEndpoint
llm = HuggingFaceEndpoint(repo_id="mistralai/Mixtral-8x7B-Instruct-v0.1")
prompt = """<s>[INST] Context information is below.\\n
It includes the five most relevant messages to the query, sorted based on their relevance to the query.\\n
---------------------\\n
{context_str}\\\\n
---------------------\\n
Given the context information and not prior knowledge,
answer the query. Please be brief, concise, and complete.\\n
If the context information does not contain an answer to the query,
respond with \\"No information\\".\\n
Query: {query_str}[/INST] </s>"""
prompt = PromptTemplate(template=prompt, input_variables=["query_str", "context_str"])
llm_chain = prompt | llm
answer = llm_chain.invoke({"query_str":query, "context_str":reranked_messages})
print(f"\n\nANSWER:\n\n{answer}")The answer to our question is:
“Based on the context information, User5 seems to be the most knowledgeable about encryption protocols in your team. They have mentioned that the new protocols enhance data security significantly, especially for cloud deployments.”
If you read through the messages in chat_history.json, you can verify for yourself if User5 is the most expert user.
Summary
We have seen how to set up Milvus Lite, embed chat data using Jina Embeddings v2, and refine search results with Jina Reranker v1, all within a practical use case of searching a Slack chat history. Milvus Lite simplifies Python-based application development without the need for complex server setups. Its integration with Jina Embeddings and Reranker aims to boost productivity by making it easier to access valuable information from your workplace.
Use Jina AI Models and Milvus Now
Milvus Lite with integrated Jina Embeddings and Reranker provides you with a complete processing pipeline, ready to use with just a few lines of code.
We would love to hear about your use cases and talk about how the Jina AI Milvus extension can fit your business needs. Contact us via our website or our Discord channel to share your feedback and stay up-to-date with our latest models. For questions about Milvus and Jina AI's integration, join the Milvus community.