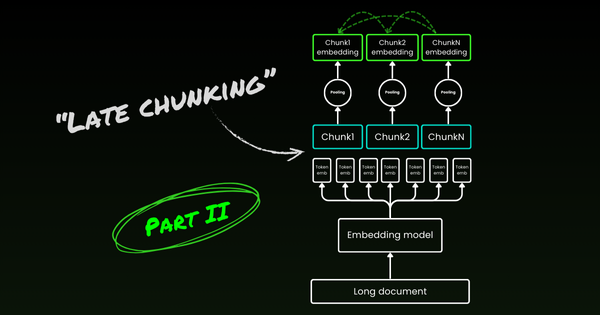
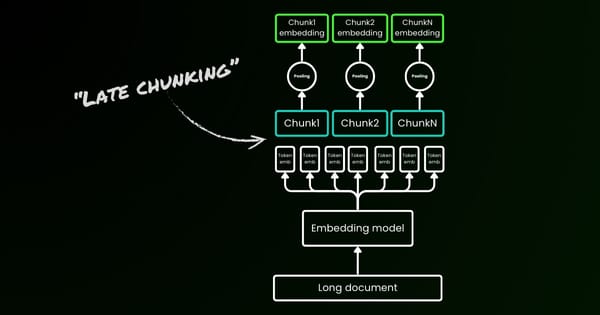
Text embedding models struggle with capturing subtle linguistic nuances like word order, directional relationships, temporal sequences, causal connections, comparisons, and negation. Understanding these challenges is key to improving model performance.