What We Learned at ICML2024 ft. PLaG, XRM, tinyBenchmark, MagicLens, Prompt Sketching etc.
We had a blast at ICML 2024 in Vienna, and we want to share with you everything we said, saw, and learned.





The International Conference on Machine Learning is one of the most prestigious conferences in the machine learning and artificial intelligence community and held its 2024 meeting in Vienna from 21 to 27 July this year.

The conference was a 7-day intensive learning experience, with oral presentations and opportunities to exchange ideas directly with other researchers. There is a great deal of interesting work going on in reinforcement learning, AI for the life sciences, representation learning, multi-modal models, and of course in core elements of AI model development. Of particular importance was the tutorial on the Physics of Large Language Models, which extensively explored the inner workings of LLMs and offered convincing answers to the question of whether LLMs memorize information or apply reasoning when saying things.
Our Work on Jina-CLIP-v1
We gave a poster presentation of the work behind our new multi-modal model jina-clip-v1 as part of the workshop Multi-modal Foundation Models meet Embodied AI.
Meeting and discussing our work with international colleagues working in many fields was very inspiring. Our presentation enjoyed lots of positive feedback, with many people interested in the way Jina CLIP unifies multi-modal and uni-modal contrastive learning paradigms. Discussions ranged from the limitations of the CLIP architecture to extensions to additional modalities all the way to applications in peptide and protein matching.
Michael Günther presents Jina CLIP
Our Favorites
We had the opportunity to discuss a lot of other researchers’ projects and presentations, and here are a few of our favorites:
Plan Like a Graph (PLaG)
Many people know "Few-Shot Prompting" or "Chain of Thought prompting". Fangru Lin presented a new and better method was presented at ICML: Plan Like a Graph (PLaG).
Her idea is simple: A task given to an LLM is decomposed into sub-tasks that an LLM can solve either in parallel or sequentially. These sub-tasks form an execution graph. Executing the whole graph solves the high-level task.
In the video above, Fangru Lin explains the method using an easily understandable example. Note that even though this improves your results, LLMs still suffer from drastic degradation when task complexity increases. That said, it’s still a great step in the right direction and provides immediate practical benefits.
For us, it's interesting to see how her work parallels our prompt applications at Jina AI. We have already implemented a graph-like prompt structure, however, dynamically generating an execution graph as she had is a new direction that we’ll explore.
Discovering Environments with XRM
This paper presents a simple algorithm to discover training environments that can cause a model to rely on features that correlate with the labels but do not induce an accurate classification/relevancy. A famous example is the waterbirds dataset (see arXiv:1911.08731), which contains photos of birds against different backgrounds that should be classified as either waterbirds or landbirds. During training, the classifier detects whether the background in the images shows water or not instead of relying on the features of the birds themselves. Such a model will misclassify waterbirds if there is no water in the background.
To mitigate this behavior, one needs to detect samples where the model relies on misleading background features. This paper presents the XRM algorithm to do this.
The algorithm trains two models on two distinct parts of the training dataset. During training, the labels of some samples get flipped. Specifically, this happens if the other model (which is not trained on the respective sample) classifies a sample differently. In this way, the models are encouraged to rely on spurious correlations. Afterward, you can extract samples from the training data where a label predicted by one of the models differs from the ground truth. Later on, one can use this information to train more robust classification models, for example, with the Group DRO algorithm.
Cut Your LLM Evaluation Costs by a Factor of 140!
Yes, you heard right. With this one trick, the cost of LLM Evaluation can be reduced to a tiny fraction.
The core idea is simple: Remove all evaluation samples that test the same model capability. The math behind it is less straightforward but well explained by Felipe Maia Polo who presented his work during the poster session. Note that the reduction by a factor of 140 applies to the popular MMLU dataset (Massive Multitask Language Understanding). For your own evaluation datasets, it depends on how much the evaluation results of the samples correlate with each other. Maybe you can skip many samples or just a few.
Just give it a try. We'll keep you posted on how much we at Jina AI were able to reduce eval samples.
Contrasting Multiple Representations with the Multi-Marginal Matching Gap
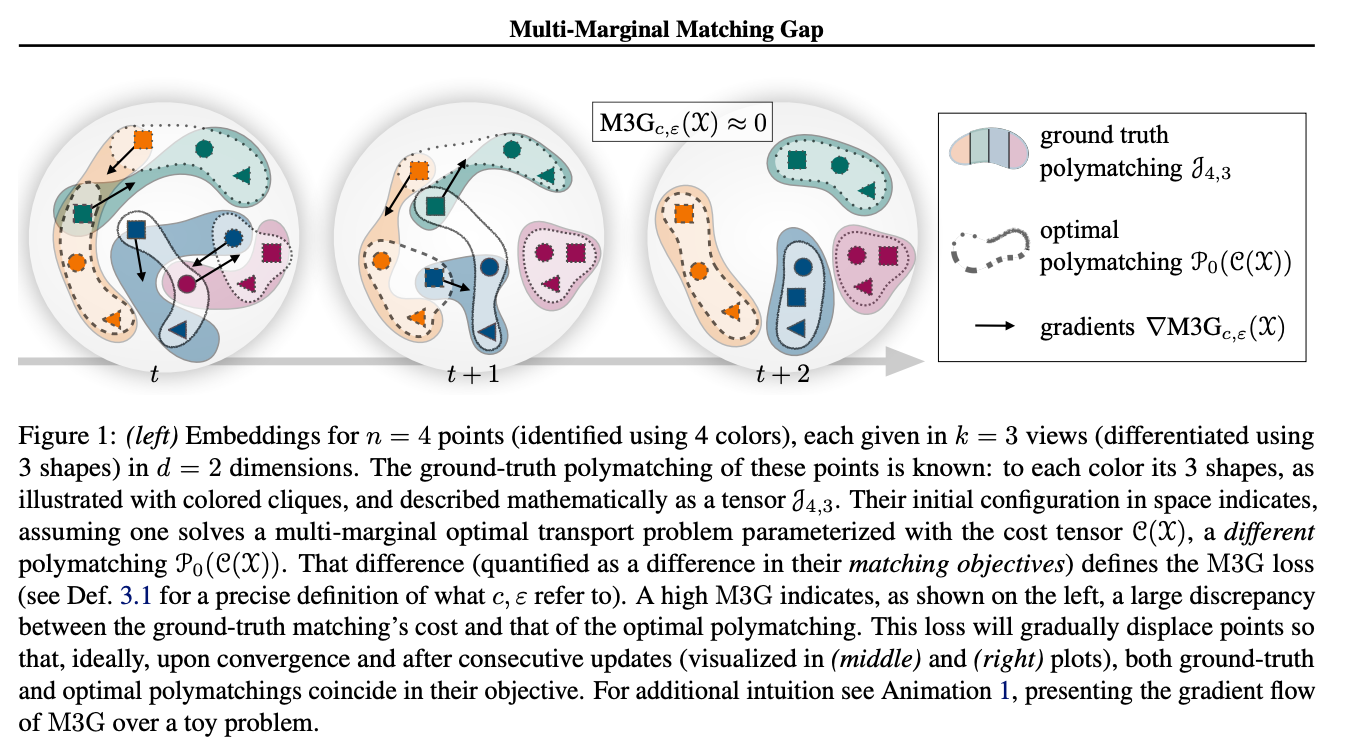
This work addresses a common challenge in contrastive learning: Most contrastive loss functions like the InfoNCE loss operate on pairs of data points and measure the distance between positive pairs. To expand on positive tuples of size k > 2, contrastive learning usually tries to reduce the problem to multiple pairs and accumulate pairwise losses for all positive pairs. The authors here propose the M3G (Multi-Marginal Matching Gap) loss, a modified version of the Sinkhorn algorithm, that solves the Multi-Marginal Optimal Transport problem. This loss function can be used in scenarios where the datasets consist of positive tuples with size k > 2, for example, >2 images of the same object, multi-modal problems with three or more modalities, or a SimCLR extension where with three or more augmentations of the same image. Empirical results show that this method outperforms the naive reduction of the problem to pairs.
No Need for Ground Truth!
Zachary Robertson from Stanford University presented his work on evaluating your LLM without any labeled data. Note that even though this is theoretical work, it has a lot of potential for scalable oversight of advanced AI systems. This isn’t for casual LLM users, but if you work on LLM evaluation it’s definitely a thing you want to look into. We can see already that we could evaluate our agents at Jina AI that way. We'll share the results once we run the first experiments.
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
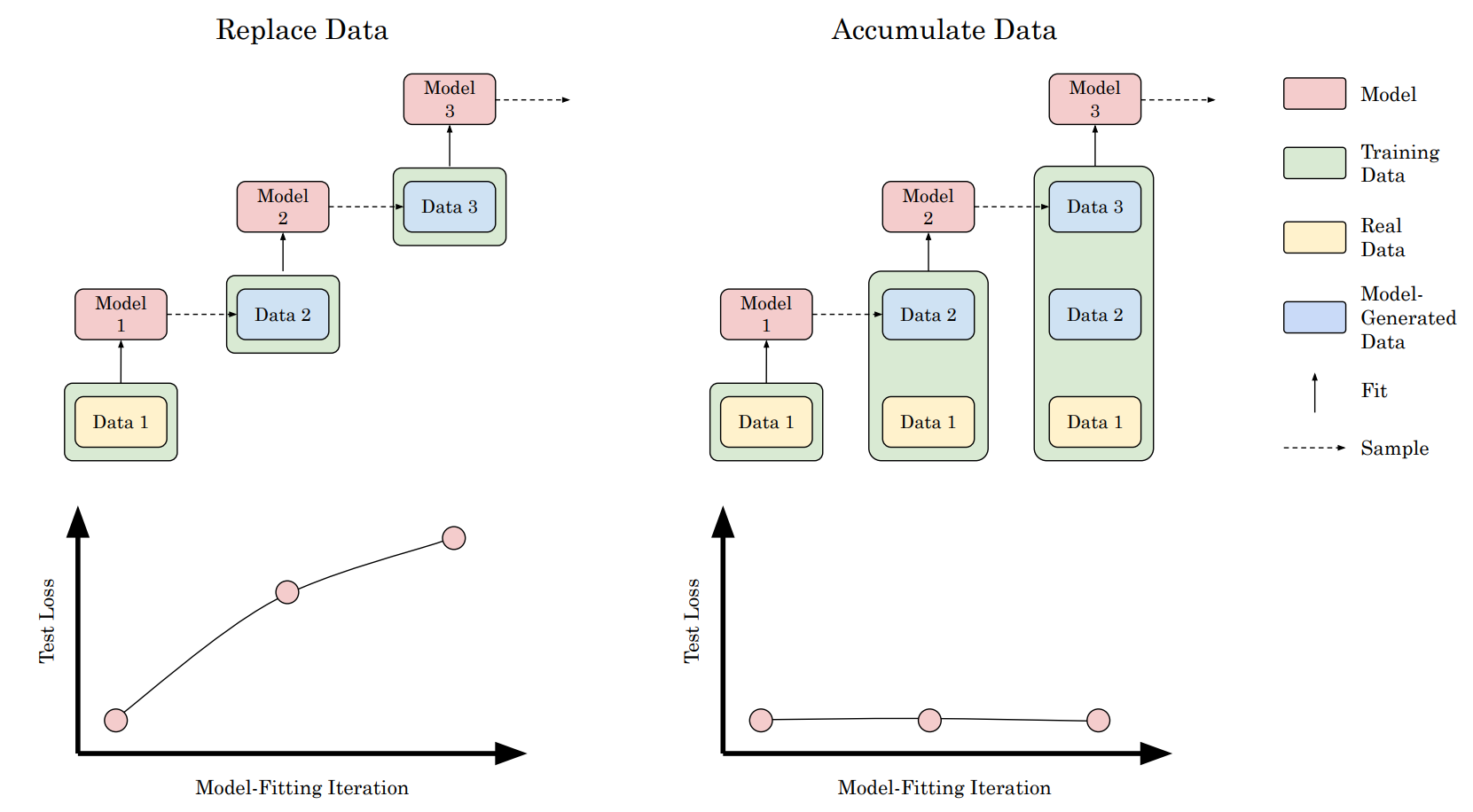
Multiple articles (like this Nature article) recently predicted that the performance of newly trained models may become worse over time because the training data is crawled from the web contains an increasingly high amount of synthetic data.
Our colleague Scott Martens has also published an article about model collapse and discussed cases where synthetic data can be useful for model training.

Model training runs might collapse because training data is produced by an earlier version of the model or a model trained on the same data. This paper runs experiments that show a slightly different picture: A collapse only happens when replacing real data with synthetic, which was done in previous experiments. However, when augmenting real data with additional synthetic data, there’s no measured change in the performance of the resulting models. These results suggest that something like model collapse won’t happen. However, it again proves that using additional synthetic data won’t help to train a model that is generally superior to the model used to create said synthetic data points.
Brain Surgery for AI Is Now Possible
Let’s say you want to predict someone’s profession but not their gender. This work from Google Research, ETH Zürich, International Institute of Information Technology Hyderabad (IIITH), and Bar-Ilan University shows how steering vectors and covariance matching can be used to control bias.
MagicLens - Self-Supervised Image Retrieval with Open-Ended Instructions

This paper presents the MagicLens models, a series of self-supervised image retrieval models trained on query image + instruction + target image triplets.
The authors introduce a data collection/curation pipeline that collects image pairs from the web and uses LLMs to synthesize open-ended text instructions that link the images with diverse semantic relations beyond mere visual similarity. This pipeline is used to produce 36.7M high-quality triplets over a wide distribution. The dataset is then used to train a simple dual-encoder architecture with shared parameters. The backbone vision and language encoders are initialized with either CoCa or CLIP base and large variants. A single multi-head attention pooler is introduced, to compress the two multi-modal inputs into a single embedding. The training objective contrasts the query-image and instruction pair with the target-image and the empty string instruction with a simple InfoNCE loss to train MagicLens. The authors present evaluation results on instruction-based image retrieval.
Prompt Sketching - The New Way of Prompting
The way we prompt LLMs is changing. Prompt Sketching lets us give fixed constraints to generative models. Instead of just providing an instruction and hoping that the model will do what you want, you define a complete template, forcing the model to generate what you want.
Don’t confuse this with LLMs fine-tuned to provide a structured JSON format. With the fine-tuning approach, the model still has the freedom to generate whatever it wants. Not so with Prompt Sketching. It provides a completely new toolbox for prompt engineers and opens up research areas that need to be explored. In the video above, Mark Müller explains in detail what this new paradigm is about.
You can also check out their open-source project LMQL.
Repoformer - Selective Retrieval for Repository-Level Code Completion
For many queries, RAG doesn’t really help the model because the query is either too easy or the retrieval system can’t find relevant documents, possibly because there are none. This leads to longer generation times and lower performance if the model relies on misleading or absent sources.
This paper addresses the problem by enabling LLMs to self-evaluate whether retrieval is useful. They demonstrate this approach on a code completion model that is trained to fill in a gap in a code template. For a given template, the system first decides whether retrieval results are useful and, if so, calls for the retriever. Finally, the code LLM generates the missing context whether or not retrieval results are added to its prompt.
The Platonic Representation Hypothesis

The Platonic Representation Hypothesis argues that neural network models will tend to converge to a common representation of the world. Borrowing from Plato's Theory of Forms the idea that there exists a realm of “ideals”, which appears to us in a distorted form that we can only observe indirectly, the authors claim that our AI models seem to converge on a single representation of reality, regardless of training architecture, training data, or even input modality. The larger the data scale and the model size, the more similar their representations seem to get.
The authors consider vector representations and measure representation alignment using kernel alignment metrics, specifically a mutual nearest-neighbor metric that measures the mean intersection of the k-nearest neighbor sets induced by two kernels, K1 and K2, normalized by k. This work presents empirical evidence that as model and dataset sizes grow and performance improves, the more aligned the kernels become. This alignment can also be observed even when comparing models of different modalities, like text models and image models.
Summary
Some of the initial enthusiasm that came with the scaling-law is beginning to wane, but ICML 2024 has demonstrated that so much new, diverse, creative talent has entered our field that we can be sure progress is far from over.
We had a blast at ICML 2024 and you can bet that we’ll be back in 2025 🇨🇦.