RAG is Dead, Again?
RAG is just one algorithmic pattern you can use. But if you make it *the* algorithm and idolize it, then you are living in a bubble you created, and the bubble will burst.


It is hard to tell if people hate to love RAG or love to hate RAG.
According to recent discussions on X and HN, RAG should be dead, again. This time, critics are focusing on the over-engineering of most RAG frameworks, which, as @jeremyphoward @HamelHusain @Yampeleg demonstrated, could be accomplished with 20 lines of Python code.
T H A N K Y O U ! ! !
— Yam Peleg (@Yampeleg) May 23, 2024
(v 2.0)
Full RAG in 20 lines.
This is how you implement semantic search in ~10 lines
Replace 𝚌𝚘𝚗𝚝𝚎𝚡𝚝𝚜 & 𝚚𝚞𝚎𝚜𝚝𝚒𝚘𝚗 with your own.
* the blurred code is for loading example contexts
(Everything from FastAI's guide:https://t.co/qBpU6T2Fd1) https://t.co/Or3eJEbSt9 pic.twitter.com/e2q70H6QaY
The last time we had this vibe was shortly after the release of Claude/Gemini with a super long context window. What makes this time worse is that even Google's RAG generates funny results as @icreatelife @mark_riedl showed, which is ironic because back in April, at Google Next in Las Vegas, Google presented RAG as the grounding solution.
I couldn’t believe it before I tried it. Google needs to fix this asap.. pic.twitter.com/r3FyOfxiTK
— Kris Kashtanova (@icreatelife) May 23, 2024
Yes! My website poisoning attack works on Google's new LLM-powered AI overviews! pic.twitter.com/nWyMtl7nMj
— Mark Riedl (@mark_riedl) May 22, 2024
Two problems of RAG
I see two problems with the RAG frameworks and solutions we have today.
Feed-forward only
First, nearly all RAG frameworks implement only a "feed-forward" path and lack a "back-propagation" path. It is an incomplete system. I remember @swyx, in one of the episodes of @latentspacepod, arguing that RAG will not be killed by the long context window of LLMs since:
- long context is expensive for devs and
- long context is hard to debug and lacks decomposability.
But if all RAG frameworks focus only on the forwarding path, how is it easier to debug than an LLM? It is also interesting how many people get overexcited by the auto-magical results of RAG from some random POCs and completely forget that adding more forward layers without backward tuning is a terrible idea. We all know that adding one more layer to your neural networks expands its parametric space and hence representation ability, enabling it to do more potential things, but without training, this is nothing. There are quite some startups in the Bay Area working on evaluation—essentially trying to evaluate the loss of a feed-forward system. Is it useful? Yes. But does it help close the loop of RAG? No.
So who is working on the back-propagation of RAG? Afaik not many. I am mostly familiar with DSPy, a library from @stanfordnlp @lateinteraction that sets its mission on that.
 stanfordnlp
stanfordnlpBut even for DSPy, the main focus is on optimizing few-shot demonstrations, not the full system (or at least from community usage). But why is this problem difficult? Because the signal is very sparse, and optimizing a non-differentiable pipeline system is essentially a combinatorial problem—in other words, extremely hard. I learned some submodular optimization during my PhD, and I have a feeling that this technique will be put to good use in RAG optimization.
Grounding in the wild is hard
I do agree that RAG is for grounding, despite the funny search results from Google. There are two types of grounding: search grounding, which uses search engines to extend the world knowledge of LLMs, and check grounding, which uses private knowledge (e.g. proprietary data) to do fact-checking.
In both cases, it cites external knowledge to improve the factuality of the result, provided that these external resources are trustworthy. In Google's funny search result, one can easily see that not everything on the web is trustworthy (yeah, big surprise, who would thought!), which makes search grounding look bad. But I do believe you can only laugh at it for now. There are some implicit feedback mechanisms behind the Google Search UI that collect users' reactions to those results and weight the credibility of the website for better grounding. In general, it should be pretty temporary, as this RAG just needs to get past the cold start, and results will improve over time.
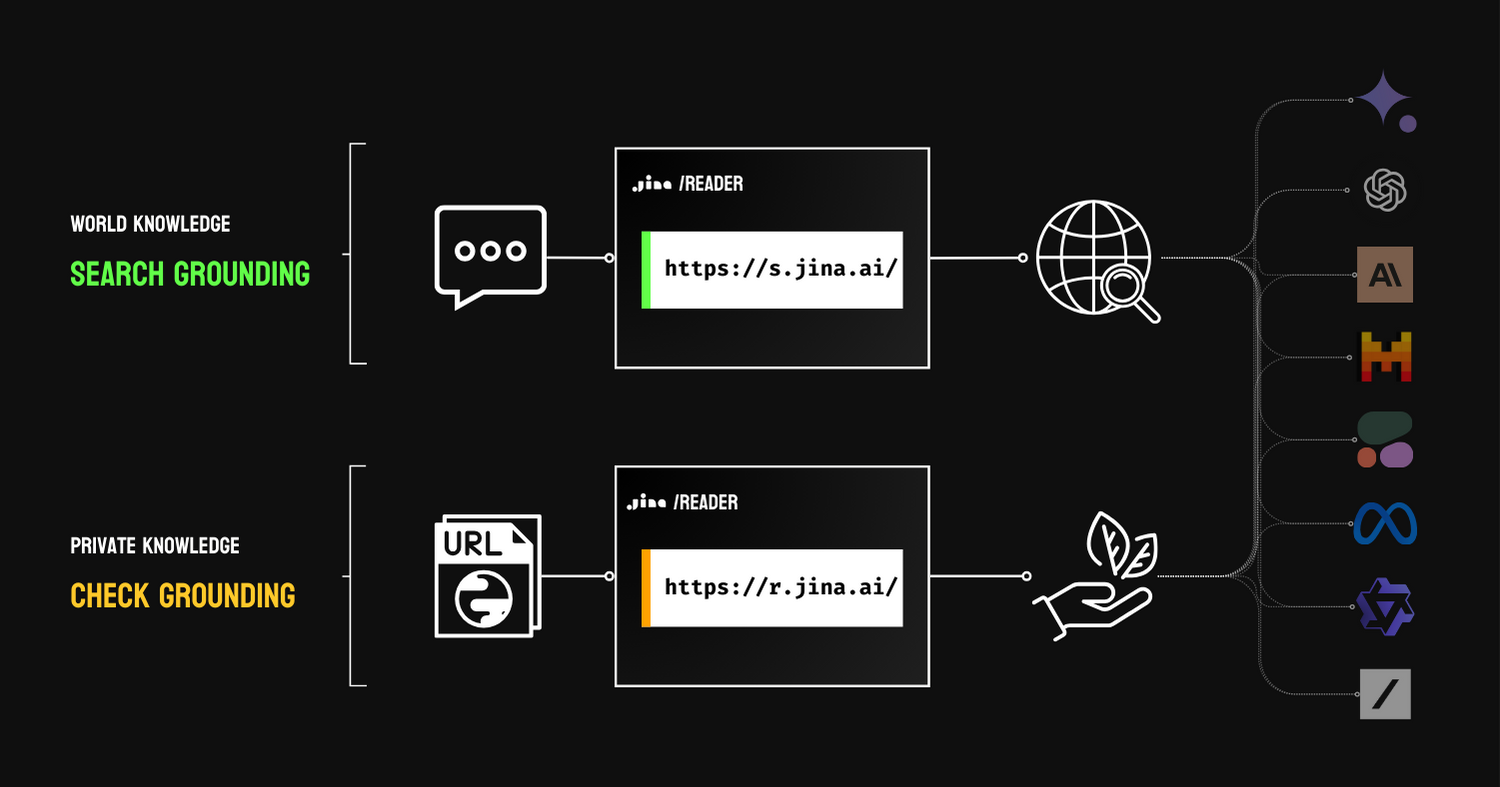


RAG was presented as a grounding solution in the Google Next conference.
My Take
RAG is neither dead nor alive; so stop arguing about it. RAG is just one algorithmic pattern you can use. But if you make it the algorithm and idolize it, then you are living in a bubble you created, and the bubble will burst.