Search PDFs with AI and Python: Part 2
In our previous post we looked at how (and how not) to break down PDF files into usable chunks so we could build a search engine for them. In this article, we continue our journey.


In our previous post we looked at how (and how not) to break down PDF files into usable chunks so we could build a search engine for them.

We also looked at a few footguns you may encounter along the way.

Now we’re going to take those chunks and:
- Encode them into vector embeddings using the CLIP model.
- Store them in an index for easy searching.
Encoding our chunks
By encoding our chunks we convert them into something our model (in this case CLIP) can understand. While many models are uni-modal (i.e. only work with one type of data, like text or image or audio), CLIP is multi-modal, meaning it can embed different data types into the same vector space.
This means we can search image-to-image, text-to-image, image-to-text or text-to-text. Or you could throw audio into there too. I’d rather not right now since:
- Typing all those option combinations takes way too long.
- The PDFs we’re using (thankfully) don’t contain audio (though I’m sure the PDF spec contains some functionality for that because PDF doesn’t just throw in the kitchen sink but also the machine that builds the kitchen sink).
Of course, if you only plan to search one type of modality (text or images), Jina AI Executor Hub has specific models just for those:
Adding the encoder Executor
Previously we built a Flow to:
- Extract text chunks and images.
- Break down our text chunks into sentences.
- Move all text chunks to the same level so things are nice and tidy.
- Normalize our images ready for encoding.
Our code looked something like this (including loading PDFs into DocumentArray, etc):
from docarray import DocumentArray
from executors import ChunkSentencizer, ChunkMerger, ImageNormalizer
from jina import Flow
docs = DocumentArray.from_files("data/*.pdf", recursive=True)
flow = (
Flow()
.add(uses="jinahub+sandbox://PDFSegmenter", install_requirements=True, name="segmenter")
.add(uses=ChunkSentencizer, name="chunk_sentencizer")
.add(uses=ChunkMerger, name="chunk_merger")
.add(uses=ImageNormalizer, name="image_normalizer")
)
with flow:
indexed_docs = flow.index(docs)Now we just need to add our CLIPEncoder. Again, we can add this Executor straight from Jina Hub, without having to worry about how to integrate the model manually. Let’s do it in a sandbox so we don’t have to worry about using our own compute:
from docarray import DocumentArray
from executors import ChunkSentencizer, ChunkMerger, ImageNormalizer
from jina import Flow
docs = DocumentArray.from_files("data/*.pdf", recursive=True)
flow = (
Flow()
.add(uses="jinahub+sandbox://PDFSegmenter", name="segmenter")
.add(uses=ChunkSentencizer, name="chunk_sentencizer")
.add(uses=ChunkMerger, name="chunk_merger")
.add(uses=ImageNormalizer, name="image_normalizer")
.add(uses="jinahub+sandbox://CLIPEncoder", name="encoder")
)
with flow:
indexed_docs = flow.index(docs)So far, so good. Let’s run the Flow, and see some summary info about:
- Our top-level Document.
- Each chunk-level of our top-level Document (i.e. the images and sentences).
with flow:
indexed_docs = flow.index(docs, show_progress=True)
# See summary of indexed Documents
indexed_docs.sumamry()
# See summary of all the chunks of indexed Documents
indexed_docs[0].chunks.summary()But if we run this code it’s going to choke:
- Errors like
encoder/rep-0@113300[E]:UnidentifiedImageError(‘cannot identify image file <_io.BytesIO object at 0x7fdc143e9810>’) - No mention of any
embeddingin our summaries.
So something somewhere failed.
Why? Because by default, Jina indexes on the Document level, not the chunk level. In our case, the top level PDF is largely meaningless — it’s the chunks (images and sentences) we want to work with. But even worse than that, CLIP is trying to read our PDF as an image (since that’s its default assumption) and choking on it!

So let’s add a traversal_path so we can search within our nested structure and ignore that big old scary PDF:
flow = (
Flow()
.add(uses="jinahub+sandbox://PDFSegmenter", name="segmenter")
.add(uses=ChunkSentencizer, name="chunk_sentencizer")
.add(uses=ChunkMerger, name="chunk_merger")
.add(uses=ImageNormalizer, name="image_normalizer")
.add(
uses="jinahub+sandbox://CLIPEncoder",
name="encoder",
uses_with={"traversal_paths": "@c"},
)
)With a traversal_path of "@c" we’re traversing the first level of chunks in the Document. The syntax for which level of chunks to traverse is quite straightforward:
"@c": Traverse first level of chunks"@cc": Traverse second level chunks (third level is"@ccc"and so on…)"@c, cc": Traverse first and second level chunks[...]: Traverse all chunks
This could come in handy if we wanted to segment, say, Animal Farm, because we could go by:
- Top-level
Document:animal_farm.pdf. "@c": chapter-level chunks."@cc": paragraph-level chunks."@ccc": sentence-level chunks."@cccc": word-level chunks."@ccccc": letter-level chunks (though why you’d want to do this is anyone’s guess).[...]: all of the above chunk-levels
Then we could choose what levels of input/output to give it (e.g. input a sentence, get matching paragraphs).
(Just to be clear, I’m an uncultured swine who hasn’t actually read Animal Farm. I assume it’s got chapters, paragraphs, etc, about lovely fluffy farm animals and is a charming book for children).

Since we only have one level of chunks in our processed PDFs (i.e. sentences or images), we can stick with "@c" .
Now we can once again run our Flow and check our output with:
with flow:
indexed_docs = flow.index(docs, show_progress=True)
# See summary of indexed Documents
indexed_docs.sumamry()
# See summary of all the chunks of indexed Documents
indexed_docs[0].chunks.summary()For our top-level Document:
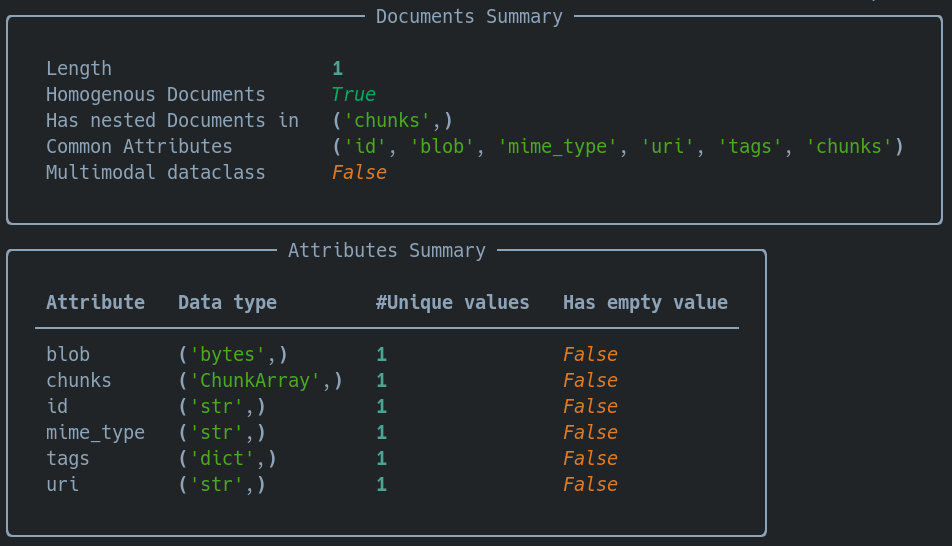
And now our chunks:
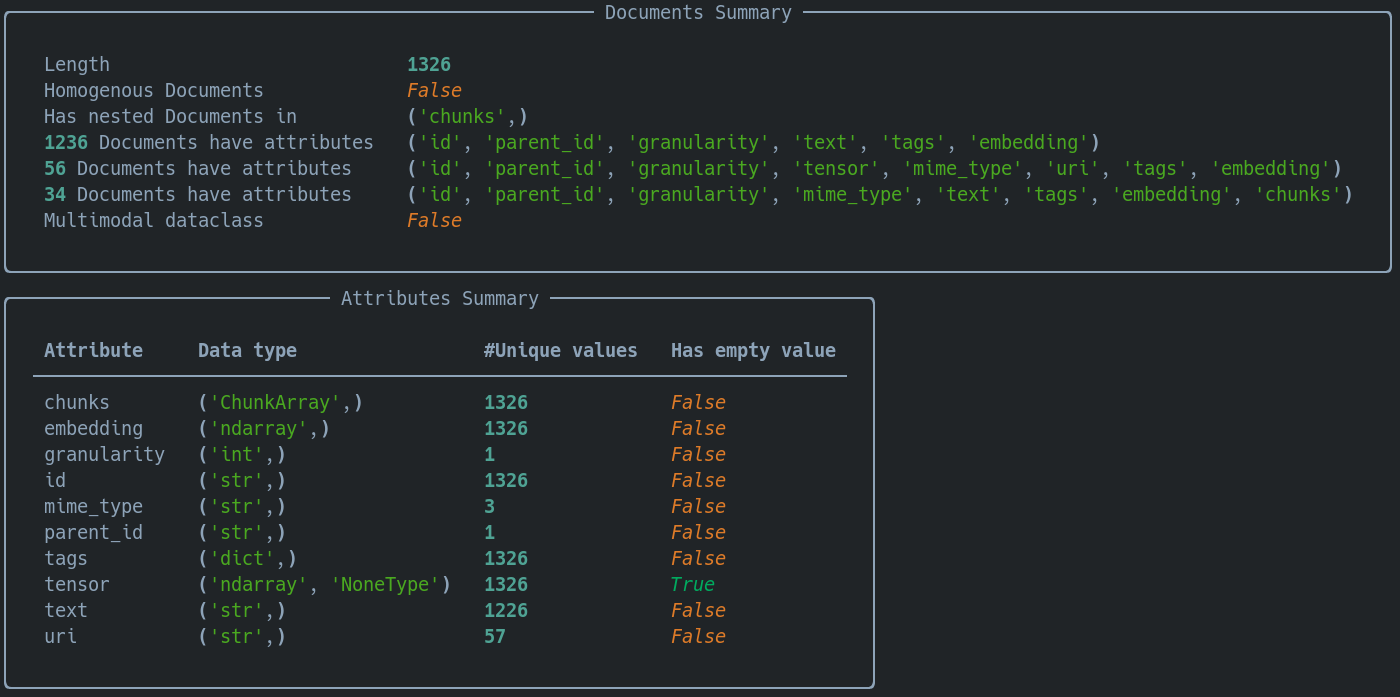
Looks like we encoded those chunks successfully!
Storing our chunks in an index
If we don’t store our chunks and embeddings in an index, they’ll just disappear into the ether when our program exits. All that effort will have been for nothing:

In our case we’ll use SimpleIndexer since we’re just building out the basics. For a real-world use case we might use a Weaviate or Qdrant backend, or a more powerful indexer (like PQLiteIndexer) from Jina Hub.
Let’s add SimpleIndexer to our Flow. But first of all, one thing to note: we still need to bear our chunk-level in mind, so we’ll add a traversal_right parameter:
flow = (
Flow()
.add(uses="jinahub+sandbox://PDFSegmenter", name="segmenter")
.add(uses=ChunkSentencizer, name="chunk_sentencizer")
.add(uses=ChunkMerger, name="chunk_merger")
.add(uses=ImageNormalizer, name="image_normalizer")
.add(
uses="jinahub+sandbox://CLIPEncoder",
name="encoder",
uses_with={"traversal_paths": "@c"},
)
.add(
uses="jinahub://SimpleIndexer",
install_requirements=True,
name="indexer",
uses_with={"traversal_right": "@c"},
)
)Now when we run our Flow we’ll see a workspace folder on our disk. If we run tree workspace we can see the structure:
workspace
└── SimpleIndexer
└── 0
└── index.db
2 directories, 1 fileAnd if we run file workspace/SimpleIndexer/0/index.db we can see that that’s just a SQLite file:
workspace/SimpleIndexer/0/index.db: SQLite 3.x database, last written using SQLite version 3038002, file counter 11, database pages 25110, cookie 0x2, schema 4, UTF-8, version-valid-for 11Cool. That means it’s just using the DocArray SQLite Document Store. So if we needed to we could write a few lines of code to load it direct from disk in future (and I mean future — we’re not getting sidetracked in this blog post, except for memes).
Next time
We’ll leave searching through our data for our next post. Because:
- This post is already getting long.
- I still need to work out how best to skip several Executors when dealing with queries as input. Or use different Flows with one endpoint. Or something.
The latter point is important, because right now our Flow assumes our input is a PDF file and tries to break that down. If I send a text string to that same Flow it’s going to have difficulties:

The precise difficulty being:
indexer/rep-0@124659[E]:ValueError('Empty ndarray. Did you forget to set .embedding/.tensor value and now you are operating on it?')
Because it’s expecting a PDF file. It doesn’t get that, so it just passes…nothingness down the Flow I guess. And since it’s nothing, there’s no embedding to work with.
Join me next time as I try to make something out of nothing. This will either mean:
- I single-handedly reverse entropy and nudge the universe towards a golden age.
- I start getting headaches from working with multiple Flows or weird switching.
Either way, fun to watch! In a schadenfreude way at least.
If you want to lend a hand (or a shoulder to cry on), or just talk with us about PDF search engines, join our community Slack and get chatting!