Jina Embeddings v3: A Frontier Multilingual Embedding Model
jina-embeddings-v3 is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.



Today, we are excited to announce jina-embeddings-v3, a frontier text embedding model with 570 million parameters. It achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting input length of up to 8192 tokens. The model features task-specific Low-Rank Adaptation (LoRA) adapters, enabling it to generate high-quality embeddings for various tasks including query-document retrieval, clustering, classification, and text matching.
In evaluations on the MTEB English, Multilingual and LongEmbed, jina-embeddings-v3 outperforms the latest proprietary embeddings from OpenAI and Cohere on English tasks, while also surpassing multilingual-e5-large-instruct across all multilingual tasks. With a default output dimension of 1024, users can arbitrarily truncate embedding dimensions down to 32 without sacrificing performance, thanks to the Matryoshka Representation Learning (MRL) integration.

jina-embeddings-v3 vs other embedding models across all MTEB English tasks. Full evaluation results per task can be found in our arXiv paper.
jina-embeddings-v3 has been evaluated across a broad selection of multilingual and cross-lingual MTEB tasks. Please note that jina-embeddings-v2-(zh/es/de) refers to our bilingual model suite, which was only tested on Chinese, Spanish, and German monolingual and cross-lingual tasks, excluding all other languages. Additionally, we do not report scores for openai-text-embedding-3-large and cohere-embed-multilingual-v3.0, as these models were not evaluated on the full range of multilingual and cross-lingual MTEB tasks.
jina-embeddings-v3 on six long-document retrieval tasks from the LongEmbed benchmark shows a significant improvement over other models. Scores are nDCG@10; higher is better. This suggests the effectiveness of our RoPE-based positional embeddings, which outperform both the fixed positional embeddings used by baai-bge-m3 and the ALiBi-based approach used in jina-embeddings-v2.As of its release on September 18, 2024, jina-embeddings-v3 is the best multilingual model and ranks 2nd on the MTEB English leaderboard for models with fewer than 1 billion parameters. v3 supports 89 languages in total, including 30 languages with the best performance: Arabic, Bengali, Chinese, Danish, Dutch, English, Finnish, French, Georgian, German, Greek, Hindi, Indonesian, Italian, Japanese, Korean, Latvian, Norwegian, Polish, Portuguese, Romanian, Russian, Slovak, Spanish, Swedish, Thai, Turkish, Ukrainian, Urdu, and Vietnamese.
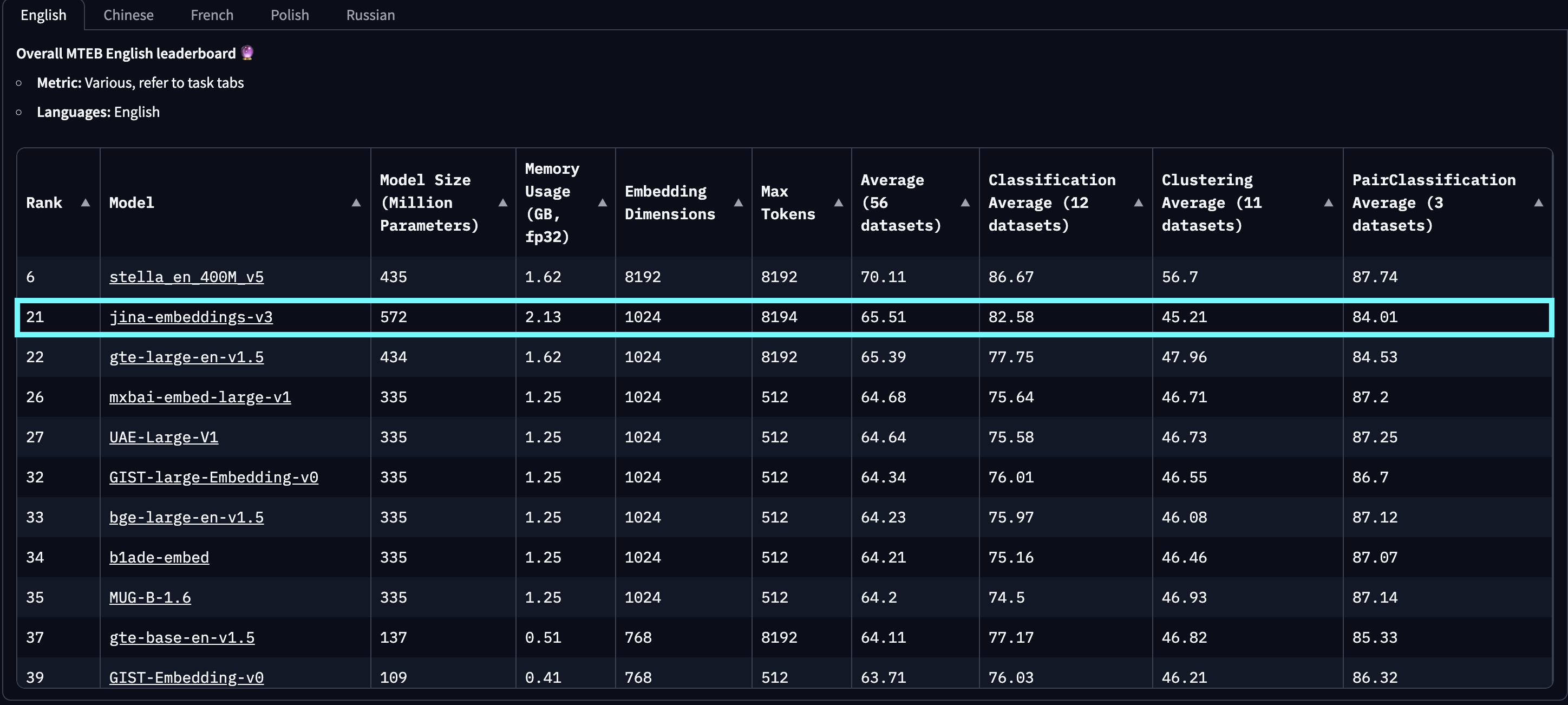
jina-embeddings-v3, featuring 570 million parameters and 1024 output dimensions, stands as the most efficient, powerful, and reliable multilingual embedding model with fewer than 1 billion parameters.
jina-embeddings-v3 demonstrates superior performance compared to models of similar size, also showing a superlinear improvement over its predecessor, jina-embeddings-v2. This graph was created by selecting top-100 embedding models from the MTEB leaderboard , excluding those without size information, typically closed-source or proprietary models. Submissions identified as obvious trolling were also filtered out. Additionally, compared to LLM-based embeddings that have recently gained attention, such as e5-mistral-7b-instruct, which has a parameter size of 7.1 billion (12x larger) and an output dimension of 4096 (4x larger) but offers only a 1% improvement on MTEB English tasks, jina-embeddings-v3 is a far more cost-efficient solution, making it more suitable for production and on-edge computing.
Model Architecture
| Feature | Description |
|---|---|
| Base | jina-XLM-RoBERTa |
| Parameters Base | 559M |
| Parameters w/ LoRA | 572M |
| Max input tokens | 8192 |
| Max output dimensions | 1024 |
| Layers | 24 |
| Vocabulary | 250K |
| Supported languages | 89 |
| Attention | FlashAttention2, also works w/o |
| Pooling | Mean pooling |
The architecture of jina-embeddings-v3 is shown in the figure below. To implement the backbone architecture, we adapted the XLM-RoBERTa model with several key modifications: (1) enabling effective encoding of long text sequences, (2) allowing task-specific encoding of embeddings, and (3) improving overall model efficiency with latest techniques. We continue to use the original XLM-RoBERTa tokenizer. While jina-embeddings-v3, with its 570 million parameters, is larger than jina-embeddings-v2 at 137 million, it is still much smaller than embedding models fine-tuned from LLMs.

jina-embeddings-v3 is based on the jina-XLM-RoBERTa model, with five LoRA adapters for four different tasks.The key innovation in jina-embeddings-v3 is the use of LoRA adapters. Five task-specific LoRA adapters are introduced to optimize embeddings for four tasks. The model’s input consists of two parts: the text (the long document to be embedded) and the task. jina-embeddings-v3 supports four tasks and implements five adapters to choose from: retrieval.query and retrieval.passage for query and passage embeddings in asymmetric retrieval tasks, separation for clustering tasks, classification for classification tasks, and text-matching for tasks involving semantic similarity, such as STS or symmetric retrieval. The LoRA adapters account for less than 3% of the total parameters, adding very minimal overhead to the computation.
To further enhance performance and reduce memory consumption, we integrate FlashAttention 2, support activation checkpointing, and use the DeepSpeed framework for efficient distributed training.
Get Started
Via Jina AI Search Foundation API
The easiest way to use jina-embeddings-v3 is to visit Jina AI homepage and navigate to the Search Foundation API section. Starting today, this model is set as the default for all new users. You can explore different parameters and features directly from there.
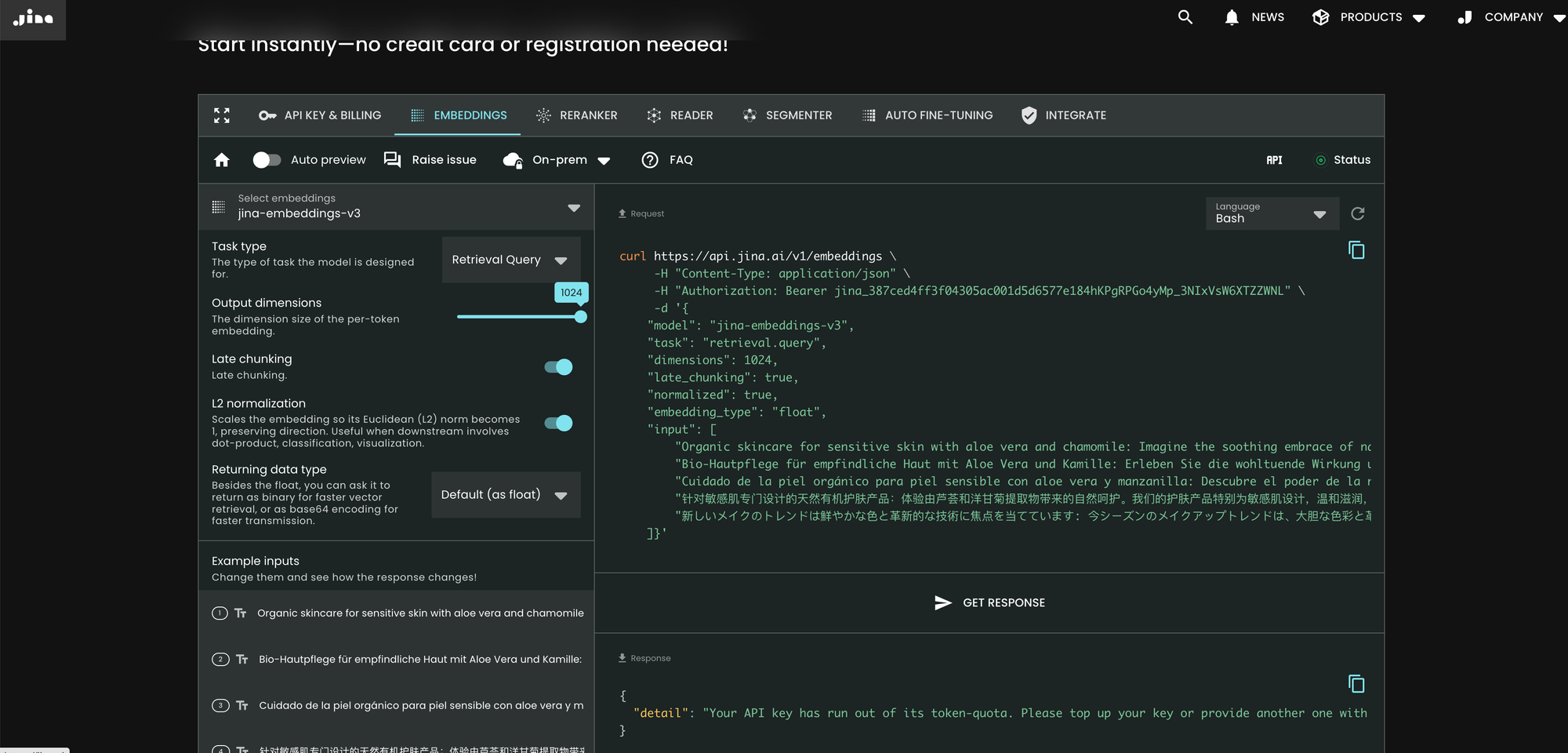
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jina_387ced4ff3f04305ac001d5d6577e184hKPgRPGo4yMp_3NIxVsW6XTZZWNL" \
-d '{
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 1024,
"late_chunking": true,
"input": [
"Organic skincare for sensitive skin with aloe vera and chamomile: ...",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung...",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder ...",
"针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,...",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。..."
]}'
Compared to v2, v3 introduces three new parameters in the API: task, dimensions, and late_chunking.
Parameter task
The task parameter is crucial and must be set according to the downstream task. The resulting embeddings will be optimized for that specific task. For more details, refer to the list below.
task value |
Task Description |
|---|---|
retrieval.passage |
Embedding documents in a query-document retrieval task |
retrieval.query |
Embedding queries in a query-document retrieval task |
separation |
Clustering documents, visualizing a corpus |
classification |
Text classification |
text-matching |
(Default) Semantic text similarity, general symmetric retrieval, recommendation, finding similar items, deduplication |
Note that the API does not first generate a generic meta embedding and then adapt it with an additional fine-tuned MLP. Instead, it inserts the task-specific LoRA adapter into every transformer layer (a total of 24 layers) and performs the encoding in one shot. Further details can be found in our arXiv paper.
Parameter dimensions
The dimensions parameter allows users to choose a trade-off between space efficiency and performance at the lowest cost. Thanks to the MRL technique used in jina-embeddings-v3, you can reduce the dimensions of embeddings as much as you want (even down to a single dimension!). Smaller embeddings are more storage-friendly for vector databases, and their performance cost can be estimated from the figure below.

Parameter late_chunking
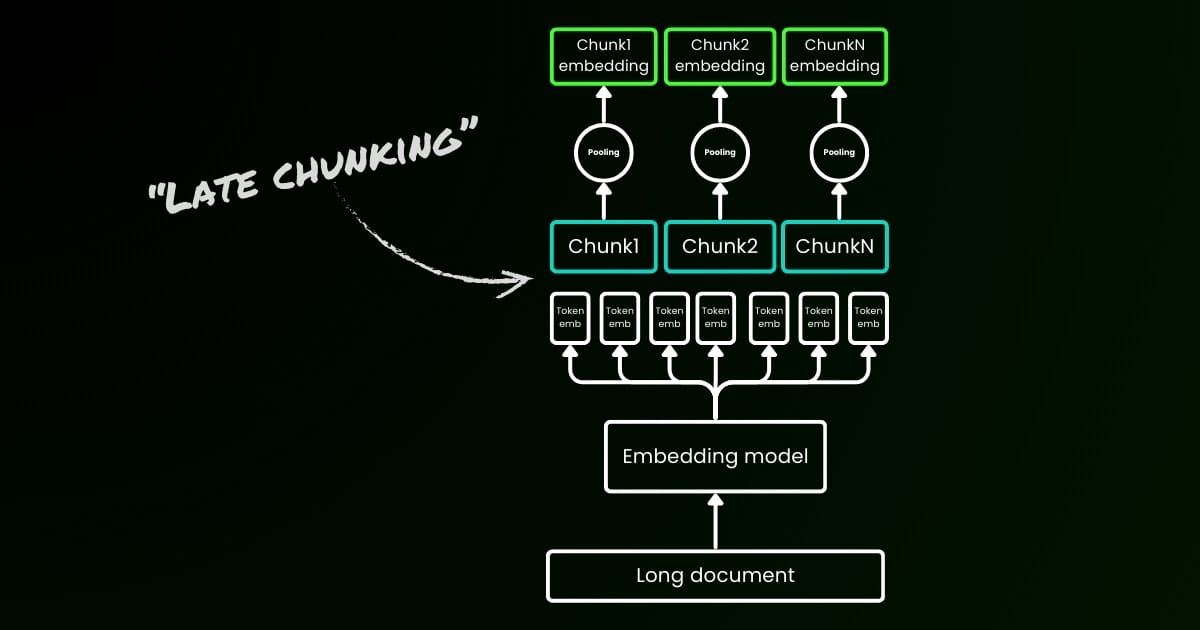
Finally, the late_chunking parameter controls whether to use the new chunking method we introduced last month for encoding a batch of sentences. When set to true, our API will concatenate all sentences in the input field and feed them as a single string to the model. In other words, we treat the sentences in the input as if they originally come from the same section, paragraph, or document. Internally, the model embeds this long concatenated string and then performs late chunking, returning a list of embeddings that matches the size of the input list. Each embedding in the list is therefore conditioned on the previous embeddings.
From a user perspective, setting late_chunking does not change the input or output format. You will only notice a change in the embedding values, as they are now computed based on the entire previous context rather than independently. What's important to know when using late_chunking=True is that the total number of tokens (by summing up all tokens in input) per request is restricted to 8192, which is the maximum context length allowed for jina-embeddings-v3. When late_chunking=False, there is no such restriction; the total number of tokens is only subject to the rate limit of the Embedding API.
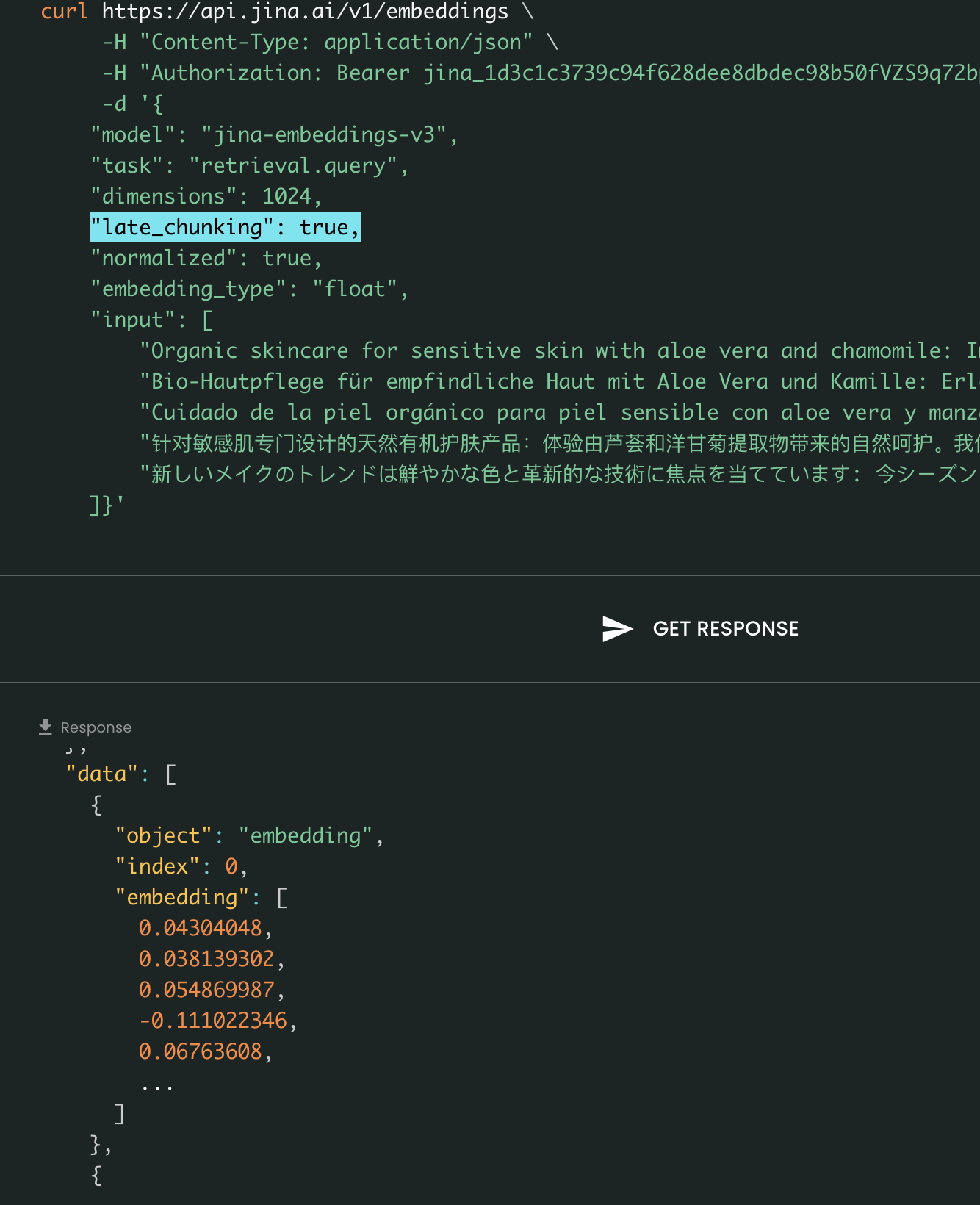
Late Chunking On vs Off: The input and output format remains the same, with the only difference being the embedding values. When late_chunking is enabled, embeddings are influenced by the entire previous context in input, whereas without it, embeddings are computed independently.
Via Azure & AWS
jina-embeddings-v3 is now available on AWS SageMaker and Azure Marketplace.


If you need to use it beyond those platforms or on-premises within your company, note that the model is licensed under CC BY-NC 4.0. For commercial usage inquiries, feel free to contact us.
Via Vector Databases & Partners
We closely collaborate with vector database providers such as Pinecone, Qdrant, and Milvus, as well as LLM orchestration frameworks like LlamaIndex, Haystack, and Dify. At the time of release, we are pleased to announce that Pinecone, Qdrant, Milvus and Haystack have already integrated support for jina-embeddings-v3, including the three new parameters: task, dimensions, and late_chunking. Other partners that have already integrated with the v2 API should also support v3 by simply changing the model name to jina-embeddings-v3. However, they may not yet support the new parameters introduced in v3.
Via Pinecone

Via Qdrant

Via Milvus

Via Haystack

Conclusion
In October 2023, we released jina-embeddings-v2-base-en, the world’s first open-source embedding model with an 8K context length. It was the only text embedding model that supported long context and matched OpenAI's text-embedding-ada-002. Today, after a year of learning, experimentation, and valuable lessons, we are proud to release jina-embeddings-v3—a new frontier in text embedding models and a big milestone of our company.
With this release, we continue to excel in what we are known for: long-context embeddings, while also addressing the most requested feature from both the industry and the community—multilingual embeddings. At the same time, we push performance to a new high. With new features such as Task-specific LoRA, MRL, and late chunking, we believe jina-embeddings-v3 will truly serve as the foundational embedding model for various applications, including RAG, agents, and more. Compared to recent LLM-based embeddings like NV-embed-v1/v2, our model is highly parameter-efficient, making it much more suitable for production and edge devices.
Moving forward, we plan to focus on evaluating and improving jina-embeddings-v3 performance on low-resource languages and further analyzing systematic failures caused by limited data availability. Moreover, the model weights of jina-embeddings-v3, along with its innovative features and hot takes, will serve as the foundation for our upcoming models, including jina-clip-v2, jina-reranker-v3, and reader-lm-v2.