Jina AI Launches World's First Open-Source 8K Text Embedding, Rivaling OpenAI
Jina AI introduces jina-embeddings-v2, the world's first open-source model boasting an 8K context length. Matching the prowess of OpenAI's proprietary models, this innovation is now publicly accessible on Huggingface, signaling a significant milestone in the landscape of text embeddings.


jina-embeddings-v3 has been released on Sept. 18, 2024. The best <1B multilingual embedding model.
Berlin, Germany - October 25, 2023 – Jina AI, the Berlin-based artificial intelligence company, is thrilled to announce the launch of its second-generation text embedding model: jina-embeddings-v2. This cutting-edge model is now the only open-source offering that supports an impressive 8K (8192 tokens) context length, putting it on par with OpenAI's proprietary model, text-embedding-ada-002, in terms of both capabilities and performance on the Massive Text Embedding Benchmark (MTEB) leaderboard.

Benchmarking Against the Best 8K Model from Open AI
When directly compared with OpenAI's 8K model text-embedding-ada-002, jina-embeddings-v2 showcases its mettle. Below is a performance comparison table, highlighting areas where jina-embeddings-v2 particularly excels:
| Rank | Model | Model Size (GB) | Embedding Dimensions | Sequence Length | Average (56 datasets) | Classification Average (12 datasets) | Reranking Average (4 datasets) | Retrieval Average (15 datasets) | Summarization Average (1 dataset) |
|---|---|---|---|---|---|---|---|---|---|
| 15 | text-embedding-ada-002 | Unknown | 1536 | 8191 | 60.99 | 70.93 | 84.89 | 56.32 | 30.8 |
| 17 | jina-embeddings-v2-base-en | 0.27 | 768 | 8192 | 60.38 | 73.45 | 85.38 | 56.98 | 31.6 |
Notably, jina-embedding-v2 outperforms its OpenAI counterpart in Classification Average, Reranking Average, Retrieval Average, and Summarization Average.
Features and Benefits
Jina AI’s dedication to innovation is evident in this latest offering:
- From Scratch to Superiority: The
jina-embeddings-v2was built from the ground up. Over the last three months, the team at Jina AI engaged in intensive R&D, data collection, and tuning. The outcome is a model that marks a significant leap from its predecessor. - Unlocking Extended Context Potential with 8K:
jina-embeddings-v2isn’t just a technical feat; its 8K context length opens doors to new industry applications:- Legal Document Analysis: Ensure every detail in extensive legal texts is captured and analyzed.
- Medical Research: Embed scientific papers holistically for advanced analytics and discovery.
- Literary Analysis: Dive deep into long-form content, capturing nuanced thematic elements.
- Financial Forecasting: Attain superior insights from detailed financial reports.
- Conversational AI: Improve chatbot responses to intricate user queries.
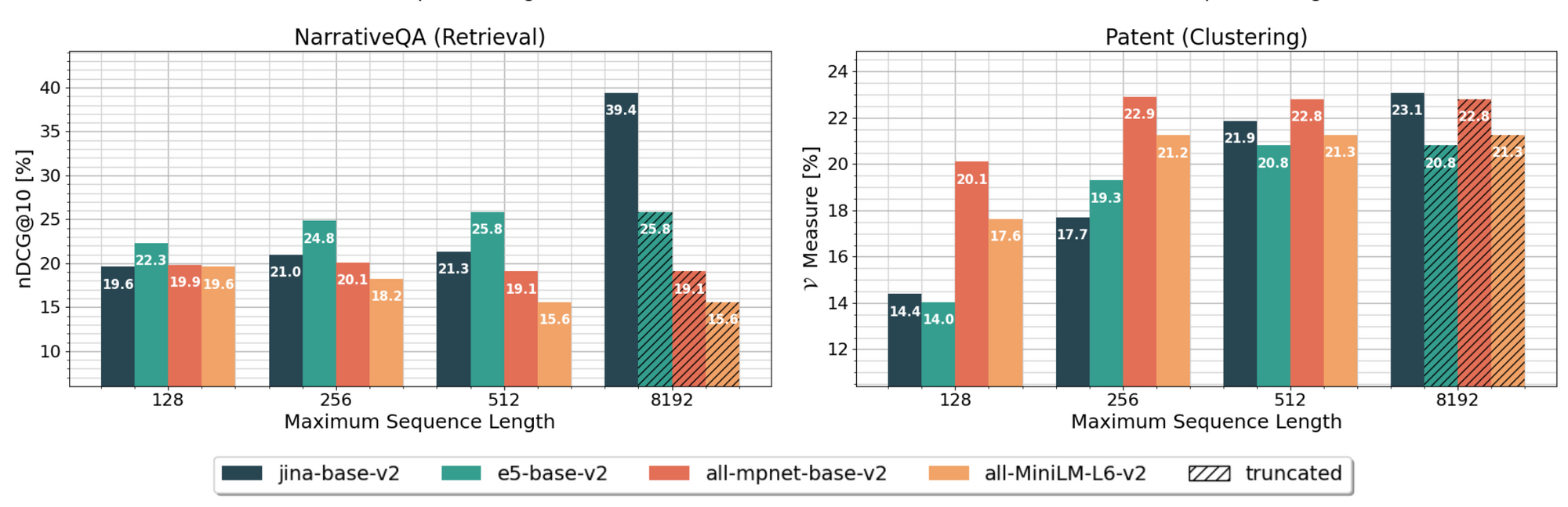
Benchmarking shows that in several datasets, this extended context enabled jina-embeddings-v2 to outperform other leading base embedding models, emphasizing the practical advantages of longer context capabilities.
- Availability: Both models are freely available for download on Huggingface:
- Base Model (0.27G) - Designed for heavy-duty tasks requiring higher accuracy, like academic research or business analytics.
- Small Model (0.07G) - Crafted for lightweight applications such as mobile apps or devices with limited computing resources.
- Size Options for Different Needs: Understanding the diverse needs of the AI community, Jina AI offers two versions of the model:


In reflecting on the journey and significance of this launch, Dr. Han Xiao, CEO of Jina AI, shared his thoughts:
"In the ever-evolving world of AI, staying ahead and ensuring open access to breakthroughs is paramount. With jina-embeddings-v2, we've achieved a significant milestone. Not only have we developed the world's first open-source 8K context length model, but we have also brought it to a performance level on par with industry giants like OpenAI. Our mission at Jina AI is clear: we aim to democratize AI and empower the community with tools that were once confined to proprietary ecosystems. Today, I am proud to say, we have taken a giant leap towards that vision."This pioneering spirit is evident in Jina AI's forward-looking plans.
A Glimpse into the Future
Jina AI is committed to leading the forefront of innovation in AI. Here’s what’s next on their roadmap:
- Academic Insights: An academic paper detailing the technical intricacies and benchmarks of
jina-embeddings-v2will soon be published, allowing the AI community to gain deeper insights. - API Development: The team is in the advanced stages of developing an OpenAI-like embeddings API platform. This will provide users with the capability to effortlessly scale the embedding model according to their needs.
- Language Expansion: Venturing into multilingual embeddings, Jina AI is setting its sights on launching German-English models, further expanding its repertoire.
About Jina AI GmbH:
Located at Ohlauer Str. 43 (1st floor), zone A, 10999 Berlin, Germany, Jina AI is at the vanguard of reshaping the landscape of multimodal artificial intelligence. For inquiries, please reach out at contact@jina.ai.