ReaderLM v2: Frontier Small Language Model for HTML to Markdown and JSON
ReaderLM-v2 is a 1.5B small language model for HTML-to-Markdown conversion and HTML-to-JSON extraction with exceptional quality.



In April 2024, we launched Jina Reader, an API that transforms any webpage into LLM-friendly markdown by simply adding r.jina.ai as a URL prefix. In September 2024, we launched two small language models, reader-lm-0.5b and reader-lm-1.5b, specifically designed to convert raw HTML into clean markdown. Today, we're excited to introduce ReaderLM's second generation, a 1.5B parameter language model that converts raw HTML into beautifully formatted markdown or JSON with superior accuracy and improved longer context handling. ReaderLM-v2 handles up to 512K tokens combined input and output length. The model offers multilingual support across 29 languages, including English, Chinese, Japanese, Korean, French, Spanish, Portuguese, German, Italian, Russian, Vietnamese, Thai, Arabic, and more.
Thanks to its new training paradigm and higher-quality training data, ReaderLM-v2 is a significant leap forward from its predecessor, particularly in handling long-context and markdown syntax generation. While the first generation approached HTML-to-markdown conversion as a "selective-copy" task, v2 treats it as a true translation process. This shift enables the model to masterfully leverage markdown syntax, excelling at generating complex elements like code fences, nested lists, tables and LaTex equations.
Comparing HTML-to-markdown results of HackerNews front page across ReaderLM v2, ReaderLM 1.5b, Claude 3.5 Sonnet, and Gemini 2.0 Flash reveals ReaderLM v2's unique vibe and performance. ReaderLM v2 excels at preserving comprehensive information from raw HTML, including original HackerNews links, while smartly structuring the content using markdown syntax. The model uses nested lists to organize local elements (points, timestamps, and comments) while maintaining consistent global formatting through proper heading hierarchy (h1 and h2 tags).
A major issue in our first version was degeneration, particularly in the form of repetition and looping after generating long sequences. The model would either begin repeating the same token or get stuck in a loop, cycling through a short sequence of tokens until reaching the maximum output length. ReaderLM-v2 greatly alleviates this issue by adding contrastive loss during training—its performance remains consistent regardless of context length or the amount of tokens already generated.

reader-lm-1.5b, which would degenerate after generating long sequences.Beyond markdown conversion, ReaderLM-v2 introduces direct HTML-to-JSON generation, allowing users to extract specific information from raw HTML following a given JSON schema. This end-to-end approach eliminates the need for intermediate markdown conversion, a common requirement in many LLM-powered data cleaning and extraction pipelines.

In both quantitative and qualitative benchmarks, ReaderLM-v2 outperforms much larger models like Qwen2.5-32B-Instruct, Gemini2-flash-expr, and GPT-4o-2024-08-06 on HTML-to-Markdown tasks while showing comparable performance on HTML-to-JSON extraction tasks, all while using significantly fewer parameters.

ReaderLM-v2-pro is an exclusive premium checkpoint reserved for our enterprise customers, featuring additional training and optimizations. 


These results establish that a well-designed 1.5B parameter model can not only match but often exceed the performance of much larger models in structured data extraction tasks. The progressive improvements from ReaderLM-v2 to ReaderLM-v2-pro demonstrate the effectiveness of our new training strategy in improving model performance while maintaining computational efficiency.
Get Started
Via Reader API

ReaderLM-v2 is now integrated with our Reader API. To use it, simply specify x-engine: readerlm-v2 in your request headers and enable response streaming with -H 'Accept: text/event-stream':
curl https://r.jina.ai/https://news.ycombinator.com/ -H 'x-engine: readerlm-v2' -H 'Accept: text/event-stream'
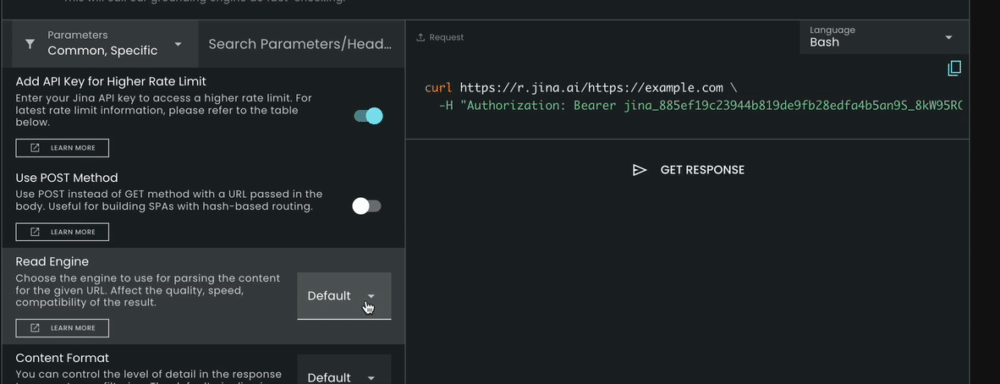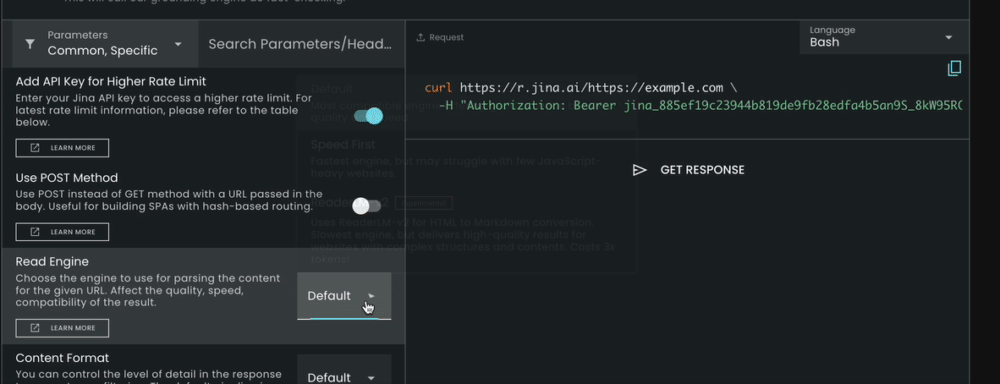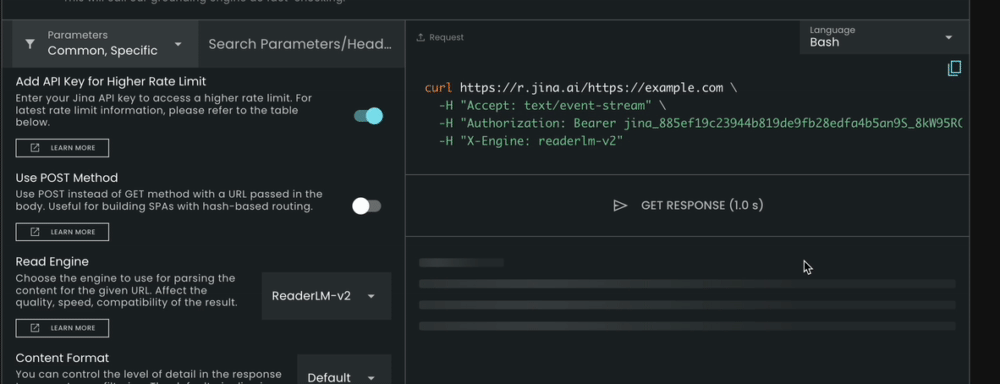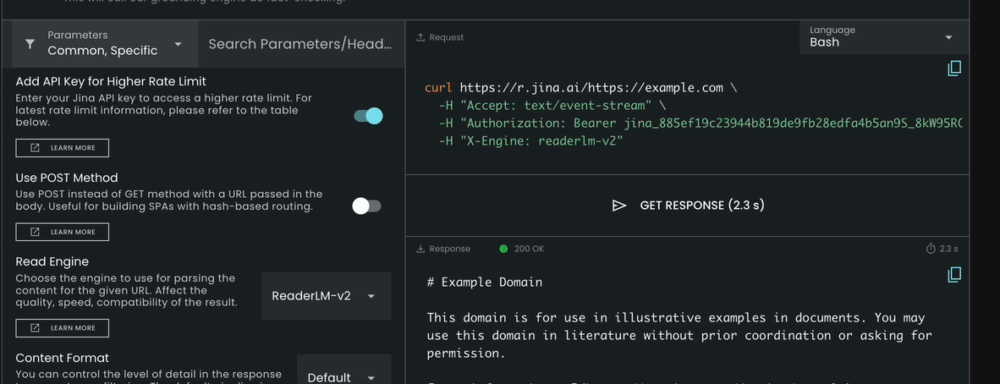
ReaderLM-v2 as the "Read Engine" and check the result in real-time.You can try it without an API key at a lower rate limit. For higher rate limits, you can purchase an API key. Please note that ReaderLM-v2 requests consume 3x the normal token count from your API key. This feature is currently in beta while we collaborate with the GCP team to optimize GPU efficiency and increase model availability.
On Google Colab

Note that the free T4 GPU has limitations—it doesn't support bfloat16 or flash attention 2, leading to higher memory usage and slower processing of longer inputs. Nevertheless, ReaderLM v2 successfully processes our entire legal page under these constraints, achieving processing speeds of 67 tokens/s input and 36 tokens/s output. For production use, we recommend an RTX 3090/4090 for optimal performance.
The simplest way to try ReaderLM-v2 in a hosted environment is through our Colab notebook, which demonstrates HTML-to-markdown conversion, JSON extraction, and instruction-following using the HackerNews frontpage as an example. The notebook is optimized for Colab's free T4 GPU tier and requires vllm and triton for acceleration and running. Feel free to test it with any website.
HTML to Markdown conversion
You can use create_prompt helper function to easily create a prompt for converting HTML to Markdown:
prompt = create_prompt(html)
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()result will be a string wrapped in Markdown backticks as a code fence. You can also override the default settings to explore different outputs, for example:
prompt = create_prompt(html, instruction="Extract the first three news and put into in the makdown list")
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()However, since our training data may not cover every type of instruction, particularly tasks that require multi-step reasoning, the most reliable results come from HTML-to-Markdown conversion. For the most effective information extraction, we recommend using JSON schema as shown below:
HTML to JSON extraction with JSON schema
import json
schema = {
"type": "object",
"properties": {
"title": {"type": "string", "description": "News thread title"},
"url": {"type": "string", "description": "Thread URL"},
"summary": {"type": "string", "description": "Article summary"},
"keywords": {"type": "list", "description": "Descriptive keywords"},
"author": {"type": "string", "description": "Thread author"},
"comments": {"type": "integer", "description": "Comment count"}
},
"required": ["title", "url", "date", "points", "author", "comments"]
}
prompt = create_prompt(html, schema=json.dumps(schema, indent=2))
result = llm.generate(prompt, sampling_params=sampling_params)[0].outputs[0].text.strip()
result will be a string wrapped in JSON-formatted code fence backticks, not an actual JSON/dict object. You can use Python to parse the string into a proper dictionary or JSON object for further processing.
In Production: Available on CSP
ReaderLM-v2 is available on AWS SageMaker, Azure and GCP marketplace. If you need to use these models beyond those platforms or on-premises within your company, note that this model and ReaderLM-v2-pro are both licensed under CC BY-NC 4.0. For commercial usage inquiries or the access to ReaderLM-v2-pro, feel free to contact us.

Quantitative Evaluation
We evaluate ReaderLM-v2 on three structured data extraction tasks against state-of-the-art models: GPT-4o-2024-08-06, Gemini2-flash-expr, and Qwen2.5-32B-Instruct. Our assessment framework combines metrics that measure both content accuracy and structural fidelity. ReaderLM-v2 is the publicly available version with open weights, while ReaderLM-v2-pro is an exclusive premium checkpoint reserved for our enterprise customers, featuring additional training and optimizations. Note that our first generation reader-lm-1.5b is only evaluated on the main content extraction task, as it does not support instructed extraction or JSON extraction capabilities.
Evaluation Metrics
For HTML-to-Markdown tasks, we employ seven complementary metrics. Note: ↑ indicates higher is better, ↓ indicates lower is better
- ROUGE-L (↑): Measures the longest common subsequence between generated and reference text, capturing content preservation and structural similarity. Range: 0-1, higher values indicate better sequence matching.
- WER (Word Error Rate) (↓): Quantifies the minimum number of word-level edits required to transform the generated text into the reference. Lower values indicate fewer necessary corrections.
- SUB (Substitutions) (↓): Counts the number of word substitutions needed. Lower values suggest better word-level accuracy.
- INS (Insertions) (↓): Measures the number of words that need to be inserted to match the reference. Lower values indicate better completeness.
- Levenshtein Distance (↓): Calculates the minimum number of single-character edits required. Lower values suggest better character-level accuracy.
- Damerau-Levenshtein Distance (↓): Similar to Levenshtein but also considers character transpositions. Lower values indicate better character-level matching.
- Jaro-Winkler Similarity (↑): Emphasizes matching characters at string beginnings, particularly useful for evaluating document structure preservation. Range: 0-1, higher values indicate better similarity.
For HTML-to-JSON tasks, we consider it as retrieval task and adopt four metrics from information retrieval:
- F1 Score (↑): Harmonic mean of precision and recall, providing overall accuracy. Range: 0-1.
- Precision (↑): Proportion of correctly extracted information among all extractions. Range: 0-1.
- Recall (↑): Proportion of correctly extracted information from all available information. Range: 0-1.
- Pass-Rate (↑): Proportion of outputs that are valid JSON and conform to the schema. Range: 0-1.
Main Content HTML-to-Markdown Task
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.69 | 0.62 | 131.06 | 372.34 | 0.40 | 1341.14 | 0.74 |
| gpt-4o-2024-08-06 | 0.69 | 0.41 | 88.66 | 88.69 | 0.40 | 1283.54 | 0.75 |
| Qwen2.5-32B-Instruct | 0.71 | 0.47 | 158.26 | 123.47 | 0.41 | 1354.33 | 0.70 |
| reader-lm-1.5b | 0.72 | 1.14 | 260.29 | 1182.97 | 0.35 | 1733.11 | 0.70 |
| ReaderLM-v2 | 0.84 | 0.62 | 135.28 | 867.14 | 0.22 | 1262.75 | 0.82 |
| ReaderLM-v2-pro | 0.86 | 0.39 | 162.92 | 500.44 | 0.20 | 928.15 | 0.83 |
Instructed HTML-to-Markdown Task
| Model | ROUGE-L↑ | WER↓ | SUB↓ | INS↓ | Levenshtein↓ | Damerau↓ | Jaro-Winkler↑ |
|---|---|---|---|---|---|---|---|
| Gemini2-flash-expr | 0.64 | 1.64 | 122.64 | 533.12 | 0.45 | 766.62 | 0.70 |
| gpt-4o-2024-08-06 | 0.69 | 0.82 | 87.53 | 180.61 | 0.42 | 451.10 | 0.69 |
| Qwen2.5-32B-Instruct | 0.68 | 0.73 | 98.72 | 177.23 | 0.43 | 501.50 | 0.69 |
| ReaderLM-v2 | 0.70 | 1.28 | 75.10 | 443.70 | 0.38 | 673.62 | 0.75 |
| ReaderLM-v2-pro | 0.72 | 1.48 | 70.16 | 570.38 | 0.37 | 748.10 | 0.75 |
Schema-based HTML-to-JSON Task
| Model | F1↑ | Precision↑ | Recall↑ | Pass-Rate↑ |
|---|---|---|---|---|
| Gemini2-flash-expr | 0.81 | 0.81 | 0.82 | 0.99 |
| gpt-4o-2024-08-06 | 0.83 | 0.84 | 0.83 | 1.00 |
| Qwen2.5-32B-Instruct | 0.83 | 0.85 | 0.83 | 1.00 |
| ReaderLM-v2 | 0.81 | 0.82 | 0.81 | 0.98 |
| ReaderLM-v2-pro | 0.82 | 0.83 | 0.82 | 0.99 |
ReaderLM-v2 represents a significant advancement across all tasks. For main content extraction, ReaderLM-v2-pro achieves the best performance in five out of seven metrics, with superior ROUGE-L (0.86), WER (0.39), Levenshtein (0.20), Damerau (928.15), and Jaro-Winkler (0.83) scores. These results demonstrate comprehensive improvements in both content preservation and structural accuracy compared to both its base version and larger models.
In instructed extraction, ReaderLM-v2 and ReaderLM-v2-pro leads in ROUGE-L (0.72), substitution rate (70.16), Levenshtein distance (0.37), and Jaro-Winkler similarity (0.75, tied with base version). While GPT-4o shows advantages in WER and Damerau distance, ReaderLM-v2-pro maintains better overall content structure and accuracy. In JSON extraction, the model performs competitively, staying within 0.01-0.02 F1 points of larger models while achieving high pass rates (0.99).
Qualitative Evaluation
During our analysis of reader-lm-1.5b, we observed that quantitative metrics alone may not fully capture model performance. Numerical evaluations sometimes failed to reflect perceptual quality—cases where low metric scores produced visually satisfactory markdown, or high scores yielded suboptimal results. To address this discrepancy, we conducted systematic qualitative assessments across 10 diverse HTML sources, including news articles, blog posts, product pages, e-commerce sites, and legal documents in English, Japanese, and Chinese. The test corpus emphasized challenging formatting elements such as multi-row tables, dynamic layouts, LaTeX formulas, linked tables, and nested lists, providing a more comprehensive view of real-world model capabilities.
Evaluation Metrics
Our human assessment focused on three key dimensions, with outputs rated on a 1-5 scale:
Content Integrity - Evaluates preservation of semantic information during HTML-to-markdown conversion, including:
- Text content accuracy and completeness
- Preservation of links, images, code blocks, formulas, and quotes
- Retention of text formatting and link/image URLs
Structural Accuracy - Assesses accurate conversion of HTML structural elements to Markdown:
- Header hierarchy preservation
- List nesting accuracy
- Table structure fidelity
- Code block and quote formatting
Format Compliance - Measures adherence to Markdown syntax standards:
- Proper syntax usage for headers (#), lists (*, +, -), tables, code blocks (```)
- Clean formatting without excess whitespace or non-standard syntax
- Consistent and readable rendered output
As we manually evaluate over 10 HTML pages, each evaluation criterion has a maximum score of 50 points. ReaderLM-v2 demonstrated strong performance across all dimensions:
| Metric | Content Integrity | Structural Accuracy | Format Compliance |
|---|---|---|---|
| reader-lm-v2 | 39 | 35 | 36 |
| reader-lm-v2-pro | 35 | 37 | 37 |
| reader-lm-v1 | 35 | 34 | 31 |
| Claude 3.5 Sonnet | 26 | 31 | 33 |
| gemini-2.0-flash-expr | 35 | 31 | 28 |
| Qwen2.5-32B-Instruct | 32 | 33 | 34 |
| gpt-4o | 38 | 41 | 42 |
For content completeness, it excelled at complex element recognition, particularly LaTeX formulas, nested lists, and code blocks. The model maintained high fidelity when handling complex content structures while competing models often dropped H1 headers (reader-lm-1.5b), truncated content (Claude 3.5), or retained raw HTML tags (Gemini-2.0-flash).
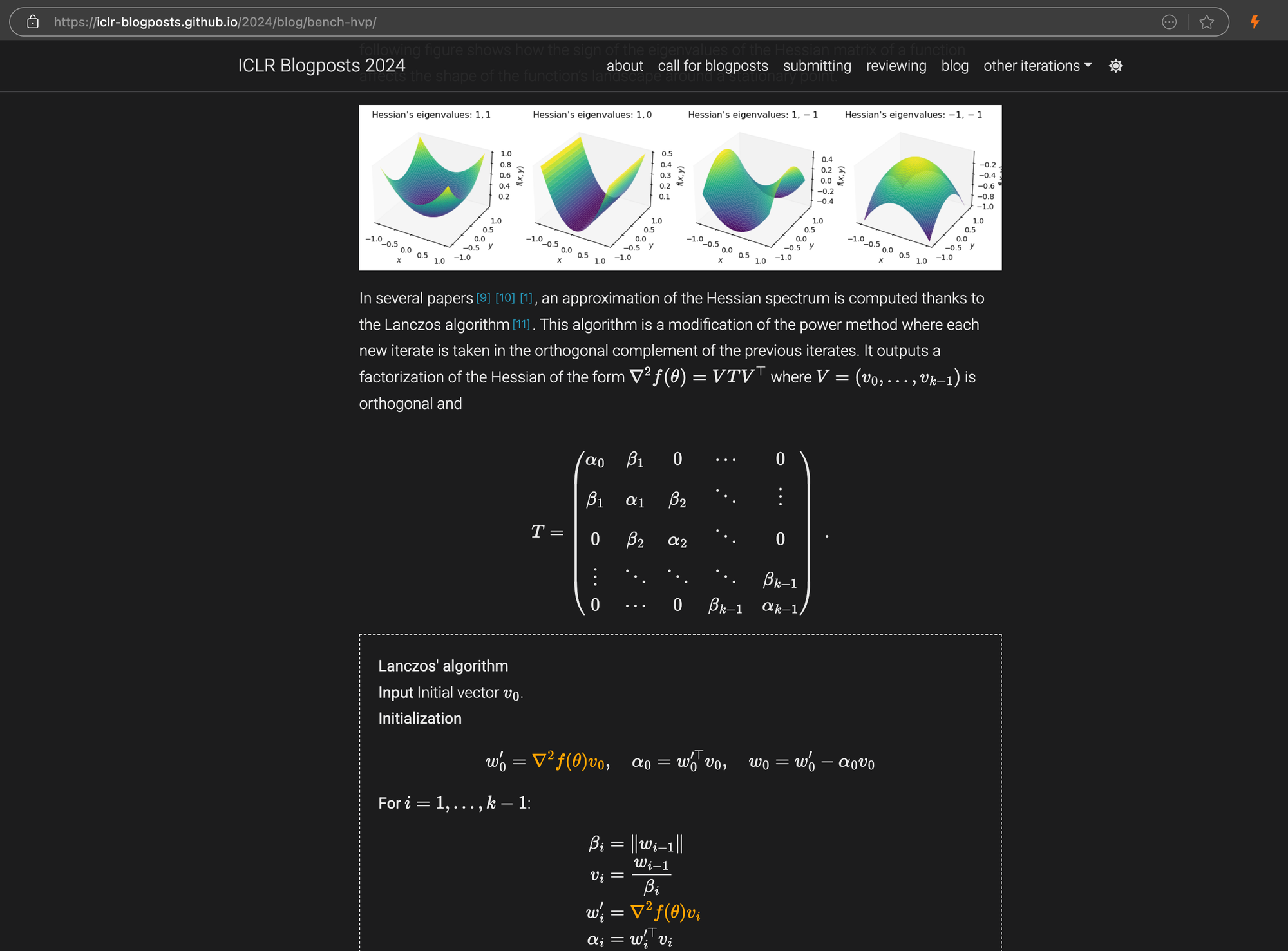
An ICLR blog post with complex LaTeX equations embedded in markdown, showing the source HTML code on the right panel.
\[...\] (and its HTML equivalents) with Markdown-standard delimiters like $...$ for inline equations and $$...$$ for display equations. This helps prevent syntax conflicts in Markdown interpretation.In structural accuracy, ReaderLM-v2 showed optimization for common web structures. For example, in Hacker News cases, it successfully reconstructed complete links and optimized list presentation. The model handled complex non-blog HTML structures that challenged ReaderLM-v1.
For format compliance, ReaderLM-v2 demonstrated particular strength in handling content like Hacker News, blogs, and WeChat articles. While other large language models performed well on markdown-like sources, they struggled with traditional websites requiring more interpretation and reformatting.
Our analysis revealed that gpt-4o excels at processing shorter websites, demonstrating superior understanding of site structure and formatting compared to other models. However, when handling longer content, gpt-4o struggles with completeness, often omitting portions from the beginning and end of the text. We've included a comparative analysis of outputs from gpt-4o, ReaderLM-v2, and ReaderLM-v2-pro using Zillow's website as an example.
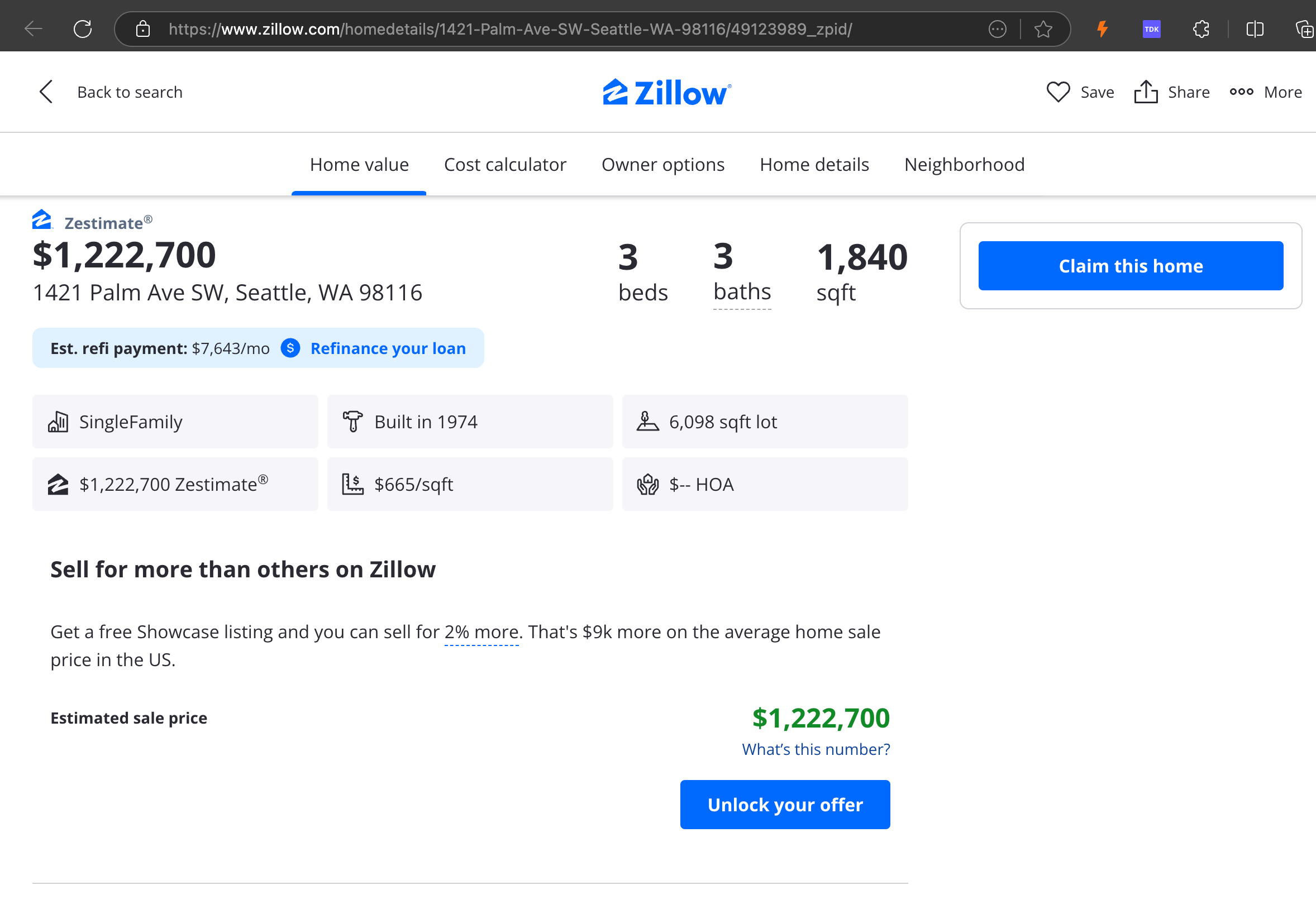
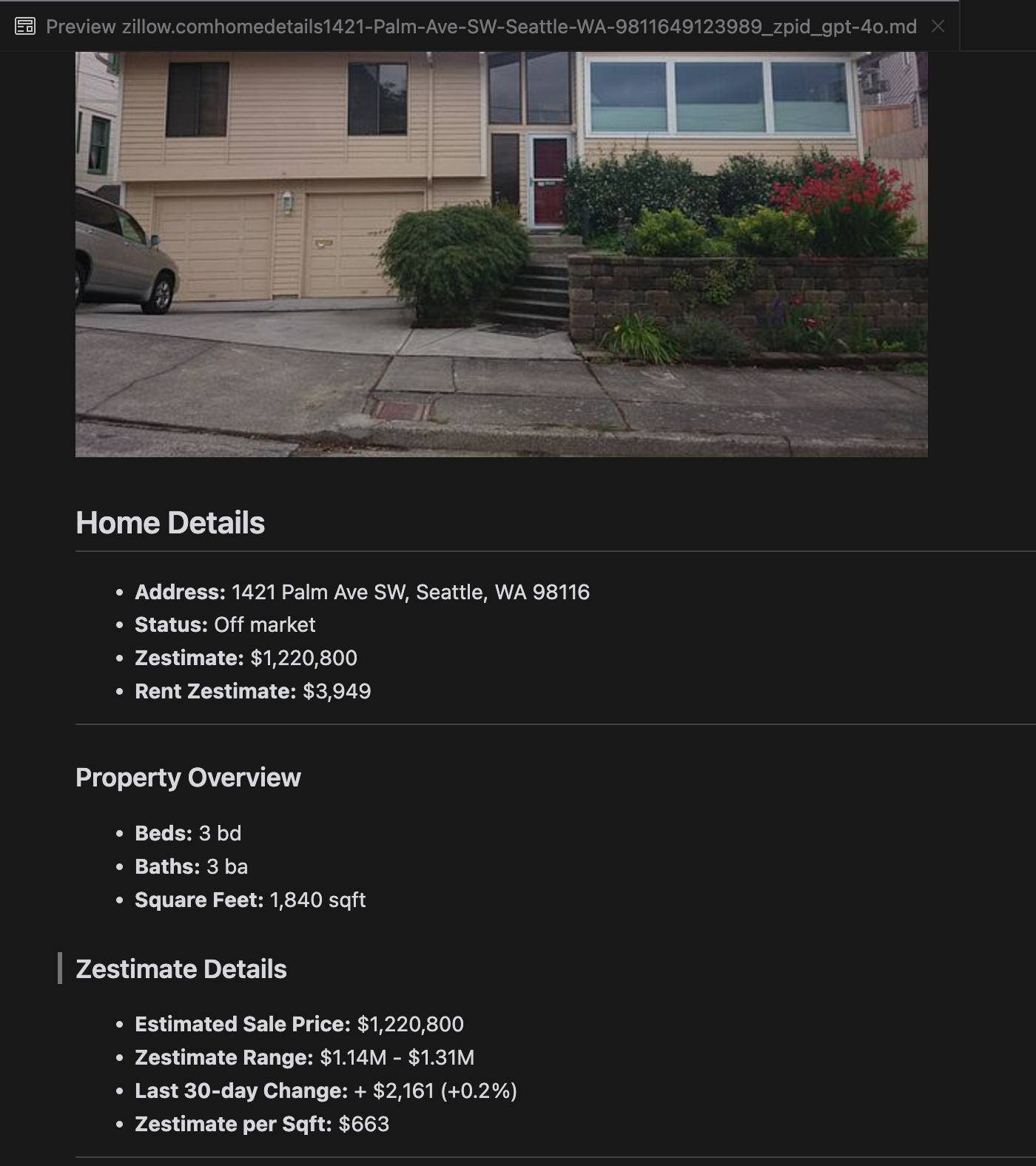
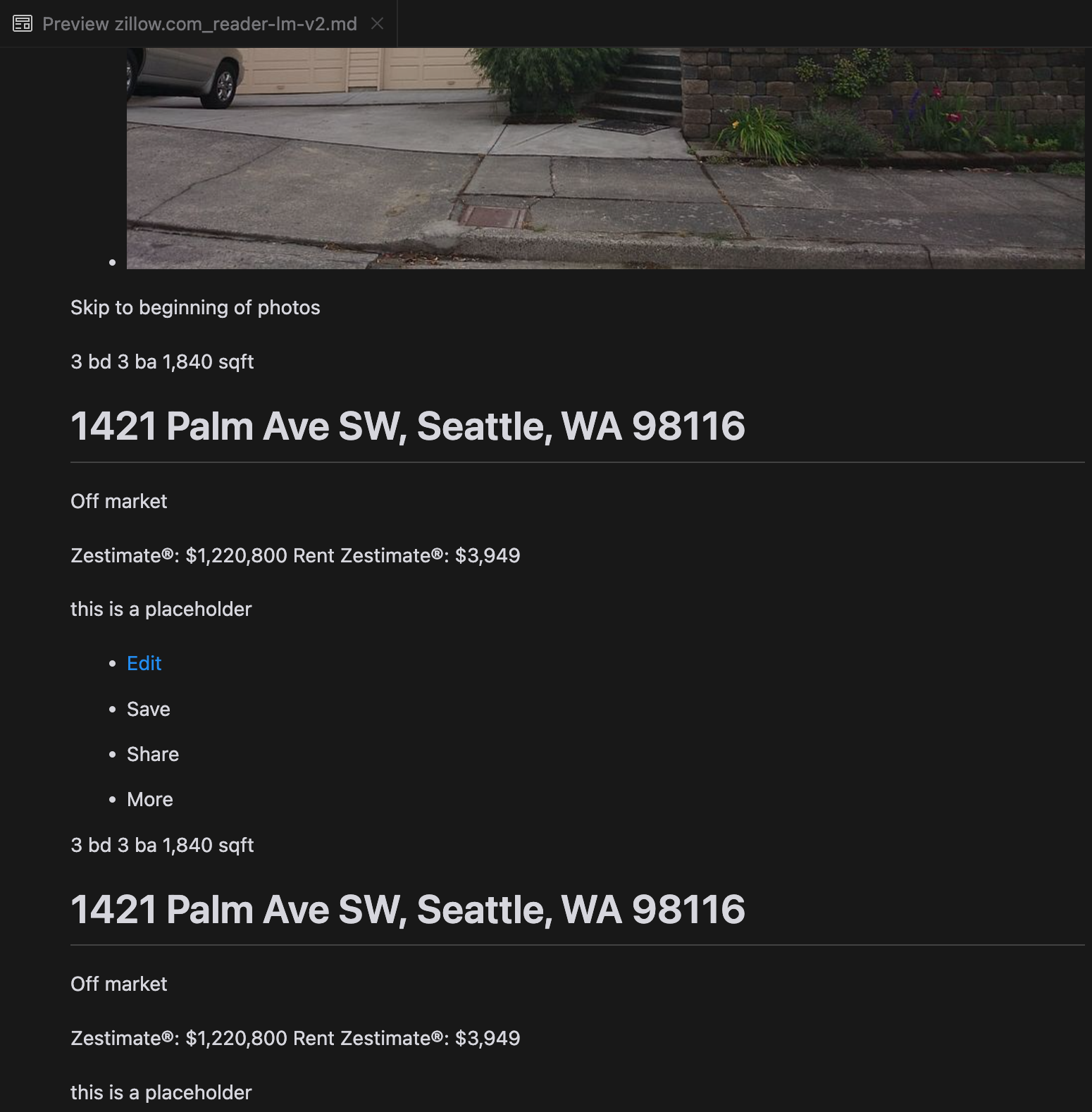
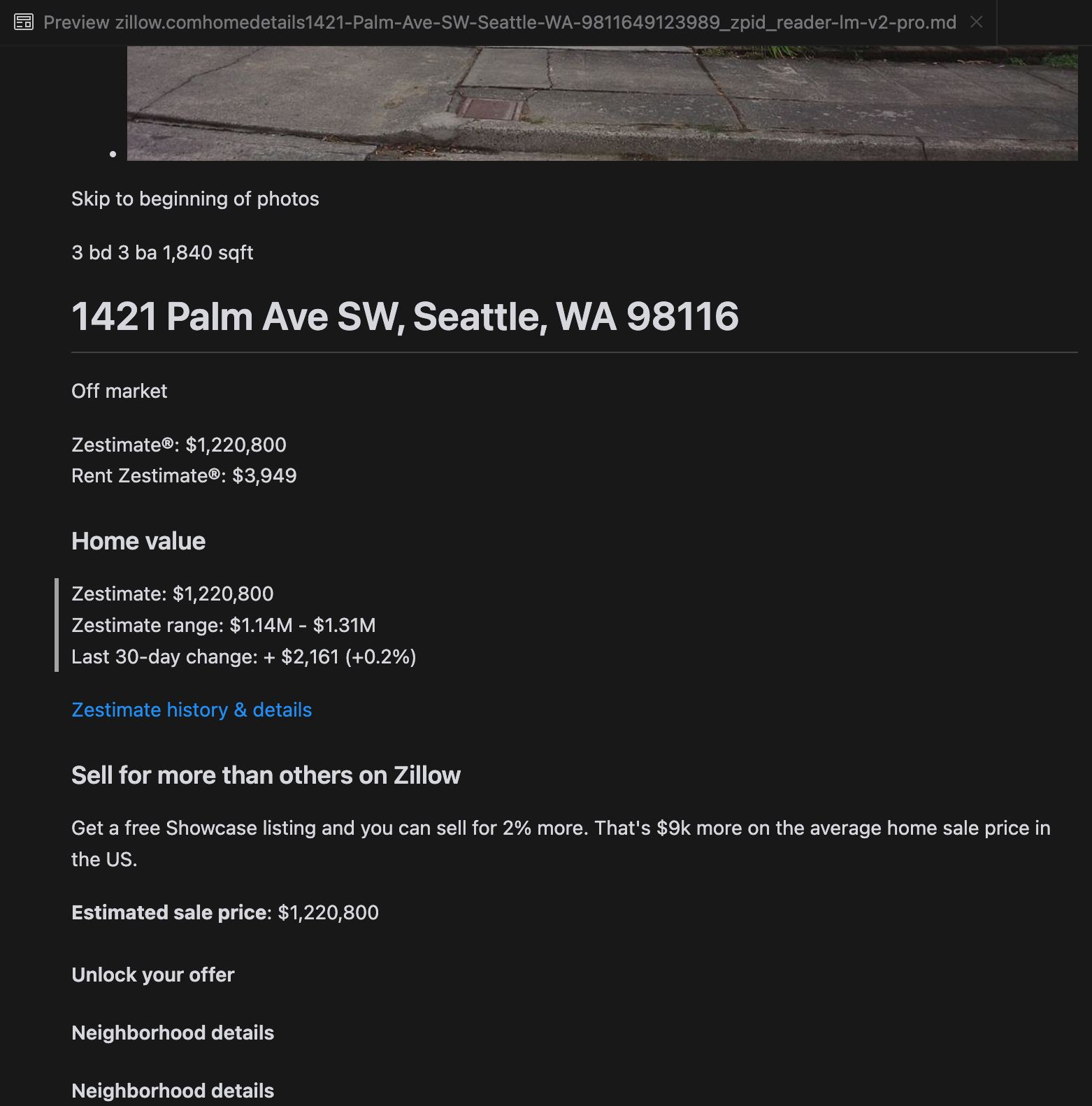
A comparison of the rendered Markdown outputs from gpt-4o (left), ReaderLM-v2 (middle), and ReaderLM-v2-pro (right).
For challenging content types like product landing pages and government documents, ReaderLM-v2 and ReaderLM-v2-pro maintained robust performance, though there's still room for improvement. When compared to our latest Reader API (a collection of heuristics, rules, and regex patterns that we've continuously patched and upgraded since last April), we observed that the gap between LM-based and rule-based approaches has narrowed significantly since the previous version (keep in mind that Reader API also evolves over time), particularly in terms of format and structural accuracy. However, based on our limited manual evaluation of ten HTML pages, our Reader API still remains the best option for HTML to markdown conversion.

How We Trained ReaderLM v2
ReaderLM-v2 is built on Qwen2.5-1.5B-Instruction, a compact base model known for its efficiency in instruction-following and long-context tasks. In this section, we describe how we trained the ReaderLM-v2, focusing on data preparation, training methods, and the challenges we encountered.
| Model Parameter | ReaderLM-v2 |
|---|---|
| Total Parameters | 1.54B |
| Max Context Length (Input+Output) | 512K |
| Hidden Size | 1536 |
| Number of Layers | 28 |
| Query Heads | 12 |
| KV Heads | 2 |
| Head Size | 128 |
| Intermediate Size | 8960 |
| Multilingual Support | 29 languages |
| HuggingFace Repository | Link |
Data Preparation
The success of ReaderLM-v2 largely depended on the quality of its training data. We created html-markdown-1m dataset, which included one million HTML documents collected from the internet. On average, each document contained 56,000 tokens, reflecting the length and complexity of real-world web data. To prepare this dataset, we cleaned the HTML files by removing unnecessary elements such as JavaScript and CSS, while preserving key structural and semantic elements. After cleaning, we used Jina Reader to convert HTML files to Markdown using regex patterns and heuristics.
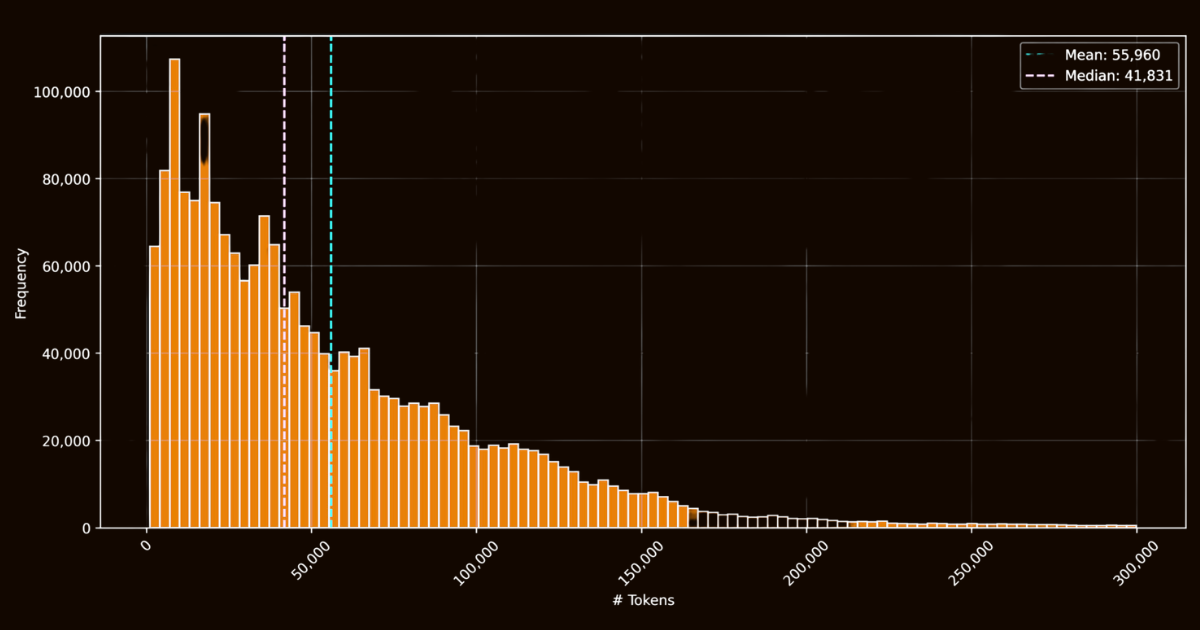
html-markdown-1m datasetWhile this created a functional baseline dataset, it highlighted a critical limitation: models trained solely on these direct conversions would essentially just learn to mimic the regex patterns and heuristics used by Jina Reader. This became evident with reader-lm-0.5b/1.5b, whose performance ceiling was constrained by the quality of these rule-based conversions.
To address these limitations, we developed a three-step pipeline relied on the Qwen2.5-32B-Instruction model, which is essential for creating a high quality synthetic dataset.

Qwen2.5-32B-Instruction- Drafting: We generated initial Markdown and JSON outputs based on instructions provided to the model. These outputs, while diverse, were often noisy or inconsistent.
- Refinement: The generated drafts were improved by removing redundant content, enforcing structural consistency, and aligning with desired formats. This step ensured the data was clean and aligned with task requirements.
- Critique: Refined outputs were evaluated against original instructions. Only data that passed this evaluation was included in the final dataset. This iterative approach ensured that the training data met the necessary quality standards for structured data extraction.
Training Process
Our training process involved multiple stages tailored to the challenges of processing long-context documents.
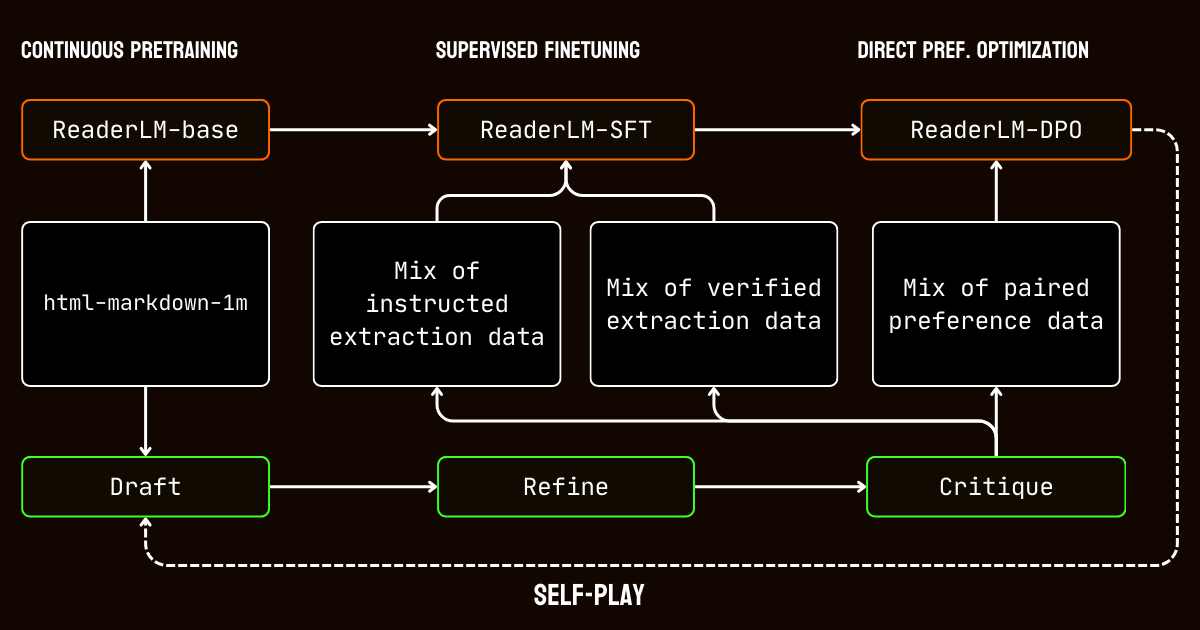
We began with long-context pretraining, using the html-markdown-1m dataset. Techniques like ring-zag attention and rotary positional encoding (RoPE) were used to progressively expand the model’s context length from 32,768 tokens to 256,000 tokens. To maintain stability and efficiency, we adopted a gradual training approach, starting with shorter sequences and incrementally increasing the context length.
Following pretraining, we moved to supervised fine-tuning (SFT). This stage utilized the refined datasets generated in the data preparation process. These datasets included detailed instructions for Markdown and JSON extraction tasks, along with examples for refining drafts. Each dataset was carefully designed to help the model learn specific tasks, such as identifying main content or adhering to schema-based JSON structures.
We then applied direct preference optimization (DPO) to align the model’s outputs with high-quality results. In this phase, the model was trained on pairs of draft and refined responses. By learning to prioritize the refined outputs, the model internalized the subtle distinctions that define polished and task-specific results.
Finally, we implemented self-play reinforcement tuning, an iterative process where the model generated, refined, and evaluated its own outputs. This cycle allowed the model to improve continuously without requiring additional external supervision. By leveraging its own critiques and refinements, the model gradually enhanced its ability to produce accurate and structured outputs.
Conclusion
Back in April 2024, Jina Reader became the first LLM-friendly markdown API. It set a new trend, earned widespread community adoption, and most importantly, inspired us to build small language models for data cleaning and extraction. Today, we're raising the bar again with ReaderLM-v2, delivering on the promises we made last September: better long-context handling, support for input instructions, and the ability to extract specific webpage content into markdown format. Once again, we've demonstrated that with careful training and quality data, small language models can achieve state-of-the-art performance that surpasses larger models.
Throughout the training process of ReaderLM-v2, we identified two insights. One effective strategy was training specialized models on separate datasets tailored to specific tasks. These task-specific models were later merged using linear parameter interpolation. While this approach required additional effort, it helped preserve the unique strengths of each specialized model in the final unified system.
The iterative data synthesis process proved crucial to our model's success. Through repeated refinement and evaluation of synthetic data, we significantly enhanced model performance beyond simple rule-based approaches. This iterative strategy, while presenting challenges in maintaining consistent critique evaluations and managing computational costs, was essential for transcending the limitations of using regex and heuristics-based training data from Jina Reader. This is clearly demonstrated by the performance gap between reader-lm-1.5b, which relies heavily on Jina Reader's rule-based conversions, and ReaderLM-v2 that benefit from this iterative refinement process.
One of the reasons we seem so obsessed with ReaderLM is our vision of a "single-file future." We believe that with the development of LLMs, many functions like memory, reasoning, storing, and searching will take place inside the context window, which is essentially one large file. Think of LLMs as your favorite text editor—like pico or nano—where you can perform all editing, find/replace operations, and versioning once you load a file. The directory/folder structure that we've grown accustomed to over the past 30 years of computer use may be dismantled. Many of these manually created structures that were designed to be human-friendly will be flattened into a single LLM-friendly file, much like what we've done with our API documentation.
Looking ahead, we plan to expand ReaderLM to include multimodal capabilities, particularly for handling scanned documents, while also optimizing generation speed. We're eager to hear your feedback on how ReaderLM-v2 enhances your data quality. If you're interested in a custom version of ReaderLM tailored to your specific domain, please don't hesitate to contact us.