Watermarking Text with Embedding Models to Protect Against Content Theft
You use our embedding models to do what? This might be the most "out-of-domain" applications of embeddings we learned at EMNLP 2024.


Sunday evening. You hit "publish" on that article you've poured your heart into all weekend. Every word, every idea - uniquely yours. A few likes trickle in. Not viral, but it's yours.
Three days later, scrolling through your feed, there it is: Your article's soul in someone else's body! They've reshuffled the words, but you know your own creation. The worst part? Their version is everywhere, viral success built on your stolen creativity. That's not the creative economy we signed up for.
The obvious solution is to put your name on your work. But let's be honest - that's also the easiest thing to remove. Can we do better? In this article, we will show you a watermarking technique using embedding models that can both sign and detect original content. This isn't just another search/RAG cliché - it leverages unique features of jina-embeddings-v3 like long-context and cross-lingual alignment to create a robust authentication system, and allows us to maintain reliable content verification across transformations such as LLM-paraphrasing or even translation.
Understanding Text Watermarks
Digital watermarks have been a cornerstone of content protection for years. When you found a meme with a semi-transparent logo overlaid on it, you're seeing the most basic form of image watermarking. Modern watermarking techniques have evolved far beyond simple visual overlays – many are now imperceptible to human viewers while remaining machine-readable.
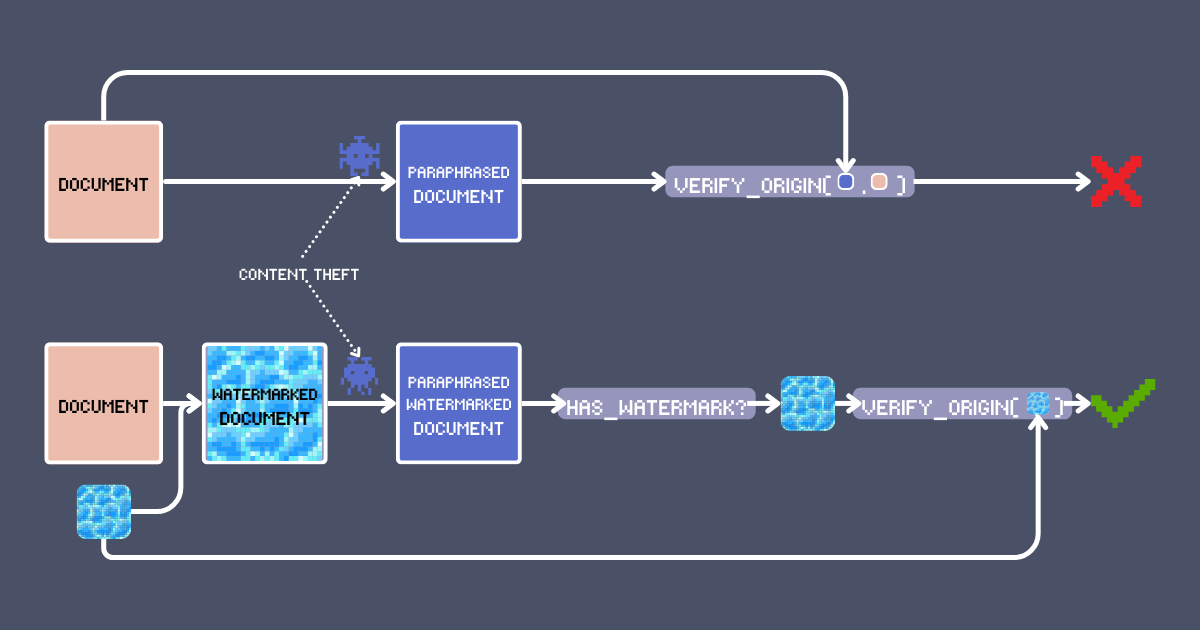
Text watermarking follows similar principles but operates in the semantic space. Instead of altering pixels, a text watermark subtly modifies the content in ways that preserve the original meaning while embedding a detectable signature. So the key requirements for an effective text watermark are:
- Semantic preservation: The watermarked text should maintain its original meaning and readability, just as a visual watermark shouldn't obscure the key elements of an image.
- Imperceptibility: The watermark should be unnoticeable to human readers, ensuring they cannot intentionally preserve or remove it during content transformation.
- Machine-detectable: While the watermark might be subtle to human readers, it should create clear, measurable patterns that algorithms can reliably identify.
- Transform-invariant: Any content transformation (like paraphrasing or translation), whether intentional or unaware of the watermark's existence, should either preserve the watermark or require such substantial changes that it fundamentally alters the original content's structure or meaning.
Using Embeddings for Text Watermarking
Let's build a text watermarking system using embeddings. First, let's define the key components of this system:
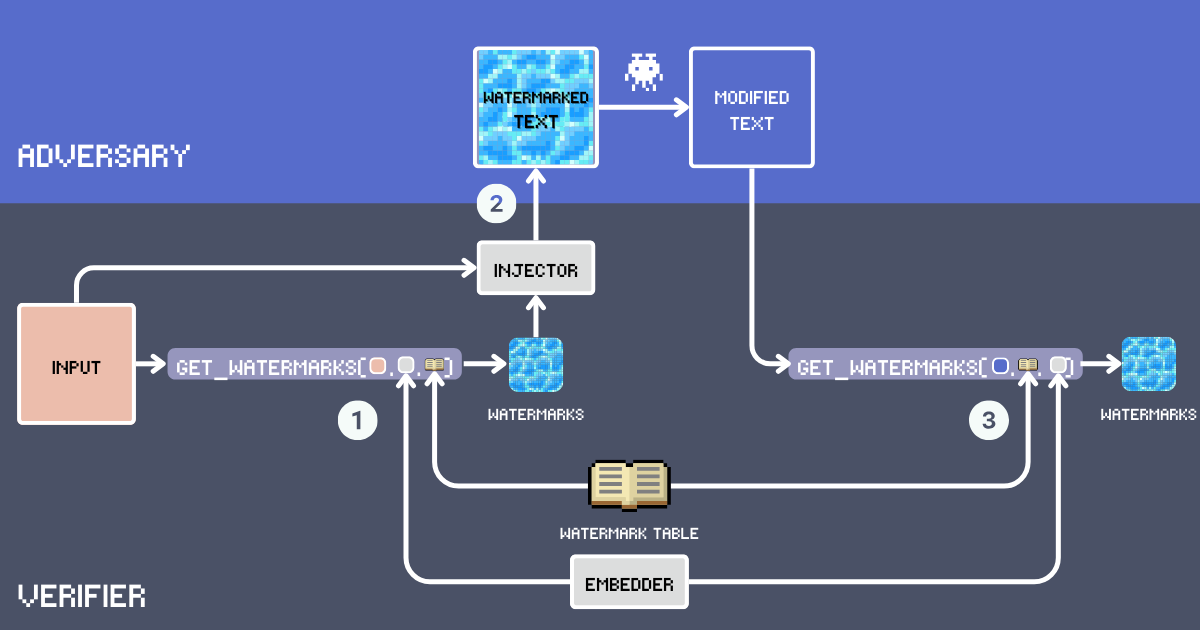
- Input: The original text to be watermarked.
- Watermark Table: A secret lexicon containing candidate watermark words. For optimal watermarking effectiveness, the words should be common enough to naturally fit in various contexts. The vocabulary excludes function words, proper nouns, and rare words that might appear out of place, e.g.
delve into,embarkare good candidates whereasgoodis just too common. Below, we will build our WatermarkTable using words from advanced English vocabulary. - Embedder: An embedding model that serves two purposes: it selects semantically appropriate words from the
WatermarkTablebased on theinputtext and helps detect watermarks in potentially paraphrased text. We're usingjina-embeddings-v3because it handles both super long texts and different languages really well. This means we can watermark lengthy documents and still catch copycats even if they translate the text. - Watermarks: Words selected from the WatermarkTable by computing cosine similarity between the input text embedding and the embeddings in the table. The number of words is determined by an insertion ratio, typically 12% of the input word count.
- Injector: An instruction-following LLM that integrates the watermark words into the input text while maintaining coherence, factual accuracy, natural flow, and even distribution of watermark words throughout the text.
- Watermarked Text: The output after the Injector inserts the watermark words into the
input. - Adversary (Content Theft): An entity who attempts to repurpose the watermarked text without attribution, typically through paraphrasing, translation, or minor edits. Today, this simply means using an LLM prompted with
Paraphrase [text]for automated rewriting. - Modified Text: The result after the adversary's modifications to the watermarked text. This is the text that we need to check for watermarks.
Algorithm
Given an Input, we first select watermarks through a selection function that identifies words from our Watermark Table that are semantically similar to the input. This selection uses our Embedder to compute similarity scores. Once we have our Watermarks, we use the Injector to seamlessly integrate them into the input text, creating the Watermarked Text.
For detection, we follow a similar process: we analyze the potentially Modified Text to find words that are semantically similar to those in our Watermark Table. We then compare these extracted watermarks with the original watermarks we inserted. If there is substantial overlap between these two sets of watermarks, we can conclude that the text in question was derived from our watermarked original.
Note that the Input, WatermarkTable, Embedder, and Injector must remain confidential. The adversary should only have access to the Watermarked Text.
Implementation

The full implementation can be found in the link above. This code demonstrates a simplified implementation of text watermarking, serving as a proof-of-concept.
This code provides a proof-of-concept for text watermarking using semantic embeddings. The implementation starts with a small, pre-defined vocabulary of about 60 advanced English words we found from English learning websites as potential watermarks and uses jina-embeddings-v3 for semantic relations.

For the injector, we use gpt4o with this prompt:
Please insert [words] into [section] while maintaining maximum coherence and preserving as much of the original content as possible.
To simulate the adversary's paraphrasing and translation operations, we use gpt4o with these respective prompts:
Paraphrase [section]
Translate [section] into Chinese
Of course, the attack simulations are simplified versions of what might happen in reality. All three LLM generation services leverage PromptPerfect's "prompt-as-a-service" feature.
The watermark selection process finds words from the watermark table that are semantically similar to the input text using cosine similarity, visualizes this distribution, and picks the top 3 most similar words as watermarks.
Qualitative Analysis
We use the company introduction as the input:
Founded in 2020 in Berlin, Jina AI is a leading search AI company. The future of AI is multimodal,
and we are part of it. We recognize that businesses face challenges in leveraging multimodal data.
In response, we provide the Search Foundation, the core infrastructure for GenAI and multimodal applications.
Our mission is to help businesses and developers unlock the value of multimodal data through better search.The original input
Based on jina-embeddings-v3 and the watermark table we defined, the three selected watermarks are: adjoining, Open-minded, inquisitive.

jina-embeddings-v3. The vertical dotted and dashed lines indicate the mean and median similarities respectively, while the white dots highlight the top 3 most similar words that were selected as watermarks.After the Injector, we get the following watermarked text:
Founded in 2020 in Berlin, Jina AI is a leading search AI company. The future of AI is multimodal, and we are part of it. We recognize that businesses face challenges in leveraging multimodal data. In response, we provide the Search Foundation, the core infrastructure for GenAI and multimodal applications. Our mission is to help businesses and developers unlock the value of multimodal data through better search. Adjoining our technical expertise is our open-minded and inquisitive approach, which drives our continuous innovation and commitment to solving complex problems.
Injecting watermarks (adjoining, Open-minded, inquisitive) into the original text
After the adversary's paraphrasing, we obtain this modified text:
Established in Berlin in 2020, Jina AI is a prominent company specializing in search AI. Our team is characterized by our open-mindedness and curiosity, consistently aiming to expand the capabilities of AI. Believing that the future of AI lies in its multimodal potential, we are excited to be at the forefront of this evolution. We understand the interconnected challenges businesses encounter when utilizing multimodal data. To address these, we offer the Search Foundation, essential infrastructure for Generative AI (GenAI) and multimodal applications. Our goal is to assist businesses and developers in unlocking the full potential of multimodal data through enhanced search capabilities.
The top three watermarks extracted from this text are:
adjoining: 0.300
Open-minded: 0.287
inquisitive: 0.278
These match our original watermark set perfectly, confirming that this text is derived from the original input.
Similarly, when we analyze the Chinese translation of the watermarked text:
成立于2020年,Jina AI是一家领先的搜索AI公司。我们是一个开放且好奇心强的团队,始终努力突破AI的界限。AI的未来是多模态的,我们很自豪能够成为其中的一部分。我们意识到企业在利用多模态数据时会面临相邻的挑战。为此,我们提供Search Foundation,这是GenAI和多模态应用的核心基础设施。我们的使命是通过更好的搜索,帮助企业和开发者释放多模态数据的价值。
The top three watermarks extracted from this text are:
adjoining: 0.413
forthcoming: 0.380
Open-minded: 0.379
Two out of three extracted watermarks are from our original watermark table, showing that this translation is very likely derived from the original input.
Let's try a slightly more challenging example by using Chapter 1, "Down the Rabbit-Hole," from Alice's Adventures in Wonderland, a 2010-token text, as our input text and repeat the watermarking process.

inquisitive, Deep-seated, Two-year-old

Conclusion
From these examples, we can see our embedding-based watermarking is quite robust even with this basic setup. What's particularly noteworthy is that the watermarks remain detectable even after translation. This robustness across languages is made possible by the powerful multilingual capabilities of the jina-embeddings-v3 model; without strong multilingual and cross-lingual abilities, such persistence through translation would not be achievable.
There are several ways to improve the accuracy and robustness of this watermarking system. First, the watermark table could be expanded and carefully constructed to ensure diversity. This is important because a larger, more diverse vocabulary provides better coverage of semantic spaces, making it easier to find contextually appropriate watermarks for any given text while reducing the risk of repetitive or obvious patterns.
The Injector component could be improved by implementing more sophisticated insertion strategies. For example, it could be instructed to distribute watermarks uniformly throughout the text to maintain imperceptibility. Additionally, we could employ the late chunking technique to generate watermarks for individual segments or sentences, allowing the Injector to make more nuanced decisions about watermark placement. This would help maintain both overall imperceptibility and semantic coherence in the final text.
For readers interested in a deeper exploration, "POSTMARK: A Robust Blackbox Watermark for Large Language Models" (Chang et al., EMNLP 2024) presents a comprehensive framework including mathematical formulations and extensive experiments. The authors systematically explore watermark vocabulary construction, optimal insertion strategies, and robustness against various attacks. They also thoroughly analyze the trade-off between watermark detection and text quality through both automated and human evaluation.