When AI Makes AI: Synthetic Data, Model Distillation, And Model Collapse
AI creating AI! Is it the end of the world? Or just another tool to make models do value-adding work? Let’s find out!


Talk about AI is often apocalyptic. Some of the blame belongs to the way apocalyptic science fiction has created our mental picture of artificial intelligence. Visions of smart machines that can make more machines have been a common trope in science fiction for generations.
Plenty of people have been vocal about existential risks from recent developments in AI, many of them business leaders involved in commercializing AI, and even a few scientists and researchers. It’s become a component of AI hype: Something powerful enough to make sober-seeming icons of science and industry contemplate the end of the world must surely be powerful enough to turn a profit, right?
So, should we be worried about existential risks from AI? Do we need to fear that Sam Altman will make Ultron out of ChatGPT and have its AI army throw Eastern European cities at us? Should we be concerned about Peter Thiel’s Palantir building Skynet and sending robots with inexplicable Austrian accents back in time to kill us?
Probably not. Industry leaders have yet to identify any clear way to make AI pay its own bills, much less disrupt industries, and even less threaten humanity at a level comparable to climate change or nuclear arms.
The AI models we actually have are hardly up to wiping out humanity. They struggle to draw hands, can’t count more than three things, think it's okay to sell people cheese that rats have nibbled on, and perform Catholic baptisms with Gatorade. The mundane, non-existential risks of AI — the way the technology can help misinform, harass, generate spam, and be poorly used by people who are unclear about its limitations — are worrying enough.
But one existential risk from artificial intelligence is definitely legitimate: AI poses a clear and present danger to… AI.
This fear is usually called “model collapse” and it’s received strong empirical demonstration in Shumailov et al. (2023) and Alemohammad et al. (2023). The idea is simple: If you train AI models from AI-generated data, then take the resulting AI and use its output to train another model, repeating the process over multiple generations, the AI will get objectively worse and worse. It’s like taking a photocopy of a photocopy of a photocopy.

There’s been some discussion of model collapse lately, and press headlines are appearing about AI running out of data. If the Internet becomes full of AI-generated data, and human-made data becomes harder to identify and use, then, before long, AI models will run into a quality ceiling.
At the same time, there’s growing use of synthetic data and model distillation techniques in AI development. Both consist of training AI models at least in part on the output of other AI models. These two trends seem to contradict each other.
Things are a little more complicated than that. Will generative AI spam up the works and stifle its own progress? Or will AI help us make better AI? Or both?
We’ll try to get some answers in this article.
Model Collapse
As much as we love Alemohammad et al. for inventing the term “Model Autophagy Disorder (MAD)”, “model collapse” is much catchier and doesn’t involve Greek words for self-cannibalism. The metaphor of making photocopies of photocopies communicates the problem in simple terms, but there is a bit more to the underlying theory.
Training an AI model is a type of statistical modeling, an extension of what statisticians and data scientists have been doing for a long time. But, on Day One of data science class, you learn the data scientist’s motto:
All models are wrong, but some are useful.
This quote, attributed to George Box, is the flashing red light that should be on top of every AI model. You can always make a statistical model for any data, and that model will always give you an answer, but absolutely nothing guarantees that that answer is right or even close to right.
A statistical model is an approximation of something. Its outputs may be useful, they might even be good enough, but they are still approximations. Even if you have a well-validated model that, on average, is very accurate, it can and probably will still make big mistakes sometimes.
AI models inherit all the problems of statistical modeling. Anyone who’s played with ChatGPT or any other large AI model has seen it make mistakes.
So, if an AI model is an approximation of something real, an AI model trained on output from another AI model is an approximation of an approximation. The errors accumulate, and it inherently has to be a less correct model than the model it was trained from.
Alemohammad et al. show that you can’t fix the problem by adding some of the original training data to the AI output before training the new “child” model. That only slows model collapse, it can’t stop it. Unless you introduce enough new, previously unseen, real-world data whenever training with AI output, model collapse is inevitable.
How much new data is enough depends on difficult-to-predict, case-specific factors, but more new, real data and less AI-generated data is always better than the opposite.
And that’s a problem because all the readily accessible sources of fresh human-made data are already tapped out while the amount of AI-generated image and text data out there is growing by leaps and bounds. The ratio of human-made to AI-made content on the Internet is falling, possibly falling fast. There is no reliable way to automatically detect AI-generated data and many researchers believe there can’t be one. Public access to AI image and text generation models ensures that this problem will grow, probably grow dramatically, and has no obvious solution.
The amount of machine translation on the Internet might mean it’s already too late. Machine-translated text on the Internet has been polluting our data sources for years, since long before the generative AI revolution. According to Thompson, et al., 2024, possibly half of the text on the Internet may be translated from another language, and a very large share of those translations are of poor quality and show signs of machine generation. This can distort a language model trained from such data.
As an example, below is a screenshot of a page from the website Die Welt der Habsburger showing clear evidence of machine translation. “Hamster buying” is an over-literal translation of the German word hamstern, meaning to hoard, or panic-buying. Too many instances of this will lead an AI model to think “hamster buying” is a real thing in English and that the German hamstern has something to do with pet hamsters.

In almost every case, having more AI output in your training data is bad. The almost is important, and we’ll discuss two exceptions below.
Synthetic Data
Synthetic data is AI training or evaluation data that has been generated artificially rather than found in the real world. Nikolenko (2021) dates synthetic data back to early computer vision projects in the 1960s and outlines its history as an important element of that field.
There are a lot of reasons to use synthetic data. One of the biggest is to combat bias.
Large language models and image generators have received a lot of high-profile complaints about bias. The word bias has a strict meaning in statistics, but these complaints often reflect moral, social, and political considerations that have no simple mathematical form or engineering solution.
The bias you don’t easily see is far more damaging and much harder to fix. The patterns AI models learn to replicate are the ones seen in their training data, and where that data has systematic shortcomings, bias is an inevitable consequence. The more different things we expect AI to do — the more diverse the inputs to the model — the more chance there is for it to get something wrong because it never saw enough similar cases in its training.
The main role of synthetic data in AI training today is to ensure enough examples of certain kinds of situations are present in the training data, situations that may not be present enough in available natural data.
Below is an image that MidJourney produced when prompted with “doctor”: four men, three white, three in white coats with stethoscopes, and one genuinely old. This is not reflective of the actual race, age, gender, or dress of real doctors in most countries and contexts, but is likely reflective of the labeled images one finds on the Internet.

When prompted again, it produced one woman and three men, all white, although one is a cartoon. AI can be weird.

This particular source of bias is one that AI image generators have been trying to prevent, so we no longer get as clearly biased results as we did perhaps a year ago from the same systems. A bias is visibly still present, but it's not obvious what an unbiased result would look like.
Still, it’s not hard to figure out how an AI could acquire these kinds of prejudices. Below are the first three images found for “doctor” on the Shutterstock photo website: Three men, two older and white. AI’s biases are the biases of its training, and if you train models using uncurated data, you will always find these kinds of biases.
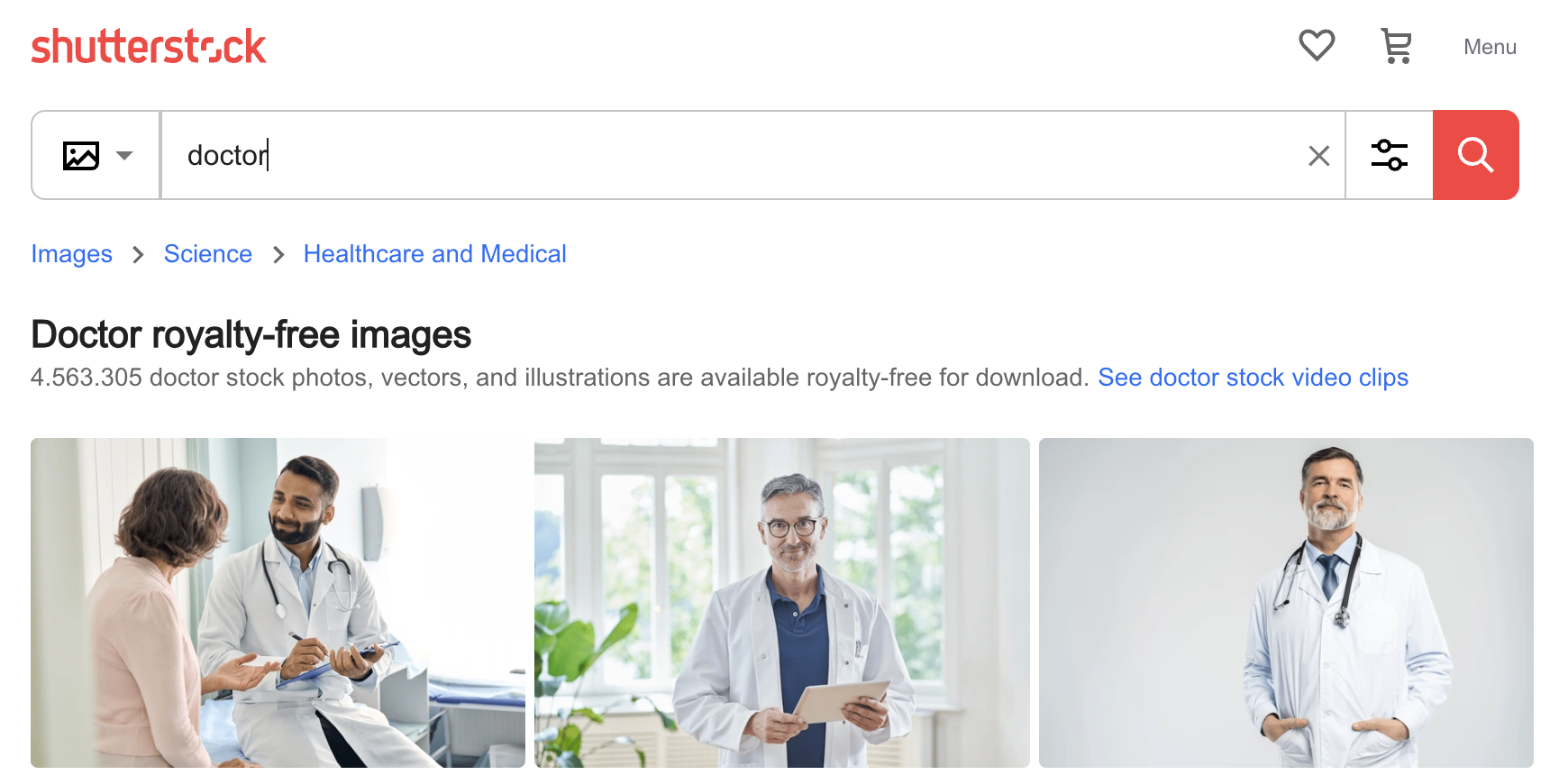
One way to mitigate this problem is to use an AI image generator to create images of younger doctors, women doctors, doctors who are people of color, and doctors wearing scrubs, suits, or other clothing, and then include them in training. Synthetic data used in this way can improve AI model performance, at least relative to some external norm, instead of leading to model collapse. However, artificially distorting training data distributions can create unintended side effects, as Google recently found out.
Model Distillation
Model distillation is a technique for training one model directly from another one. A trained generative model — the “teacher” — creates as much data as needed to train an untrained or less-trained “student” model.
As you would expect, the “student” model can never be better than the “teacher”. At first glance, it makes little sense to train a model that way, but there are benefits. The principal one is that the “student” model may be much smaller, faster, or more efficient than the “teacher”, while still closely approximating its performance.
The relationship between model size, training data, and final performance is complicated. However, on the whole, all else being equal:
- A bigger model performs better than a small one.
- A model trained with more or better training data (or at least more diverse training data) performs better than one trained with less or poorer data.
This means that a small model can, sometimes, perform as well as a large one. For example, jina-embeddings-v2-base-en significantly out-performs many much larger models on standard benchmarks:
| Model | Size in parameters | MTEB average score |
|---|---|---|
jina-embeddings-v2-base-en |
137M | 60.38 |
multilingual-e5-base |
278M | 59.45 |
sentence-t5-xl |
1240M | 57.87 |
Model distillation is a way to take a large model, one that costs too much to run, and use it to create a smaller, cheaper model. In every case, there is some performance loss, but in the best cases, it can be very small.
Given the costs associated with very large AI models, these benefits are quite substantial. Distillation makes models that run faster, on cheaper chips, with less memory, consuming less power.
Furthermore, large models can learn remarkably subtle patterns from uncurated data, patterns that a smaller model could never learn from the same data. A large model can then produce far more diverse training data than what it was trained with, enough that the smaller model may be able to learn the same subtle patterns. Once you have a large trained model, you can use it to “teach” what it’s learned to a smaller model that could never have learned it alone. Distillation is, in those cases, sometimes a better way to learn than using real training data.
So Are We All Going to Hell in a Handbasket?
Maybe.
The good news is that without a solution to model collapse, we probably won’t be able to train a superintelligent AI able to kill off humanity, at least not with the methods we’ve been using. We can safely go back to worrying about climate change and nuclear war.
For the AI industry, the picture is not quite as upbeat. The motto of machine learning has long been “more data is better data.” (Sometimes: “There is no data like more data.”) Statisticians all know this wrong. Common sense says this is wrong. But it’s a strategy that's been working for AI researchers for a long time, at least since I started as a researcher in machine translation in the early 2000s.
There are reasons for this. Diverse data — data that includes many different possibilities — is a much better training source than uniform data. And, in practice, in the real world, more data usually means more diverse data.
But we’re running out of new sources of good, diverse data, and the creation of new human-made works is unlikely to keep up with AI generation. One way or another, we will eventually have to change how we do AI model training. Otherwise, we may reach a performance threshold that we can’t beat anymore. This would transform the industry since the focus would shift from building and running larger, more expensive models to developing frameworks, contexts, and niches in which existing models can bring new added value.
How Jina AI Trains its AI Models
At Jina AI, we try to bring our users the benefits of AI best practices. Although we don’t produce text-generating LLMs or AI image generators, we’re still concerned with the problem of model collapse. We use subsets of the Common Crawl for the bulk of our pre-training and then use curated and synthetic data to optimize the performance of our models. We strive to bring state-of-the-art performance to cost-effective models and compact, low-dimensional embeddings.
Nonetheless, model collapse is an inevitable problem for Common Crawl data. We expect to transition over time to using more curated data and less of the Common Crawl. We expect that other AI industry players will do the same. This will have costs — both in terms of money and rate of quality improvement — but it’s too early to try to estimate them.
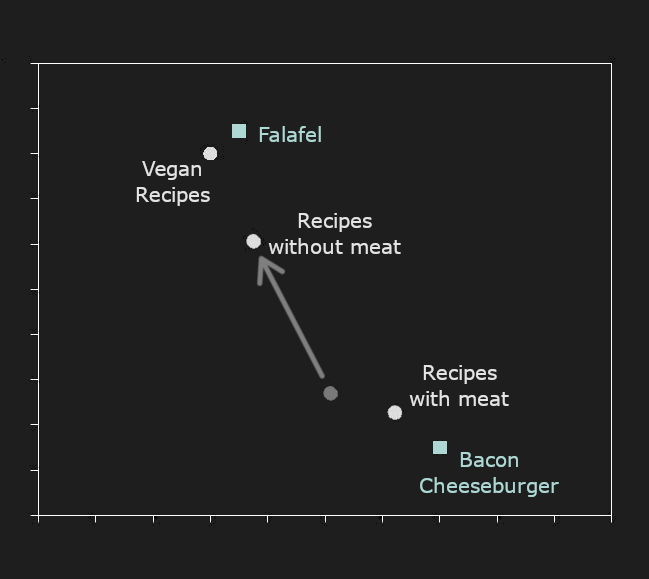
We use synthetic data in areas where embedding models have known problems. For example, AI models struggle to represent negation. “Recipes with meat” and “recipes without meat” typically have embeddings that are very close together, but users often need them to be very far apart. Our biggest use of synthetic data is creating a large corpus of AI-generated sentence pairs distinguished by that kind of negation (called polarity in AI and some kinds of linguistics), and then using it to improve our models.
For example, below is a 2D projection of hypothetical embeddings. “Recipes with meat” and “Recipes without meat” are relatively close together. “Bacon Cheeseburger” is much closer to “Recipes with meat” than to anything else, and “Falafel” is closer to “Recipes without meat” than to “Recipes with meat.” However, “Bacon Cheeseburger” is much closer to “Recipes without meat” than “Falafel” is.

Looking solely at the embeddings, we might conclude that bacon cheeseburgers are a better example of a recipe without meat than falafel.
To prevent this, we train our models with synthetic data. We use an LLM to generate pairs of sentences with opposite polarities – like “X with Y” / ”X without Y” – and train our embedding models to move those pairs apart. We also use synthetic data for other kinds of focused negative mining, a collection of techniques used to improve specific aspects of AI model performance by presenting it with curated data.
We also use generative AI to train embedding models for programming languages, taking advantage of large models that generate copious code examples, so that we can correctly embed even fairly obscure features of specific languages and frameworks.
Model distillation is key to how we produce compact models that save computer resources. Distillation is a lot more efficient and reliable than training from scratch, and our results show that a distilled model can still have top-quality performance. The table below shows Jina AI’s distilled reranker models compared to the base reranker used to train them and to other models with far more parameters but poorer performance.
| Model | BEIR Score | Parameter count | |
|---|---|---|---|
jina-reranker-v1-base-en |
52.45 | 137M | |
| Distilled | jina-reranker-v1-turbo-en |
49.60 | 38M |
| Distilled | jina-reranker-v1-tiny-en |
48.54 | 33M |
mxbai-rerank-base-v1 |
49.19 | 184M | |
mxbai-rerank-xsmall-v1 |
48.80 | 71M | |
bge-reranker-base |
47.89 | 278M |
We know AI can be an expensive investment and that enterprises are increasingly conscious of their moral and legal obligations to reduce carbon emissions. We’re conscious of those things too. Model distillation is a big part of how we address those concerns.
Let Us Help You Navigate AI
Jina AI is committed to bringing enterprises affordable, efficient, working AI solutions. We can integrate with your existing cloud infrastructure on Azure and AWS. We provide web APIs that uphold strict standards of security and privacy and don’t keep your data for our own training. We can help you install our open-source models on your own hardware, keeping your entire operation in-house.
It can be hard to separate the hype from the tech and stay on top of the best practices in this fast-changing field. Let us do that for you.