Next-Level Cloud AI: Jina Embeddings and Rerankers on Amazon SageMaker
Learn to use Jina Embeddings and Reranking models in a full-stack AI application on AWS, using only components available in Amazon SageMaker and the AWS Marketplace.



Jina Embeddings and Jina Reranker are now available to use with Amazon SageMaker from the AWS Marketplace. For enterprise users who put a high value on security, reliability, and consistency in their cloud operations, this puts Jina AI’s state-of-the-art AI in their private AWS deployments, where they enjoy all the benefits of AWS’s established, stable infrastructure.
With our full array of embedding and reranking models on the AWS Marketplace, SageMaker users can take advantage of ground-breaking 8k input context windows and top-ranking multilingual embeddings on demand at competitive prices. You don’t have to pay to transfer models into or out of AWS, prices are transparent, and your billing is integrated with your AWS account.
The models available on Amazon SageMaker currently include:
- Jina Embeddings v2 Base - English
- Jina Embeddings v2 Small - English
- Jina Embeddings v2 Bilingual Models:
- Jina Embeddings v2 Base - Code
- Jina Reranker v1 Base - English
- Jina ColBERT v1 - English
- Jina ColBERT Reranker v1 - English
For the full list of models, see Jina AI’s vendor page on the AWS Marketplace, and take advantage of a seven-day free trial.


This article will walk you through creating a Retrieval-augmented generation (RAG) application exclusively using components from Amazon SageMaker. The models we will use are Jina Embeddings v2 - English, Jina Reranker v1, and the Mistral-7B-Instruct large language model.
You can also follow along with a Python Notebook, which you can download or run on Google Colab.
Retrieval-Augmented Generation
Retrieval-augmented generation is an alternative paradigm in generative AI. Instead of using large language models (LLMs) to directly answer user requests with what it’s learned in training, it takes advantage of their fluent language production while relocating logic and information retrieval to an external apparatus better suited to it.
Before invoking an LLM, RAG systems actively retrieve relevant information from some external data source and then feed it to the LLM as part of its prompt. The role of the LLM is to synthesize outside information into a coherent response to user requests, minimizing the risk of hallucination and increasing the relevance and usefulness of the result.
A RAG system schematically has at least four components:
- A data source, typically a vector database of some kind, suited to AI-assisted information retrieval.
- An information retrieval system that treats the user’s request as a query, and retrieves data that is relevant to answering it.
- A system, often including an AI-based reranker, that selects some of the retrieved data and processes it into a prompt for an LLM.
- An LLM, for example one of the GPT models or an open-source LLM like Mistral’s, that takes the user request and the data provided to it and generates a response for the user.
Embedding models are well-suited for information retrieval and are often used for that purpose. A text embedding model takes texts as inputs and outputs an embedding — a high-dimensional vector — whose spatial relationship to other embeddings is indicative of their semantic similarity, i.e. similar topics, contents, and related meanings. They are often used in information retrieval because the closer the embeddings, the more likely the user will be happy with the response. They are also relatively easy to fine-tune to improve their performance in specific domains.
Text reranker models use similar AI principles to compare collections of texts to a query and sort them by their semantic similarity. Using a task-specific reranker model, instead of relying on just an embedding model, often dramatically increases the precision of search results. The reranker in a RAG application selects some of the results of information retrieval in order to maximize the probability that the right information is in the prompt to the LLM.

Benchmarking Performance of Embedding Models as SageMaker Endpoints
We tested the performance and reliability of the Jina Embeddings v2 Base - English model as a SageMaker endpoint, running on a g4dn.xlarge instance. In these experiments, we continuously spawned one new user every second, each of whom would send a request, wait for its response, and repeat upon receiving it.
- For requests of less than 100 tokens, for up to 150 concurrent users, the response times per request stayed below 100ms. Then, the response times increased linearly from 100ms to 1500ms with the spawning of more concurrent users.
- At about 300 concurrent users, we received more than 5 failures from the API and ended the test.
- For requests between 1K and 8K tokens, for up to 20 concurrent users, the response times per request stayed below 8s. Then, the response times increased linearly from 8s to 60s with the spawning of more concurrent users.
- At about 140 concurrent users, we received more than 5 failures from the API and ended the test.
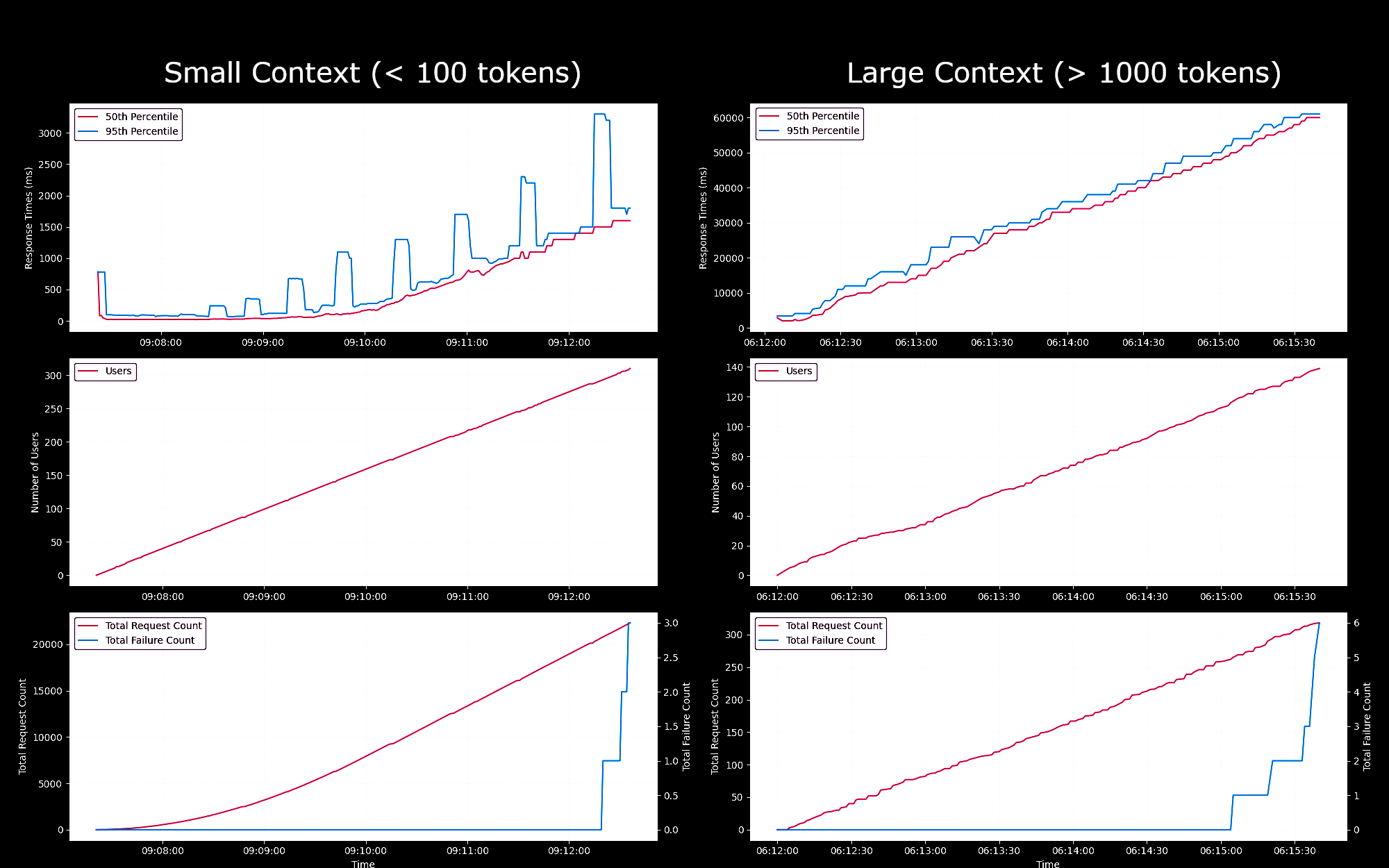
Based on these results, we can conclude that for most users with normal embedding workloads g4dn.xlarge or g5.xlarge instances should meet their daily needs. However, for large indexing jobs, which are typically executed far less often than search tasks, users might prefer a more performant option. For a list of all available Sagemaker instances, please refer to AWS's overview of EC2.
Configure Your AWS account
First, you will need to have an AWS account. If you are not already an AWS user, you can sign up for an account on the AWS website.

Set Up AWS Tools in Your Python Environment
Install in your Python environment the AWS tools and libraries needed for this tutorial:
pip install awscli jina-sagemaker
You will need to get an access key and a secret access key for your AWS account. To do so, follow the instructions on the AWS website.


You will also need to choose an AWS region to work in.
Then, set the values in environment variables. In Python or in a Python notebook, you can do that with the following code:
import os
os.environ["AWS_ACCESS_KEY_ID"] = <YOUR_ACCESS_KEY_ID>
os.environ["AWS_SECRET_ACCESS_KEY"] = <YOUR_SECRET_ACCESS_KEY>
os.environ["AWS_DEFAULT_REGION"] = <YOUR_AWS_REGION>
os.environ["AWS_DEFAULT_OUTPUT"] = "json"
Set the default output to json.
You can also do this via the AWS command line application or by setting up an AWS configuration file on your local filesystem. See the documentation on the AWS website for further details.
Create a Role
You will also need an AWS role with sufficient permissions to use the resources required for this tutorial.
This role must:
- Have AmazonSageMakerFullAccess enabled.
- Either:
- Have authority to make AWS Marketplace subscriptions and have enabled all three of:
- aws-marketplace:ViewSubscriptions
- aws-marketplace:Unsubscribe
- aws-marketplace:Subscribe
- Or your AWS account has a subscription to jina-embedding-model.
- Have authority to make AWS Marketplace subscriptions and have enabled all three of:
Store the ARN (Amazon Resource Name) of the role in the variable name role :
role = <YOUR_ROLE_ARN>
See the documentation for roles on the AWS website for more information.
Subscribe to Jina AI Models on AWS Marketplace
In this article, we will be using the Jina Embeddings v2 base English model. Subscribe to it on the AWS Marketplace.
You will see pricing information by scrolling down on the page. AWS charges by the hour for models from the marketplace, so you will be billed for the time from when you start the model endpoint to when you stop it. This article will show you how to do both.
We will also use the Jina Reranker v1 - English model, which you will need to subscribe to.
When you’ve subscribed to them, get the models’ ARNs for your AWS region and store them in the variable names embedding_package_arn and reranker_package_arn respectively. The code in this tutorial will reference them using those variable names.
If you don’t know how to get the ARNs, put your Amazon region name into the variable region and use the following code:
region = os.environ["AWS_DEFAULT_REGION"]
def get_arn_for_model(region_name, model_name):
model_package_map = {
"us-east-1": f"arn:aws:sagemaker:us-east-1:253352124568:model-package/{model_name}",
"us-east-2": f"arn:aws:sagemaker:us-east-2:057799348421:model-package/{model_name}",
"us-west-1": f"arn:aws:sagemaker:us-west-1:382657785993:model-package/{model_name}",
"us-west-2": f"arn:aws:sagemaker:us-west-2:594846645681:model-package/{model_name}",
"ca-central-1": f"arn:aws:sagemaker:ca-central-1:470592106596:model-package/{model_name}",
"eu-central-1": f"arn:aws:sagemaker:eu-central-1:446921602837:model-package/{model_name}",
"eu-west-1": f"arn:aws:sagemaker:eu-west-1:985815980388:model-package/{model_name}",
"eu-west-2": f"arn:aws:sagemaker:eu-west-2:856760150666:model-package/{model_name}",
"eu-west-3": f"arn:aws:sagemaker:eu-west-3:843114510376:model-package/{model_name}",
"eu-north-1": f"arn:aws:sagemaker:eu-north-1:136758871317:model-package/{model_name}",
"ap-southeast-1": f"arn:aws:sagemaker:ap-southeast-1:192199979996:model-package/{model_name}",
"ap-southeast-2": f"arn:aws:sagemaker:ap-southeast-2:666831318237:model-package/{model_name}",
"ap-northeast-2": f"arn:aws:sagemaker:ap-northeast-2:745090734665:model-package/{model_name}",
"ap-northeast-1": f"arn:aws:sagemaker:ap-northeast-1:977537786026:model-package/{model_name}",
"ap-south-1": f"arn:aws:sagemaker:ap-south-1:077584701553:model-package/{model_name}",
"sa-east-1": f"arn:aws:sagemaker:sa-east-1:270155090741:model-package/{model_name}",
}
return model_package_map[region_name]
embedding_package_arn = get_arn_for_model(region, "jina-embeddings-v2-base-en")
reranker_package_arn = get_arn_for_model(region, "jina-reranker-v1-base-en")
Load the Dataset
In this tutorial, we are going to use a collection of videos provided by the YouTube channel TU Delft Online Learning. This channel produces a variety of educational materials in STEM subjects. Its programming is CC-BY licensed.


We downloaded 193 videos from the channel and processed them with OpenAI’s open-source Whisper speech recognition model. We used the smallest model openai/whisper-tiny to process the videos into transcripts.
The transcripts have been organized into a CSV file, which you can download from here.
Each row of the file contains:
- The video title
- The video URL on YouTube
- A text transcript of the video
To load this data in Python, first install pandas and requests:
pip install requests pandas
Load the CSV data directly into a Pandas DataFrame named tu_delft_dataframe:
import pandas
# Load the CSV file
tu_delft_dataframe = pandas.read_csv("https://raw.githubusercontent.com/jina-ai/workshops/feat-sagemaker-post/notebooks/embeddings/sagemaker/tu_delft.csv")
You can inspect the contents using the DataFrame's head() method. In a notebook, it should look something like this:
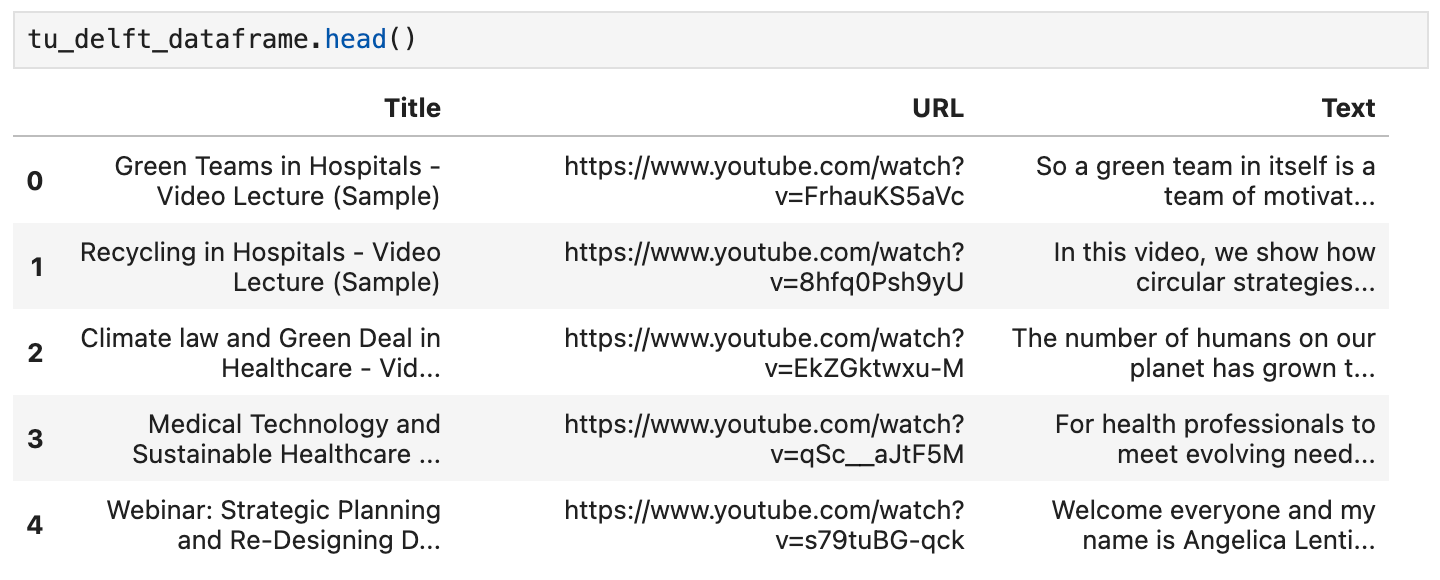
You can also watch the videos by using the URLs given in this dataset and verify that the speech recognition is imperfect but basically sound.
Start the Jina Embeddings v2 Endpoint
The code below will launch an instance of ml.g4dn.xlarge on AWS to run the embedding model. It may take several minutes for this to finish.
import boto3
from jina_sagemaker import Client
# Choose a name for your embedding endpoint. It can be anything convenient.
embeddings_endpoint_name = "jina_embedding"
embedding_client = Client(region_name=boto3.Session().region_name)
embedding_client.create_endpoint(
arn=embedding_package_arn,
role=role,
endpoint_name=embeddings_endpoint_name,
instance_type="ml.g4dn.xlarge",
n_instances=1,
)
embedding_client.connect_to_endpoint(endpoint_name=embeddings_endpoint_name)
Change the instance_type to select a different AWS cloud instance type if appropriate.
Build and Index the Dataset
Now that we have loaded the data and are running a Jina Embeddings v2 model, we can prepare and index the data. We will store the data in a FAISS vector store, an open-source vector database specifically designed for AI applications.
First, install the remaining prerequisites for our RAG application:
pip install tdqm numpy faiss-cpu
Chunking
We will need to take the individual transcripts and split them up into smaller parts, i.e., “chunks,” so that we can fit multiple texts into a prompt for the LLM. The code below breaks the individual transcripts up on sentence boundaries, ensuring that all chunks have no more than 128 words by default.
def chunk_text(text, max_words=128):
"""
Divide text into chunks where each chunk contains the maximum number
of full sentences with fewer words than `max_words`.
"""
sentences = text.split(".")
chunk = []
word_count = 0
for sentence in sentences:
sentence = sentence.strip(".")
if not sentence:
continue
words_in_sentence = len(sentence.split())
if word_count + words_in_sentence <= max_words:
chunk.append(sentence)
word_count += words_in_sentence
else:
# Yield the current chunk and start a new one
if chunk:
yield ". ".join(chunk).strip() + "."
chunk = [sentence]
word_count = words_in_sentence
# Yield the last chunk if it's not empty
if chunk:
yield " ".join(chunk).strip() + "."Get Embeddings for Each Chunk
We need an embedding for each chunk to store it in the FAISS database. To get them, we pass the text chunks to the Jina AI embedding model endpoint, using the method embedding_client.embed(). Then, we add the text chunks and embedding vectors to the pandas dataframe tu_delft_dataframe as the new columns chunks and embeddings:
import numpy as np
from tqdm import tqdm
tqdm.pandas()
def generate_embeddings(text_df):
chunks = list(chunk_text(text_df["Text"]))
embeddings = []
for i, chunk in enumerate(chunks):
response = embedding_client.embed(texts=[chunk])
chunk_embedding = response[0]["embedding"]
embeddings.append(np.array(chunk_embedding))
text_df["chunks"] = chunks
text_df["embeddings"] = embeddings
return text_df
print("Embedding text chunks ...")
tu_delft_dataframe = generate_embeddings(tu_delft_dataframe)
## if you are using Google Colab or a Python notebook, you can
## delete the line above and uncomment the following line instead:
# tu_delft_dataframe = tu_delft_dataframe.progress_apply(generate_embeddings, axis=1)
Set Up Semantic Search Using Faiss
The code below creates a FAISS database and inserts the chunks and embedding vectors by iterating over tu_delft_pandas:
import faiss
dim = 768 # dimension of Jina v2 embeddings
index_with_ids = faiss.IndexIDMap(faiss.IndexFlatIP(dim))
k = 0
doc_ref = dict()
for idx, row in tu_delft_dataframe.iterrows():
embeddings = row["embeddings"]
for i, embedding in enumerate(embeddings):
normalized_embedding = np.ascontiguousarray(np.array(embedding, dtype="float32").reshape(1, -1))
faiss.normalize_L2(normalized_embedding)
index_with_ids.add_with_ids(normalized_embedding, k)
doc_ref[k] = (row["chunks"][i], idx)
k += 1
Start the Jina Reranker v1 Endpoint
As with the Jina Embedding v2 model above, this code will launch an instance of ml.g4dn.xlarge on AWS to run the reranker model. Similarly, it may take several minutes to run.
import boto3
from jina_sagemaker import Client
# Choose a name for your reranker endpoint. It can be anything convenient.
reranker_endpoint_name = "jina_reranker"
reranker_client = Client(region_name=boto3.Session().region_name)
reranker_client.create_endpoint(
arn=reranker_package_arn,
role=role,
endpoint_name=reranker_endpoint_name,
instance_type="ml.g4dn.xlarge",
n_instances=1,
)
reranker_client.connect_to_endpoint(endpoint_name=reranker_endpoint_name)
Define Query Functions
Next, we will define a function that identifies the most similar transcript chunks to any text query.
This is a two-step process:
- Convert user input into an embedding vector using the method
embedding_client.embed(), just like we did in the data preparation stage. - Pass the embedding to the FAISS index to retrieve the best matches. In the function below, the default is to return the 20 best matches, but you can control this with the
nparameter.
The function find_most_similar_transcript_segment will return the best matches by comparing the cosines of the stored embeddings to the query embedding.
def find_most_similar_transcript_segment(query, n=20):
query_embedding = embedding_client.embed(texts=[query])[0]["embedding"] # Assuming the query is short enough to not need chunking
query_embedding = np.ascontiguousarray(np.array(query_embedding, dtype="float32").reshape(1, -1))
faiss.normalize_L2(query_embedding)
D, I = index_with_ids.search(query_embedding, n) # Get the top n matches
results = []
for i in range(n):
distance = D[0][i]
index_id = I[0][i]
transcript_segment, doc_idx = doc_ref[index_id]
results.append((transcript_segment, doc_idx, distance))
# Sort the results by distance
results.sort(key=lambda x: x[2])
return [(tu_delft_dataframe.iloc[r[1]]["Title"].strip(), r[0]) for r in results]
We will also define a function that accesses the reranker endpoint reranker_client, passes it the results from find_most_similar_transcript_segment, and returns just the three most relevant results. It calls the reranker endpoint with the method reranker_client.rerank().
def rerank_results(query_found, query, n=3):
ret = reranker_client.rerank(
documents=[f[1] for f in query_found],
query=query,
top_n=n,
)
return [query_found[r['index']] for r in ret[0]['results']]
Use JumpStart to Load Mistral-Instruct
For this tutorial, we will use the mistral-7b-instruct model, which is available via Amazon SageMaker JumpStart, as the LLM portion of the RAG system.

Run the following code to load and deploy Mistral-Instruct:
from sagemaker.jumpstart.model import JumpStartModel
jumpstart_model = JumpStartModel(model_id="huggingface-llm-mistral-7b-instruct", role=role)
model_predictor = jumpstart_model.deploy()
The endpoint to access this LLM is stored in the variable model_predictor.
Mistral-Instruct with JumpStart
Below is the code to create a prompt template for Mistral-Instruct for this application using Python’s built-in string template class. It assumes that for each query there are three matching transcript chunks that will be presented to the model.
You can experiment with this template yourself to modify this application or see if you can get better results.
from string import Template
prompt_template = Template("""
<s>[INST] Answer the question below only using the given context.
The question from the user is based on transcripts of videos from a YouTube
channel.
The context is presented as a ranked list of information in the form of
(video-title, transcript-segment), that is relevant for answering the
user's question.
The answer should only use the presented context. If the question cannot be
answered based on the context, say so.
Context:
1. Video-title: $title_1, transcript-segment: $segment_1
2. Video-title: $title_2, transcript-segment: $segment_2
3. Video-title: $title_3, transcript-segment: $segment_3
Question: $question
Answer: [/INST]
""")
With this component in place, we now have all the parts of a complete RAG application.
Querying the Model
Querying the model is a three-step process.
- Search for relevant chunks given a query.
- Assemble the prompt.
- Send the prompt to the Mistral-Instruct model and return its answer.
To search for relevant chunks, we use the find_most_similar_transcript_segment function we defined above.
question = "When was the first offshore wind farm commissioned?"
search_results = find_most_similar_transcript_segment(question)
reranked_results = rerank_results(search_results, question)
You can inspect the search results in reranked order:
for title, text, _ in reranked_results:
print(title + "\n" + text + "\n")
Result:
Offshore Wind Farm Technology - Course Introduction
Since the first offshore wind farm commissioned in 1991 in Denmark, scientists and engineers have adapted and improved the technology of wind energy to offshore conditions. This is a rapidly evolving field with installation of increasingly larger wind turbines in deeper waters. At sea, the challenges are indeed numerous, with combined wind and wave loads, reduced accessibility and uncertain-solid conditions. My name is Axel Vire, I'm an assistant professor in Wind Energy at U-Delf and specializing in offshore wind energy. This course will touch upon the critical aspect of wind energy, how to integrate the various engineering disciplines involved in offshore wind energy. Each week we will focus on a particular discipline and use it to design and operate a wind farm.
Offshore Wind Farm Technology - Course Introduction
I'm a researcher and lecturer at the Wind Energy and Economics Department and I will be your moderator throughout this course. That means I will answer any questions you may have. I'll strengthen the interactions between the participants and also I'll get you in touch with the lecturers when needed. The course is mainly developed for professionals in the field of offshore wind energy. We want to broaden their knowledge of the relevant technical disciplines and their integration. Professionals with a scientific background who are new to the field of offshore wind energy will benefit from a high-level insight into the engineering aspects of wind energy. Overall, the course will help you make the right choices during the development and operation of offshore wind farms.
Offshore Wind Farm Technology - Course Introduction
Designed wind turbines that better withstand wind, wave and current loads Identify great integration strategies for offshore wind turbines and gain understanding of the operational and maintenance of offshore wind turbines and farms We also hope that you will benefit from the course and from interaction with other learners who share your interest in wind energy And therefore we look forward to meeting you online.
We can use this information directly in the prompt template:
prompt_for_llm = prompt_template.substitute(
question = question,
title_1 = search_results[0][0],
segment_1 = search_results[0][1],
title_2 = search_results[1][0],
segment_2 = search_results[1][1],
title_3 = search_results[2][0],
segment_3 = search_results[2][1],
)
Print the resulting string to see what prompt is actually sent to the LLM:
print(prompt_for_llm)
<s>[INST] Answer the question below only using the given context.
The question from the user is based on transcripts of videos from a YouTube
channel.
The context is presented as a ranked list of information in the form of
(video-title, transcript-segment), that is relevant for answering the
user's question.
The answer should only use the presented context. If the question cannot be
answered based on the context, say so.
Context:
1. Video-title: Offshore Wind Farm Technology - Course Introduction, transcript-segment: Since the first offshore wind farm commissioned in 1991 in Denmark, scientists and engineers have adapted and improved the technology of wind energy to offshore conditions. This is a rapidly evolving field with installation of increasingly larger wind turbines in deeper waters. At sea, the challenges are indeed numerous, with combined wind and wave loads, reduced accessibility and uncertain-solid conditions. My name is Axel Vire, I'm an assistant professor in Wind Energy at U-Delf and specializing in offshore wind energy. This course will touch upon the critical aspect of wind energy, how to integrate the various engineering disciplines involved in offshore wind energy. Each week we will focus on a particular discipline and use it to design and operate a wind farm.
2. Video-title: Offshore Wind Farm Technology - Course Introduction, transcript-segment: For example, we look at how to characterize the wind and wave conditions at a given location. How to best place the wind turbines in a farm and also how to retrieve the electricity back to shore. We look at the main design drivers for offshore wind turbines and their components. We'll see how these aspects influence one another and the best choices to reduce the cost of energy. This course is organized by the two-delfd wind energy institute, an interfaculty research organization focusing specifically on wind energy. You will therefore benefit from the expertise of the lecturers in three different faculties of the university. Aerospace engineering, civil engineering and electrical engineering. Hi, my name is Ricardo Pareda.
3. Video-title: Systems Analysis for Problem Structuring part 1B the mono actor perspective example, transcript-segment: So let's assume the demarcation of the problem and the analysis of objectives has led to the identification of three criteria. The security of supply, the percentage of offshore power generation and the costs of energy provision. We now reason backwards to explore what factors have an influence on these system outcomes. Really, the offshore percentage is positively influenced by the installed Wind Power capacity at sea, a key system factor. Capacity at sea in turn is determined by both the size and the number of wind farms at sea. The Ministry of Economic Affairs cannot itself invest in new wind farms but hopes to simulate investors and energy companies by providing subsidies and by expediting the granting process of licenses as needed.
Question: When was the first offshore wind farm commissioned?
Answer: [/INST]
Pass this prompt to the LLM endpoint — model_predictor — via the method model_predictor.predict():
answer = model_predictor.predict({"inputs": prompt_for_llm})
This returns a list, but since we only passed in one prompt, it will be a list with one entry. Each entry is a dict with the response text under the key generated_text:
answer = answer[0]['generated_text']
print(answer)
Result:
The first offshore wind farm was commissioned in 1991. (Context: Video-title: Offshore Wind Farm Technology - Course Introduction, transcript-segment: Since the first offshore wind farm commissioned in 1991 in Denmark, ...)
Let’s simplify querying by writing a function to do all the steps: taking the string question as a parameter and returning the answer as a string:
def ask_rag(question):
search_results = find_most_similar_transcript_segment(question)
reranked_results = rerank_results(search_results, question)
prompt_for_llm = prompt_template.substitute(
question = question,
title_1 = search_results[0][0],
segment_1 = search_results[0][1],
title_2 = search_results[1][0],
segment_2 = search_results[1][1],
title_3 = search_results[2][0],
segment_3 = search_results[2][1],
)
answer = model_predictor.predict({"inputs": prompt_for_llm})
return answer[0]["generated_text"]
Now we can ask it a few more questions. Answers will depend on the content of the video transcripts. For example, we can ask detailed questions when the answer is present in the data and get an answer:
ask_rag("What is a Kaplan Meyer estimator?")
The Kaplan Meyer estimator is a non-parametric estimator for the survival
function, defined for both censored and not censored data. It is represented
as a series of declining horizontal steps that approaches the truths of the
survival function if the sample size is sufficiently large enough. The value
of the empirical survival function obtained is assumed to be constant between
two successive distinct observations.
ask_rag("Who is Reneville Solingen?")
Reneville Solingen is a professor at Delft University of Technology in Global
Software Engineering. She is also a co-author of the book "The Power of Scrum."
answer = ask_rag("What is the European Green Deal?")
print(answer)
The European Green Deal is a policy initiative by the European Union to combat
climate change and decarbonize the economy, with a goal to make Europe carbon
neutral by 2050. It involves the use of green procurement strategies in various
sectors, including healthcare, to reduce carbon emissions and promote corporate
social responsibility.
We can also ask questions that are outside of the scope of the available information:
ask_rag("What countries export the most coffee?")
Based on the context provided, there is no clear answer to the user's
question about which countries export the most coffee as the context
only discusses the Delft University's cafeteria discounts and sustainable
coffee options, as well as lithium production and alternatives for use in
electric car batteries.
ask_rag("How much wood could a woodchuck chuck if a woodchuck could chuck wood?")
The context does not provide sufficient information to answer the question.
The context is about thermit welding of rails, stress concentration factors,
and a lyrics video. There is no mention of woodchucks or the ability of
woodchuck to chuck wood in the context.
Try your own queries. You can also change the way the LLM is prompted to see if that improves your results.
Shutting Down
Because you are billed by the hour for the models you use and for the AWS infrastructure to run them, it is very important to stop all three AI models when you finish this tutorial:
- The embedding model endpoint
embedding_client - The reranker model endpoint
reranker_client - The large language model endpoint
model_predictor
To shut down all three model endpoints, run the following code:
# shut down the embedding endpoint
embedding_client.delete_endpoint()
embedding_client.close()
# shut down the reranker endpoint
reranker_client.delete_endpoint()
reranker_client.close()
# shut down the LLM endpoint
model_predictor.delete_model()
model_predictor.delete_endpoint()
Get Started Now with Jina AI Models on AWS Marketplace
With our embedding and reranking models on SageMaker, enterprise AI users on AWS now have instant access to Jina AI’s outstanding value proposition without compromising the benefits of their existing cloud operations. All the security, reliability, consistency, and predictable pricing of AWS comes built-in.
At Jina AI, we are working hard to bring the state-of-the-art to businesses that can benefit from bringing AI into their existing processes. We strive to offer solid, reliable, high-performance models at accessible prices via convenient and practical interfaces, minimizing your investments in AI while maximizing your returns.
Check out Jina AI’s AWS Marketplace page for a list of all embeddings and reranker models that we offer and to try our models free for seven days.
We would love to hear about your use cases and talk about how Jina AI’s products can fit your business needs. Contact us via our website or our Discord channel to share your feedback and stay up-to-date with our latest models.