Time-Slicing GPUs with Karpenter


Today, businesses and developers are keen to use cloud for deep learning. Especially with the GPU cloud instances, you pay as you go. It is much more cost-efficient comparing to having an expensive metal machine in the office.
But let's switch the role now. Say you are the GPU cloud provider, and you provide the GPU environment for hosting other users applications. The problem now becomes, how can you, as this platform provider, lower down the GPU costs to maximize the profit?
This is not about finding the cheapest GPU vendors. In fact, it is the question we were facing at Jina AI when designing our GPU cloud platform.


The answer is time-slicing.
In this article, we will use Karpenter - an elastic node scaling method in Kubernetes and NVIDIA’s k8s plugin to achieve time-slicing on GPUs. A GPU cloud with time-slicing will allow users to share GPUs between pods, hence saves the costs.


 NVIDIA
NVIDIAKarpenter itself provides an auto scaling feature to nodes, which means that you will have the GPU instance only when you need it and can schedule the node based on the instance type you configured. It saves you money and schedules nodes more effectively.
The purpose of utilizing the GPU with Karpenter is not only saving cost, but more importantly, it also provides us a flexible method to schedule GPU resources to our applications within the kubernetes cluster. You may own tens of applications which need the GPU in different time slots, how to schedule them in a more cost effective way is so important in the cloud.
Architecture
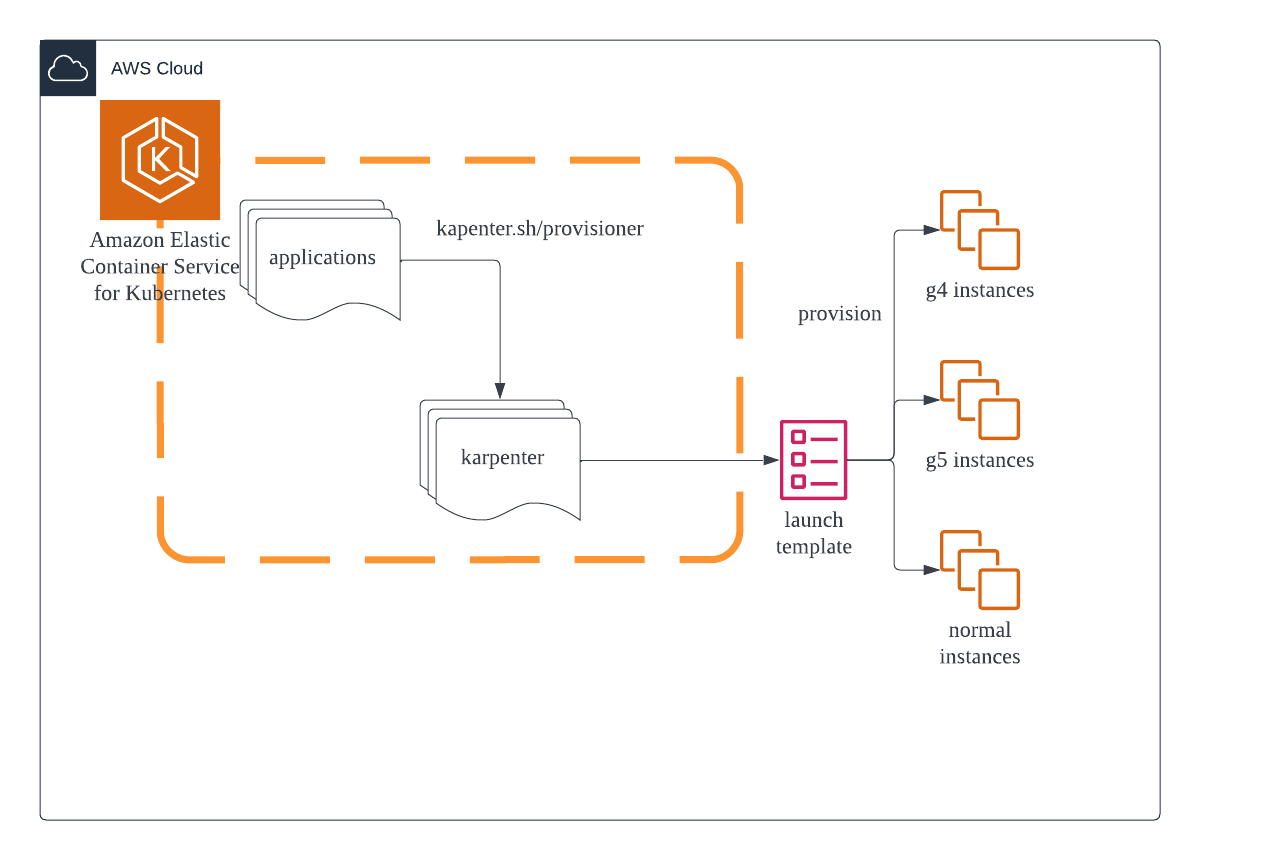
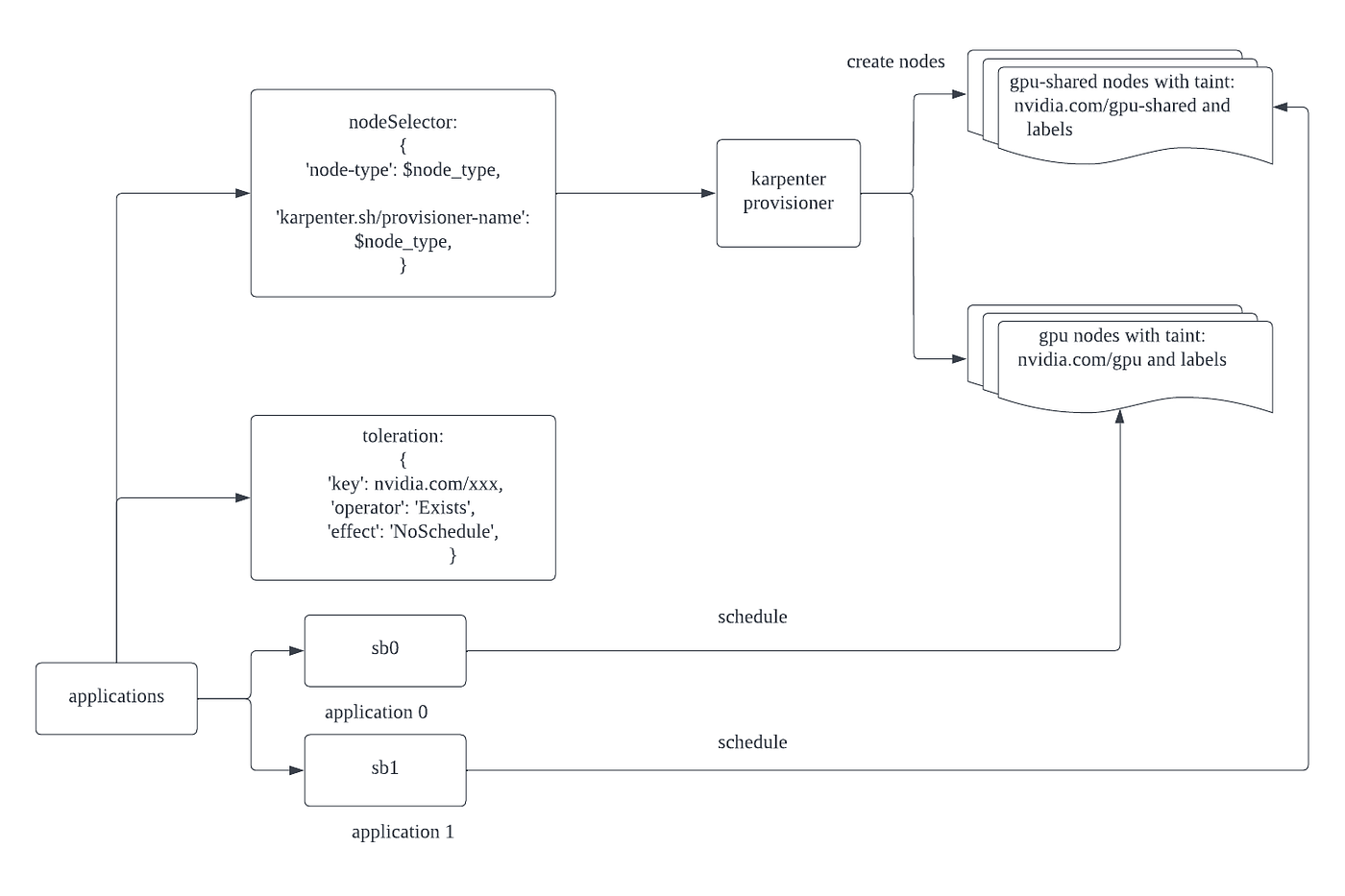
It’s pretty straightforward: the application will choose a karpenter provisioner with a selector. The karpenter provisioner will create nodes based on the launch template in that provisioner.
Deployment
Building the architect is simple, the problem we are left with is how we are going to deploy it. There are some particulars we need to think about.
- How we deploy the nvidia k8s plugin to the nodes with GPU only.
- How we configure the shared GPU nodes to use time-slicing without affecting others.
- How do we automatically update nodes AMI in the launch template so the nodes can use the latest image.
- How do we setup karpenter provisioners
Let’s do it one by one then.
First, install karpenter and setup provisioner with terraform. You can manually install karpenter in eks with an official document as well. If you already have eks with karpenter, you can skip it.
tarrantroSet provisioner
The Provisioners is set to use corelated launch templates to provision GPU nodes with labels and taints.
resource "kubectl_manifest" "karpenter_provisioner_gpu_shared" {
yaml_body = <<-YAML
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: gpu-shared
spec:
ttlSecondsAfterEmpty: 300
labels:
jina.ai/node-type: gpu-shared
jina.ai/gpu-type: nvidia
nvidia.com/device-plugin.config: shared_gpu
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values: ["g4dn.xlarge", "g4dn.2xlarge", "g4dn.4xlarge", "g4dn.12xlarge"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
taints:
- key: nvidia.com/gpu-shared
effect: "NoSchedule"
limits:
resources:
cpu: 1000
provider:
launchTemplate: "karpenter-gpu-shared-${local.cluster_name}"
subnetSelector:
karpenter.sh/discovery: ${local.cluster_name}
tags:
karpenter.sh/discovery: ${local.cluster_name}
ttlSecondsAfterEmpty: 30
YAML
depends_on = [
helm_release.karpenter
]
}
resource "kubectl_manifest" "karpenter_provisioner_gpu" {
yaml_body = <<-YAML
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: gpu
spec:
ttlSecondsAfterEmpty: 300
labels:
jina.ai/node-type: gpu
jina.ai/gpu-type: nvidia
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values: ["g4dn.xlarge", "g4dn.2xlarge", "g4dn.4xlarge", "g4dn.12xlarge"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
- key: kubernetes.io/arch
operator: In
values: ["amd64"]
taints:
- key: nvidia.com/gpu
effect: "NoSchedule"
limits:
resources:
cpu: 1000
provider:
launchTemplate: "karpenter-gpu-${local.cluster_name}"
subnetSelector:
karpenter.sh/discovery: ${local.cluster_name}
tags:
karpenter.sh/discovery: ${local.cluster_name}
ttlSecondsAfterEmpty: 30
YAML
depends_on = [
helm_release.karpenter
]
} 262588213843476
262588213843476
Add time-slicing config
Secondly, we need to deploy the NVIDIA k8s plugin with time-slicing config and default config and set up a node selector so the daemonset will only run on the GPU instances.
config:
# ConfigMap name if pulling from an external ConfigMap
name: ""
# Set of named configs to build an integrated ConfigMap from
map:
default: |-
version: v1
flags:
migStrategy: "none"
failOnInitError: true
nvidiaDriverRoot: "/"
plugin:
passDeviceSpecs: false
deviceListStrategy: envvar
deviceIDStrategy: uuid
shared_gpu: |-
version: v1
flags:
migStrategy: "none"
failOnInitError: true
nvidiaDriverRoot: "/"
plugin:
passDeviceSpecs: false
deviceListStrategy: envvar
deviceIDStrategy: uuid
sharing:
timeSlicing:
renameByDefault: false
resources:
- name: nvidia.com/gpu
replicas: 10
nodeSelector:
jina.ai/gpu-type: nvidiaRun the below command to install NVIDIA’s k8s plugin:
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm upgrade -i nvdp nvdp/nvidia-device-plugin \ --namespace nvidia-device-plugin \ --create-namespace -f nvdp.yaml
Deploy user application
Third, deploy the user application with nodeSelector and toleration.
kind: Deployment
apiVersion: apps/v1
metadata:
name: test-gpu
labels:
app: gpu
spec:
replicas: 1
selector:
matchLabels:
app: gpu
template:
metadata:
labels:
app: gpu
spec:
nodeSelector:
jina.ai/node-type: gpu
karpenter.sh/provisioner-name: gpu
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
containers:
- name: gpu-container
image: tensorflow/tensorflow:latest-gpu
imagePullPolicy: Always
command: ["python"]
args: ["-u", "-c", "import tensorflow"]
resources:
limits:
nvidia.com/gpu: 1kind: Deployment
apiVersion: apps/v1
metadata:
name: test-gpu-shared
labels:
app: gpu-shared
spec:
replicas: 1
selector:
matchLabels:
app: gpu-shared
template:
metadata:
labels:
app: gpu-shared
spec:
nodeSelector:
jina.ai/node-type: gpu-shared
karpenter.sh/provisioner-name: gpu-shared
tolerations:
- key: nvidia.com/gpu-shared
operator: Exists
effect: NoSchedule
containers:
- name: gpu-container
image: tensorflow/tensorflow:latest-gpu
imagePullPolicy: Always
command: ["python"]
args: ["-u", "-c", "import tensorflow"]
resources:
limits:
nvidia.com/gpu: 1Validate the results
Now, if you deploy both YAML files. You will see two nodes provisioned in AWS console or you can see via use kubectl get nodes — show-labels. After the nvidia-k8s-plugin is running in each nodes, you can test in your applications.

If you like this article or want to learn more about the architecture behind Jina AI Cloud, make sure to follow us on social channels and subscribe to our blog.