Still Need Chunking When Long-Context Models Can Do It All?
Comparing how long-context embedding models perform with different chunking strategies to find the optimal approach for your needs.


In October 2023, we introduced jina-embeddings-v2, the first open-source embedding model family capable of handling inputs up to 8,192 tokens. Building on this, this year we launched jina-embeddings-v3, offering the same extensive input support with further enhancements.

In this post we’ll dig into long context embeddings and answer some questions: When is it practical to consolidate such a large volume of text into a single vector? Does segmentation enhance retrieval, and if so, how? How can we preserve context from different parts of a document while segmenting the text?
To answer these questions, we’ll compare several methods for generating embeddings:
- Long context embedding (encoding up to 8,192 tokens in a document) vs short context (i.e. truncating at 192 tokens).
- No chunking vs. naive chunking vs. late chunking.
- Different chunk sizes with both naive and late chunking.
Is Long Context Even Useful?
With the ability to encode up to ten pages of text in a single embedding, long context embedding models open up possibilities for large-scale text representation. Is that even useful though? According to a lot of people…no.




Sources: Quote from Nils Reimer in How AI Is Built podcast, brainlag tweet, egorfine Hacker News comment, andy99 Hacker News comment
We’re going to address all of these concerns with a detailed investigation of long-context capabilities, when long context is helpful, and when you should (and shouldn’t) use it. But first, let’s hear those skeptics out and look at some of the issues long-context embedding models face.
Problems with Long-Context Embeddings
Imagine we’re building a document search system for articles, like those on our Jina AI blog. Sometimes a single article may cover multiple topics, like the report about our visit to the ICML 2024 conference, which contains:
- An introduction, capturing general information about ICML (number of participants, location, scope, etc).
- The presentation of our work (
jina-clip-v1). - Summaries of other interesting research papers presented at ICML.
If we create just a single embedding for this article, that one embedding represents a mixture of three disparate topics:
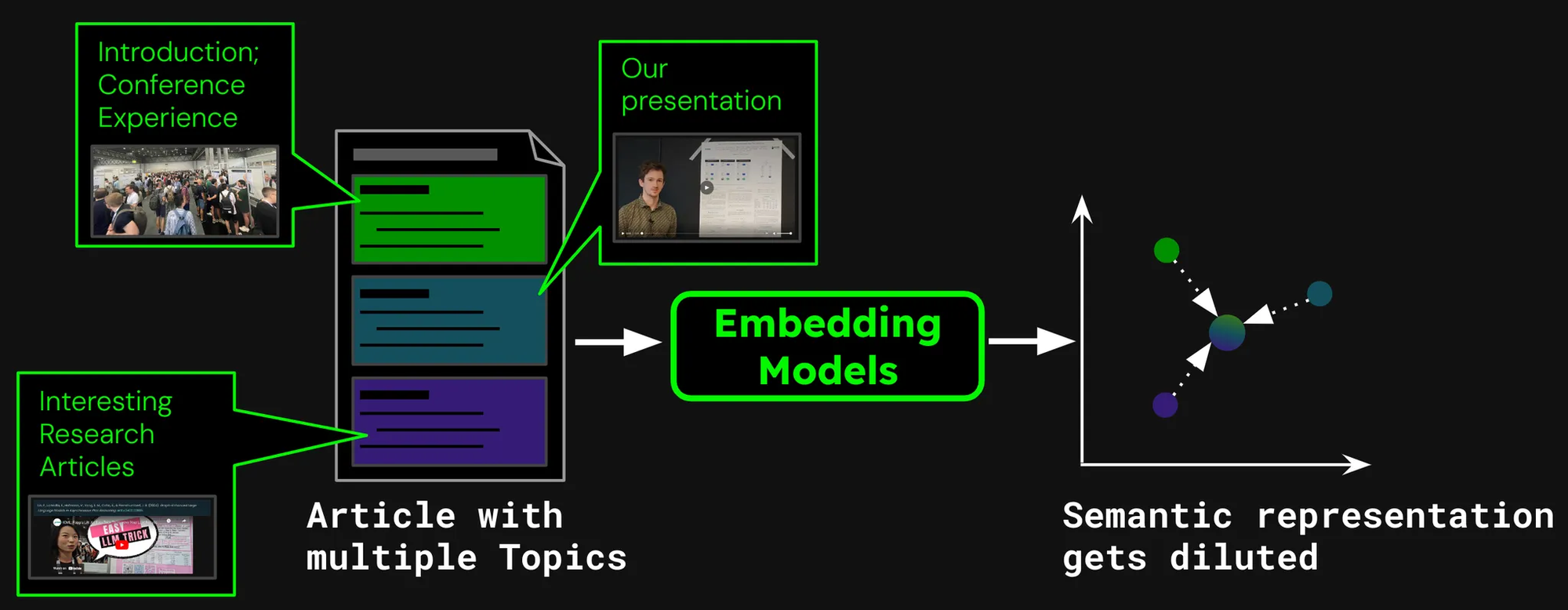
This leads to several problems:
- Representation Dilution: While all topics in a given text could be related, only one may be relevant to a user’s search query. However, a single embedding (in this case, that of the whole blog post) is just one point in the vector space. As more text is added to the model’s input, the embedding shifts to capture the overall topic of the article, making it less effective in representing content covered in specific paragraphs.
- Limited Capacity: Embedding models produce vectors of a fixed size, independent of input length. As more content is added to the input, it gets harder for the model to represent all this information in the vector. Think of it like scaling an image down to 16×16 pixels — If you scale an image of something simple, like an apple, you can still derive meaning from the scaled image. Scaling down a street map of Berlin? Not so much.
- Information Loss: In some cases, even long-context embedding models hit their limits; Many models support text encoding with up to 8,192 tokens. Longer documents need to be truncated before embedding, leading to information loss. If the information relevant to the user is located at the end of the document, it won’t be captured by the embedding at all.
- You May Need Text Segmentation: Some applications require embeddings for specific segments of the text but not for the entire document, like identifying the relevant passage in a text.
Long Context vs. Truncation
To see whether long context is worthwhile at all, let’s look at the performance of two retrieval scenarios:
- Encoding documents up to 8,192 tokens (about 10 pages of text).
- Truncating documents at 192 tokens and encoding up to there.
We’ll compare results using jina-embeddings-v3 with the nDCG@10 retrieval metric. We tested the following datasets:
| Dataset | Description | Query Example | Document Example | Mean Document Length (characters) |
|---|---|---|---|---|
| NFCorpus | A full-text medical retrieval dataset with 3,244 queries and documents mostly from PubMed. | "Using Diet to Treat Asthma and Eczema" | "Statin Use and Breast Cancer Survival: A Nationwide Cohort Study from Finland Recent studies have suggested that [...]" | 326,753 |
| QMSum | A query-based meeting summarization dataset requiring summarization of relevant meeting segments. | "The professor was the one to raise the issue and suggested that a knowledge engineering trick [...]" | "Project Manager: Is that alright now ? {vocalsound} Okay . Sorry ? Okay , everybody all set to start the meeting ? [...]" | 37,445 |
| NarrativeQA | QA dataset featuring long stories and corresponding questions about specific content. | "What kind of business Sophia owned in Paris?" | "The Project Gutenberg EBook of The Old Wives' Tale, by Arnold Bennett\n\nThis eBook is for the use of anyone anywhere [...]" | 53,336 |
| 2WikiMultihopQA | A multi-hop QA dataset with up to 5 reasoning steps, designed with templates to avoid shortcuts. | "What is the award that the composer of song The Seeker (The Who Song) earned?" | "Passage 1:\nMargaret, Countess of Brienne\nMarguerite d'Enghien (born 1365 - d. after 1394), was the ruling suo jure [...]" | 30,854 |
| SummScreenFD | A screenplay summarization dataset with TV series transcripts and summaries requiring dispersed plot integration. | "Penny gets a new chair, which Sheldon enjoys until he finds out that she picked it up from [...]" | "[EXT. LAS VEGAS CITY (STOCK) - NIGHT]\n[EXT. ABERNATHY RESIDENCE - DRIVEWAY -- NIGHT]\n(The lamp post light over the [...]" | 1,613 |
As we can see, encoding more than 192 tokens can give notable performance improvements:
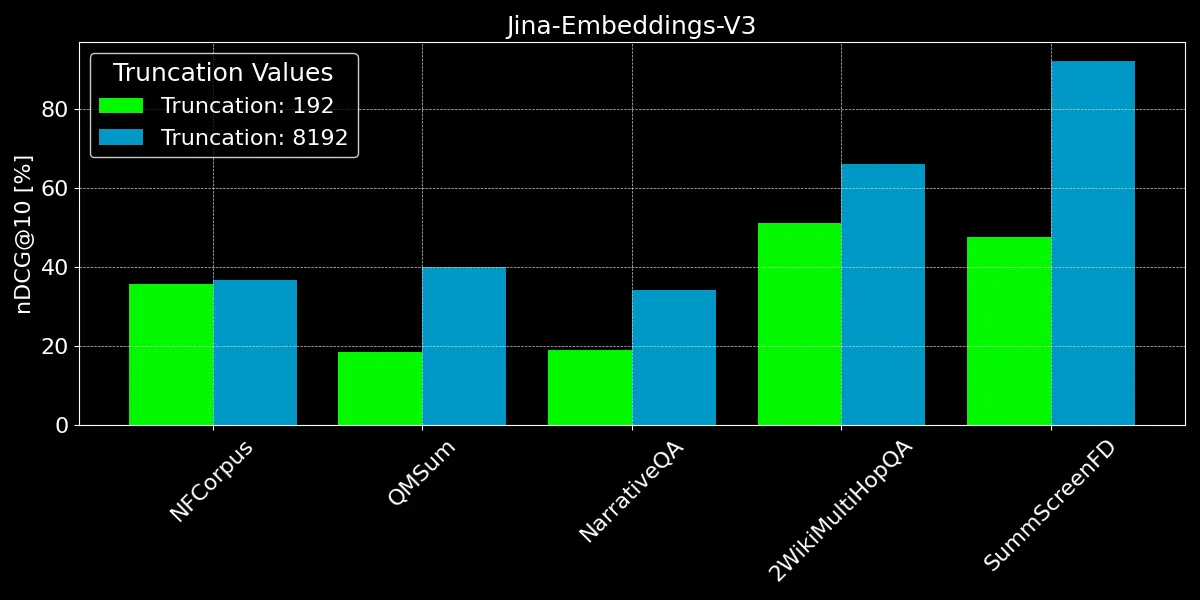
However, on some datasets, we see bigger improvements than on others:
- For NFCorpus, truncation barely makes a difference. This is because the titles and abstracts are right at the start of the documents, and these are highly relevant to typical user search terms. Whether truncated or not, the most pertinent data remains within the token limit.
- QMSum and NarrativeQA are considered "reading comprehension" tasks, where users typically search for specific facts within a text. These facts are often embedded in details scattered across the document, and may fall outside the truncated 192-token limit. For instance, in the NarrativeQA document Percival Keene, the question "Who is the bully that steals Percival's lunch?" is answered well beyond this limit. Similarly, in 2WikiMultiHopQA, relevant information is dispersed throughout entire documents, requiring models to navigate and synthesize knowledge from multiple sections to answer queries effectively.
- SummScreenFD is a task aimed at identifying the screenplay corresponding to a given summary. Because the summary encompasses information distributed across the screenplay, encoding more of the text improves the accuracy of matching the summary to the correct screenplay.
Segmenting Text for Better Retrieval Performance
• Segmentation: Detecting boundary cues in an input text, for example, sentences or a fixed number of tokens.
• Naive chunking: Breaking the text into chunks based on segmentation cues, prior to encoding it.
• Late chunking: Encoding the document first and then segmenting it (preserving context between chunks).
Instead of embedding an entire document into one vector, we can use various methods to first segment the document by assigning boundary cues:

Some common methods include:
- Segmenting by fixed size: The document is divided into segments of a fixed number of tokens, determined by the embedding model’s tokenizer. This ensures the tokenization of the segments corresponds to the tokenization of the entire document (segmenting by a specific number of characters could lead to a different tokenization).
- Segmenting by sentence: The document is segmented into sentences, and each chunk consists of n number of sentences.
- Segmenting by semantics: Each segment corresponds to multiple sentences and an embedding model determines the similarity of consecutive sentences. Sentences with high embedding similarities are assigned to the same chunk.
For simplicity, we use fixed-size segmentation in this article.
Document Retrieval Using Naive Chunking
Once we’ve performed fixed-size segmentation, we can naively chunk the document according to those segments:
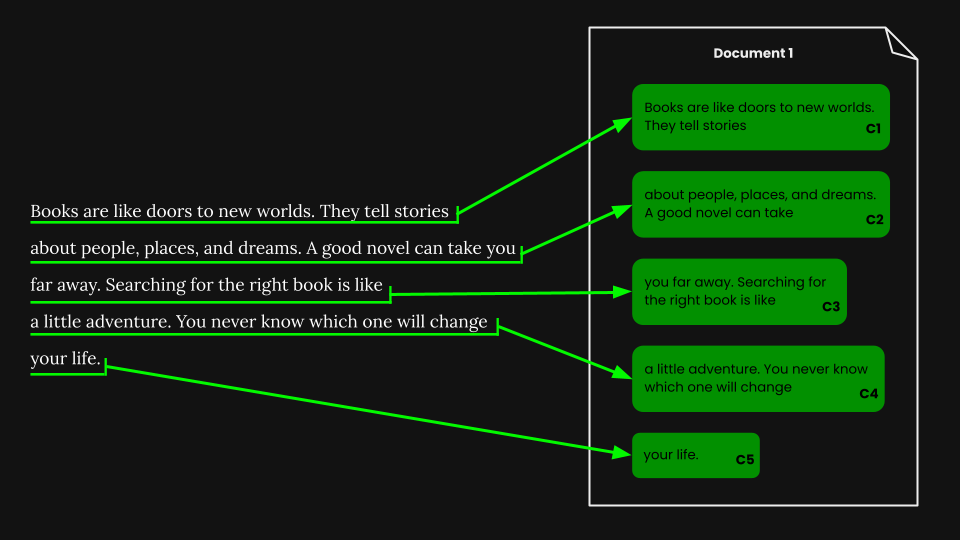
Using jina-embeddings-v3, we encode each chunk into an embedding that accurately captures its semantics, then store those embeddings in a vector database.
At runtime, the model encodes a user’s query to a query vector. We compare this against our vector database of chunk embeddings to find the chunk with the highest cosine similarity, and then return the corresponding document to the user:
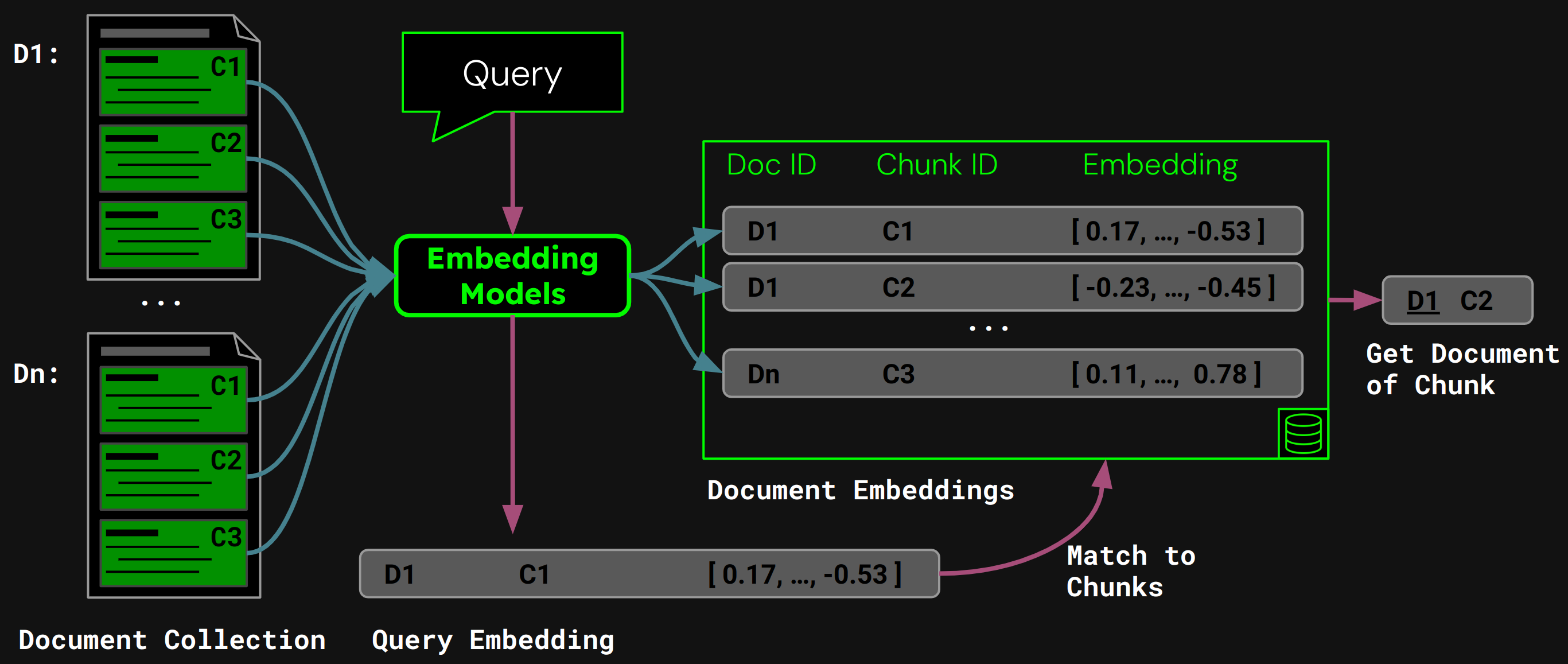
Problems with Naive Chunking

While naive chunking addresses some of the limitations of long-context embedding models, it also has its downsides:
- Missing the Bigger Picture: When it comes to document retrieval, multiple embeddings of smaller chunks may fail to capture the document’s overall topic. Think of not being able to see the forest for the trees.
- Missing Context Problem: Chunks can’t be interpreted accurately as context information is missing, as illustrated in Figure 6.
- Efficiency: More chunks require more storage and increase retrieval time.
Late Chunking Solves the Context Problem
Late chunking works in two main steps:
- First, it uses the model's long-context capabilities to encode the entire document into token embeddings. This preserves the full context of the document.
- Then, it creates chunk embeddings by applying mean pooling to specific sequences of token embeddings, corresponding to the boundary cues identified during segmentation.
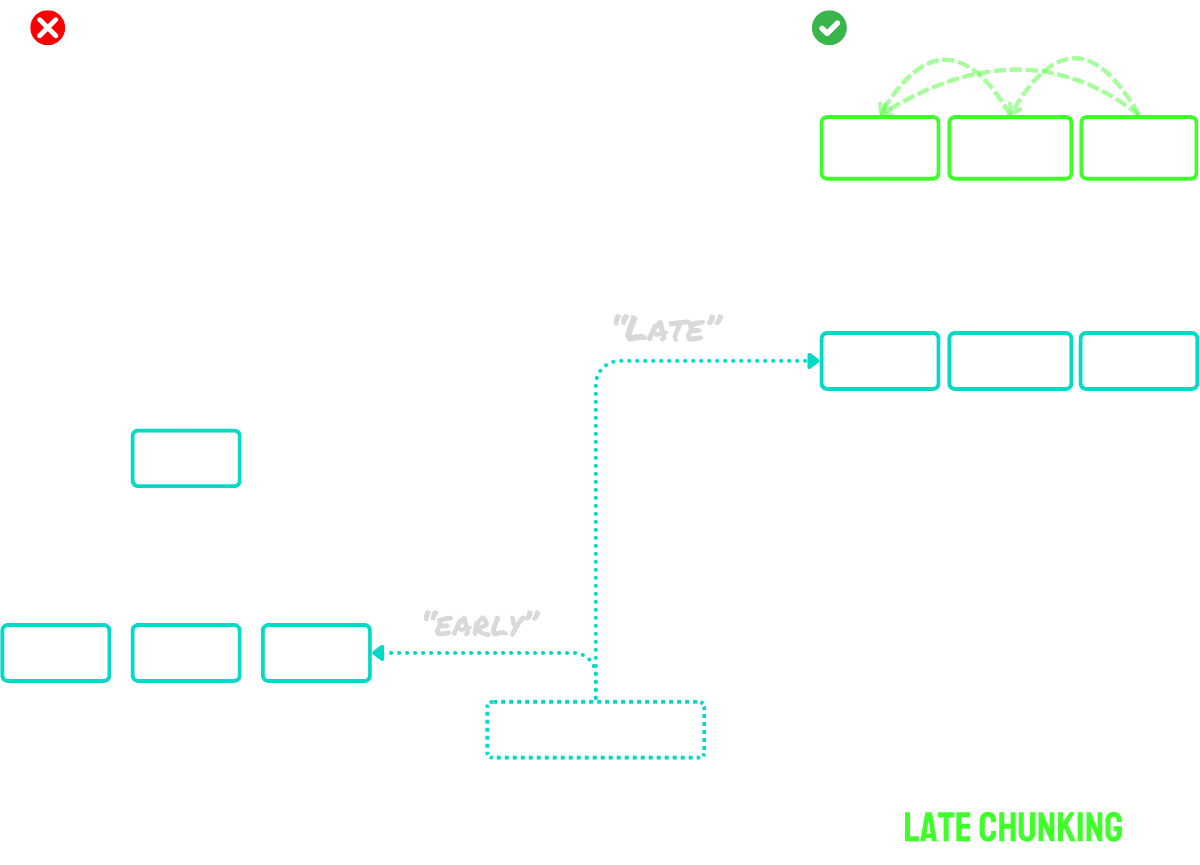
The key advantage of this approach is that the token embeddings are contextualized - meaning they naturally capture references and relationships to other parts of the document. Since the embedding process happens before chunking, each chunk retains awareness of the broader document context, solving the missing context problem that plagues naive chunking approaches.
For documents that exceed the model's maximum input size, we can use "long late chunking":
- First, we break the document into overlapping "macro-chunks." Each macro-chunk is sized to fit within the model's maximum context length (for example, 8,192 tokens).
- The model processes these macro-chunks to create token embeddings.
- Once we have the token embeddings, we proceed with standard late chunking - applying mean pooling to create the final chunk embeddings.
This approach allows us to handle documents of any length while still preserving the benefits of late chunking. Think of it as a two-stage process: first making the document digestible for the model, then applying the regular late chunking procedure.
In short:
- Naive chunking: Segment the document into small chunks, then encode each chunk separately.
- Late chunking: Encode the entire document at once to create token embeddings, then create chunk embeddings by pooling the token embeddings based on segment boundaries.
- Long late chunking: Split large documents into overlapping macro-chunks that fit the model's context window, encode these to get token embeddings, then apply late chunking as normal.
For a more extensive description of the idea, take a look at our paper or the blog posts mentioned above.
To Chunk or Not to Chunk?
We’ve already seen that long-context embedding generally outperforms shorter text embeddings, and given an overview of both naive and late chunking strategies. The question now is: Is chunking better than long-context embedding?
To conduct a fair comparison, we truncate text values to the maximum sequence length of the model (8,192 tokens) before starting to segment them. We use fixed-size segmentation with 64 tokens per segment (for both naive segmentation and late chunking). Let's compare three scenarios:
- No segmentation: We encode each text into a single embedding. This leads to the same scores as the previous experiment (see Figure 2), but we include them here to better compare them.
- Naive chunking: We segment the texts, then apply naive chunking based on the boundary cues.
- Late chunking: We segment the texts, then use late chunking to determine embeddings.
For both late chunking and naive segmentation, we use chunk retrieval to determine the relevant document (as shown in Figure 5, earlier in this post).
The results show no clear winner:
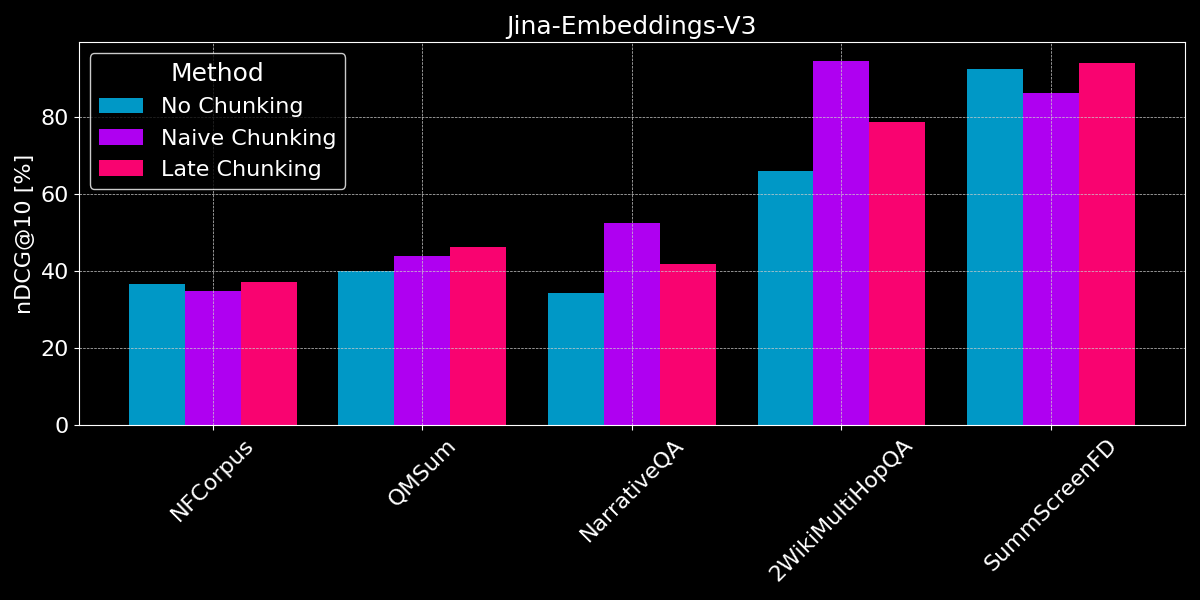
- For fact retrieval, naive chunking performs better: For the QMSum, NarrativeQA, and 2WikiMultiHopQA datasets, the model has to identify relevant passages in the document. Here, naive chunking is clearly better than encoding everything into a single embedding, as likely only a few chunks include relevant information, and said chunks capture it much better than a single embedding of the whole document.
- Late chunking works best with coherent documents and relevant context: For documents covering a coherent topic where users search for overall themes rather than specific facts (like in NFCorpus), late chunking slightly outperforms no chunking, as it balances document-wide context with local detail. However, while late chunking generally performs better than naive chunking by preserving context, this advantage can become a liability when searching for isolated facts within documents containing mostly irrelevant information - as seen in the performance regressions for NarrativeQA and 2WikiMultiHopQA, where the added context becomes more distracting than helpful.
Does Chunk Size Make a Difference?
The effectiveness of chunking methods really depends on the dataset, highlighting how content structure plays a crucial role:
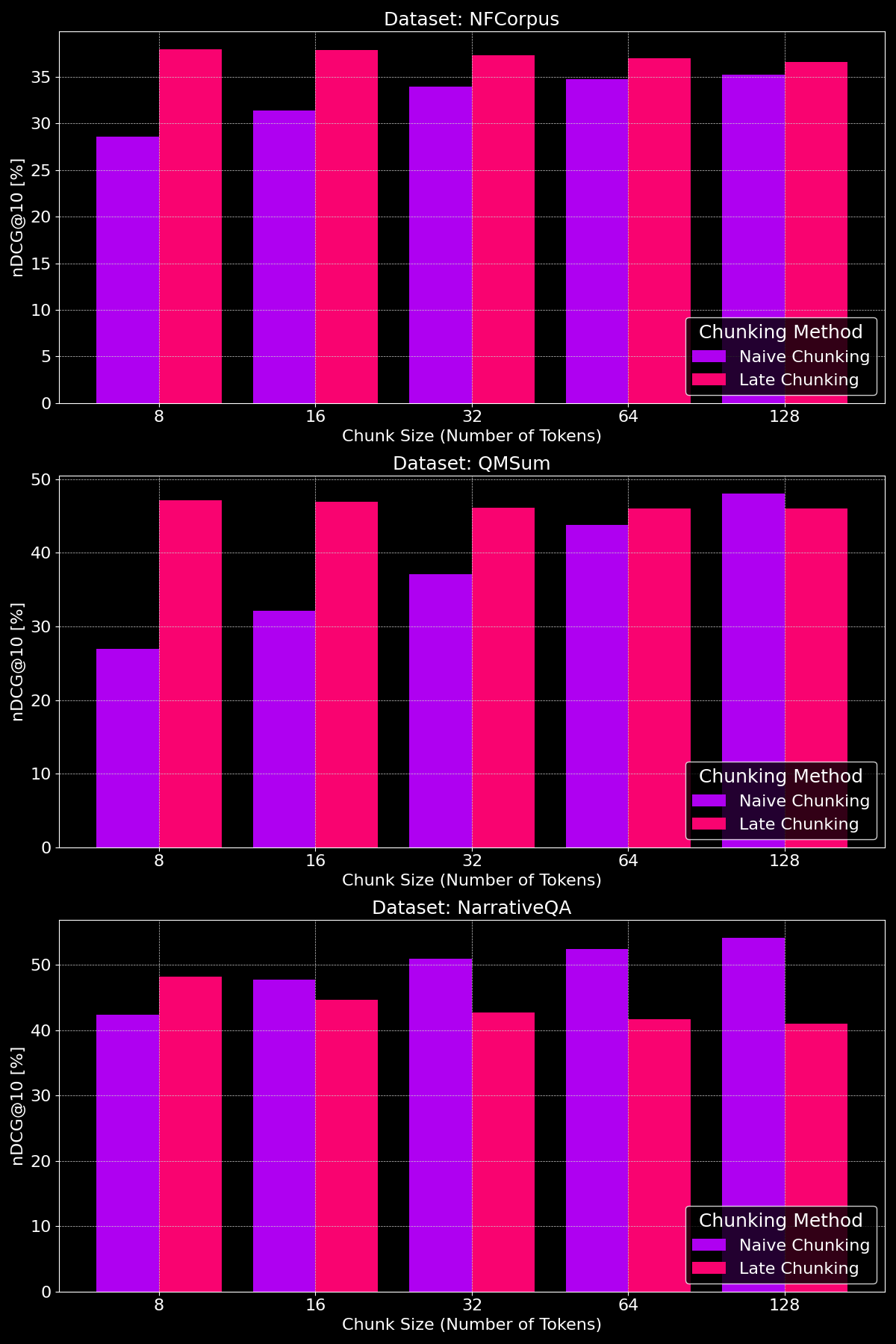
As we can see, late chunking generally beats naive chunking at smaller chunk sizes, since smaller naive chunks are too small to contain much context, while smaller late chunks retain the context of the entire document, making them more semantically meaningful. The exception to this is the NarrativeQA dataset where there is simply so much irrelevant context that late chunking falls behind. At larger chunk sizes, naive chunking shows marked improvement (occasionally beating late chunking) due to the increased context, while late chunking’s performance gradually decreases.
Takeaways: When To Use What?
In this post, we’ve looked at different types of document retrieval tasks to better understand when to use segmentation and when late chunking helps. So, what we have learned?
When Should I use Long-Context Embedding?
In general, it doesn’t harm retrieval accuracy to include as much text of your documents as you can to the input of your embedding model. However, long-context embedding models often focus on the beginning of documents, as they contain content like titles and introduction which are more important for judging relevance, but the models might miss content in the middle of the document.
When Should I use Naive Chunking?
When documents cover multiple aspects, or user queries target specific information within a document, chunking generally improves retrieval performance.
Eventually, segmentation decisions depend on factors like the need to display partial text to users (e.g. as Google presents the relevant passages in the previews of the search results), which makes segmentation essential, or constraints on compute and memory, where segmentation may be less favorable due to increased retrieval overhead and resource usage.
When Should I use Late Chunking?
By encoding the full document before creating chunks, late chunking solves the problem of text segments losing their meaning due to missing context. This works particularly well with coherent documents, where each part relates to the whole. Our experiments show that late chunking is especially effective when dividing text into smaller chunks, as demonstrated in our paper. However, there's one caveat: if parts of the document are unrelated to each other, including this broader context can actually make retrieval performance worse, as it adds noise to the embeddings.
Conclusion
The choice between long-context embedding, naive chunking, and late chunking depends on the specific requirements of your retrieval task. Long-context embeddings are valuable for coherent documents with general queries, while chunking excels in cases where users seek specific facts or information within a document. Late chunking further enhances retrieval by retaining contextual coherence within smaller segments. Ultimately, understanding your data and retrieval goals will guide the optimal approach, balancing accuracy, efficiency, and contextual relevance.
If you're exploring these strategies, consider trying out jina-embeddings-v3—its advanced long-context capabilities, late chunking, and flexibility make it an excellent choice for diverse retrieval scenarios.
